
數據結構之算法
算法
算法——對特定問題求解步驟的描述
特性: 輸入——有0個或多個輸入
輸出——有1個或多個輸出
有窮性
確定性
可行性
如何評價一個算法的好壞?
正確的
可讀性高
時間效率高
存儲空間小
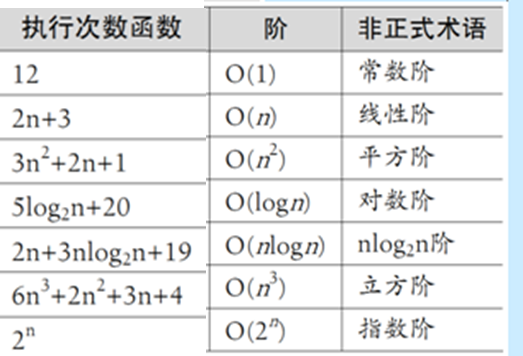
算法時間復雜度
在進行算法分析時,語句總的執行次數T(n)是關於問題規模n的函數,進而分析T(n)隨n的變化情況並確定T(n)的數量級。算法的時間復雜度,也就是算法的時間量度,記作:T(n) = O(f(n))。
它表示隨問題規模n的增大,算法執行時間的增長率和f(n)的增長率相同,稱作算法的漸近時間復雜度,簡稱為時間復雜度
推導大O階方法
1.
用常數取代運行時間中的所有加法常數。
2.
在修改後的運行次數函數中,只保留最高階項。
3.
如果最高階項存在且不是,則去除與這個項相乘的常數。得到的結果就是大O階。
常見的時間復雜度如表:

數據結構之算法
相關推薦
數據結構之算法
ges 運行 復雜度 mage 步驟 得到 求解 size 增長率 算法 算法——對特定問題求解步驟的描述 特性: 輸入——有0個或多個輸入 輸出——有1個或多個輸出 有窮性 確定性 可行性 如何評價一個算法的好壞
數據結構之算法概念
數據結構 com 轉換 根據 多項式 png .com 最終 分享圖片 數據結構:就好比一個大型圖書館,如何在書架上擺放圖書,要考慮兩個操作: 1.新書怎麽插入 2.怎麽找到指定的某本書 解決問題方法的效率,跟數據結構的組織方式有關,跟空間的利用率有關,跟算法的巧妙程度有關
數據結構和算法之:二分法demo
splay ++ ring maxsize ins 二分查找 logs bound log package com.js.ai.modules.pointwall.testxfz; class OrdArray{ private long[] a; private i
數據結構與算法之----線性表
還需要 序號 鏈式 apple 其他 前插 for循環 頭結點 end 01線性表 1.線性表的判斷方式就是元素有且只有一個直接前驅和直接後繼,元素可以為空,此時叫做空表 2.抽象數據類型標準格式 ADT 抽象數據類型名 DATA 數據
數據結構與算法之--基本概念
ant link 數據結構與算法 size 隨著 pan 提高 需要 bin 數據結構和算法各是指什麽?作用是什麽? 具體有哪些數據結構,又有哪些算法? 數據結構是數據在計算機內存或者外存中的組織方式,算法就是計算機操作數據結構中數據的方式方法,比如查找、排序。 很少有
php面試題之二——數據結構和算法(高級部分)
ash item name queue lis 雙向 joseph test 數據結構和算法 二、數據結構和算法 1.使對象可以像數組一樣進行foreach循環,要求屬性必須是私有。(Iterator模式的PHP5實現,寫一類實現Iterator接口)(騰訊) <?
java 數據結構與算法 之查找法
二分查找 strong div 變化 算法 color 折半查找 code else 一、二分查找法 二分查找就是將查找的鍵和子數組的中間鍵作比較,如果被查找的鍵小於中間鍵,就在左子數組繼續查找;如果大於中間鍵,就在右子數組中查找,否則中間鍵就是要找的元素。 @Test
數據結構和算法之排序六:希爾排序
style 發展 思想 希爾 發現 冒泡 縮小 pre mage 經過前面五篇排序方法的介紹,我們了解到了遞歸思想以及分而治之的歸並和快速排序,當然也涉及到了比較簡單易懂的數據值傳遞冒泡,選擇,以及插入排序。可以說每一種排序方式都各有千秋,都適合在不同的環境下進行使用,
數據結構與算法之二分查找
第一章 二分 找不到 問題解決 如果 但我 nbsp 第一個 com 問題:如果有一個有100個元素的已經排好序的數組,然後給你一個數,讓你判斷這個數組裏面是否有這個數,你該怎樣去做? 最簡單的方法就是從數組的第一個元素開始,逐一與所給的數比較,直到
數據結構與算法之解析之路
++ blank 知識 black 復雜 根據 nbsp 教程 情況 數據結構是計算機存儲、組織數據的方式。數據結構是指相互之間存在一種或多種特定關系的數據元素的集合。通常情況下,精心選擇的數據結構可以帶來更高的運行或者存儲效率。數據結構往往同高效的檢索算法
數據結構與算法(四)-線性表之循環鏈表
log ddc 兩個 方向 http return close 單向 throw 前言:前面幾篇介紹了線性表的順序和鏈式存儲結構,其中鏈式存儲結構為單向鏈表(即一個方向的有限長度、不循環的鏈表),對於單鏈表,由於每個節點只存儲了向後的指針,到了尾部標識就停止了向後鏈的操作。
數據結構與算法學習筆記之如何分析一個排序算法?
