
讀《Java並發編程的藝術》(二)
上篇博客開始,我們接觸了一些有關Java多線程的基本概念。這篇博客開始,我們就正式的進入了Java多線程的實戰演練了。實戰演練不僅僅是貼代碼,也會涉及到相關概念和術語的講解。
線程的狀態
程的狀態分為:新生,可運行,運行,阻塞,死亡5個狀態。如下圖:
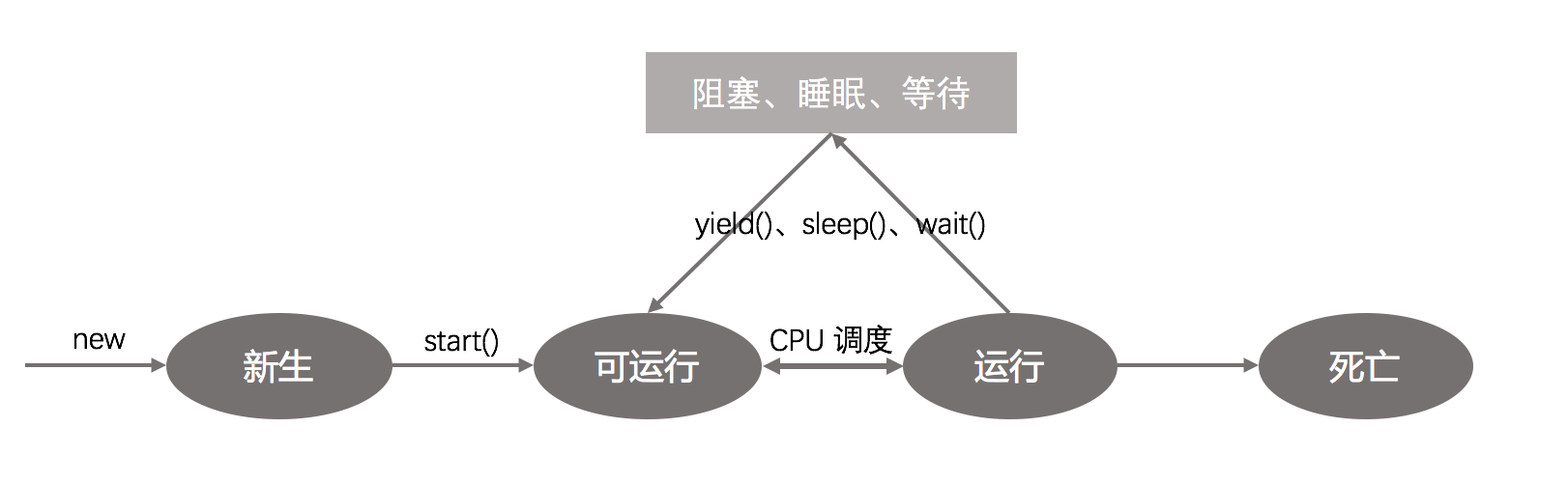
狀態說明:
- 新生(new):線程對象剛創建,但尚未啟動。
- 可運行(Runnable):線程創建完畢,並調用了start()方法,雖然調用了start(),但是並不一定意味著線程會立即執行,還需要CPU的時間調度。線程此時的狀態就是可運行狀態。
- 運行:線程等到了CPU的時間調度,此時線程狀態轉為運行狀態。
- 阻塞(Blocked):線程由於某種原因被阻礙了,但是此時線程還處於可運行狀態。調度機制可以簡單的跳過它,不給它分配任何CPU時間。
其他狀態比較簡單,阻塞狀態是其中比較有意思的。造成線程阻塞的原因有:
- 調用sleep(毫秒數),使線程進入"睡眠"狀態。在規定的毫秒數內,線程不會被執行,使用sleep()使線程進入睡眠狀態,但是此時並不會放棄所持有的鎖,其他線程此時並不能訪問被鎖住的對象。sleep()可使優先級低的線程得到執行的機會,當然也可以讓同優先級和高優先級的線程有執行的機會。
- 調用suspend()暫停線程的執行,除非收到resume()消息,否則不會返回"可運行"狀態。強烈建議不要使用這種方式。
- 用wait()暫停了線程的執行,除非線程收到notify()或者notifyAll()消息,否則不會變成"可運行"狀態。這個方法是Object類中的方法。使用wait()方法,不僅讓線程休眠,同時還暫時放棄了其所持有的鎖,如果需要使線程暫停休眠,可使用interrupt()方法。雖說wait()放棄了鎖,但是在恢復的時候,還得把鎖還回來。如何還?