編號 height href eight 代碼 [] www. 價值 它的 前言 現在IT這塊找工作,不會幾個算法都不好意思出門,排序算法恰巧是其中最簡單的,我接觸的第一個算法就是它,但是你知道怎麽分析一個排序算法麽?有很多時間復雜度相同的排序算法,在實際編碼中,那又如何
數據結構和算法之——二分查找上
clas 算法實現 字符 我會 orien 如果 元素 時間復雜度 urn 二分查找(Binary Search)的思想非常簡單,但看似越簡單的東西往往越難掌握好,想要靈活運用就更加困難。 1. 二分查找的思想? 生活中二分查找的思想無處不在。一個最常見的就是猜數遊戲,
數據結構與算法學習筆記之 適合大規模的數據排序
時間復雜度 規模 數組 輸出 數據規模 tmp nlogn lan 情況 前言 在數據排序的算法中,不同數據規模應當使用合適的排序算法才能達到最好的效果,如小規模的數據排序,可以使用冒泡排序、插入排序,選擇排序,他們的時間復雜度都為O(n2),大規模的數據排序就可以使
數據結構與算法之美專欄學習筆記-排序優化
str 原則 選擇排序 .com 實現一個函數 一個數 原因 通用 並排 選擇合適的排序算法 回顧 選擇排序算法的原則 1)線性排序時間復雜度很低但使用場景特殊,如果要寫一個通用排序函數,不能選擇線性排序。 2)為了兼顧任意規模數據的排序,一般會首選時間復雜度為O(nl
數據結構與算法之美專欄學習筆記-散列表(下)
檢查 速查 刪除 core 筆記 意思 前驅 表示 就是 散列表和鏈表組合使用 LRU緩存淘汰算法 借助散列表,我們可以把LRU緩存淘汰算法的時間復雜度降為O(1)。 一個緩沖cache系統主要包含以下操作 往緩存中添加一個數據; 從緩存中刪除一個數據; 在緩存中查找一個
數據結構與算法之美專欄學習筆記-哈希算法(上)
組裝 algorithm 數量 不同的 轉換 完全 負載 結構 快速 哈希算法的定義和原理 將任意長度的二進制串映射為固定長度的二進制串。 這個映射的規則就是哈希算法,而通過原始數據映射之後得到的二進制串就是哈希值。 設計一個優秀的哈希算法需要滿足: 從哈希值不能反向推導
數據結構與算法之美專欄學習筆記-二叉樹基礎(下)
binary 特性 child 數據大小 del delet 動態擴容 eve 怎麽 二叉查找樹 Binary Search Tree 二叉查找樹的定義 二叉查找樹又稱二叉搜索樹。其要求在二叉樹中的任意一個節點,其左子樹中的每個節點的值,都要小於這個節點的值,而右子樹的
數據結構與算法之美-堆的應用
並且 效率 先進先出 應該 成本 最短 特性 對比 查詢 堆的應用一:優先級隊列 優先級隊列首先應該是一個隊列。隊列最大的特性就是先進先出。但是在優先級隊列中,出隊順序不是先進先出,而是按照優先級來,優先級最高的,最先出隊。 用堆來實現優先級隊列是最直接、最高效的。這是因為
數據結構與算法之美-字符串匹配(上)
快速 ORC 如果 代碼實現 進制 匹配 情況下 暴力 是否 BF (Brute Force) 暴力/樸素匹配算法 主串和模式串 我們在字符串 A 中查找字符串 B,那字符串 A 就是主串,字符串 B 就是模式串。 我們把主串的長度記作 n,模式串的長度記作 m。因為我們是