- 在wait()中設置參數,比如wait(1000),以毫秒為單位,就表明只借出去1秒中,一秒鐘之後,自動收回。
- 讓借用的線程通知該線程,用完就還。這時,該線程馬上就收鎖。比如:我設了1小時之後收回,其他線程只用了半小時就完了,那怎麽辦呢?當然用完了就收回了,不用管我設的是多長時間。別的線程如何通知?就是上面說的使用notify()或者notifyAll()。
- 調用yield()方法(Thread類中的方法)自動放棄CPU,讓給其他線程。值得註意的是,該方法雖然放棄了CPU,但是還會有機會得到執行,甚至馬上。yield()只能使同優先級的線程有執行的機會。
- 線程正在等候一些IO操作。
- 線程試圖調用另一個對象的"同步"方法,但那個對象處於鎖定狀態,暫時無法使用。
下面是一個關於使用Object類中wait()和notify()方法的例子:
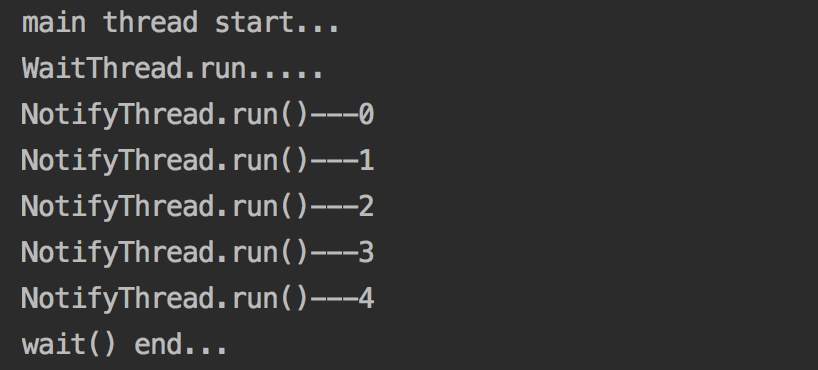
1 /** 2 * @author zhouxuanyu 3 * @date 2017/05/17 4 */ 5 public class ThreadStatus { 6 7 private String flag[] = { "true" }; 8 9 public static void main(String[] args) { 10 System.out.println("main thread start..."); 11 ThreadStatus threadStatus = new ThreadStatus(); 12 WaitThread waitThread = threadStatus.new WaitThread(); 13 NotifyThread notifyThread = threadStatus.new NotifyThread(); 14 waitThread.start(); 15 notifyThread.start(); 16 } 17 18 class NotifyThread extends Thread { 19 20 @Override 21 public void run() { 22 synchronized (flag) { 23 for (int i = 0; i < 5; i++) { 24 try { 25 sleep(1000); 26 } catch (InterruptedException e) { 27 e.printStackTrace(); 28 } 29 System.out.println("NotifyThread.run()---" + i); 30 } 31 flag[0] = "false"; 32 flag.notify(); 33 } 34 } 35 } 36 37 class WaitThread extends Thread { 38 39 @Override 40 public void run() { 41 //使用flag使得線程獲得鎖 42 synchronized (flag) { 43 while (flag[0] != "false") { 44 System.out.println("WaitThread.run....."); 45 try { 46 flag.wait(); 47 } catch (InterruptedException e) { 48 e.printStackTrace(); 49 } 50 } 51 System.out.println("wait() end..."); 52 } 53 } 54 } 55 }
上面的代碼演示了如何使用wait()和notify()方法,代碼釋義:主線程執行,打印出main thread start.....語句當在main()中調用waitThread.start()之後,線程啟動,執行run方法並獲得flag的鎖,並開始執行同步代碼塊中的代碼,接下來調用wait()方法後,waitThead阻塞並讓出flag鎖,此時notifyThread獲得flag鎖,開始執行,每隔1s打印出對應的語句,循環結束後,將flag中的標誌置為false並使用notify()喚醒waitThread線程,使得waitThread線程繼續執行,打印出wait() end...此時程序結束。控制臺打印結果如下:
線程優先級
每個線程都有一個優先級,在線程大量被阻塞時,程序會優先選擇優先級較高的線程執行。但是不代表優先級低的線程不被執行,只是機會相對較小罷。getPriority()獲取線程的優先級,setPriority()設置線程的優先級。線程默認的優先級為5。
並發容器和框架
hashmap原理
都知道hashmap是線程不安全的。為什麽不安全?先看下hashmap的數據結構:
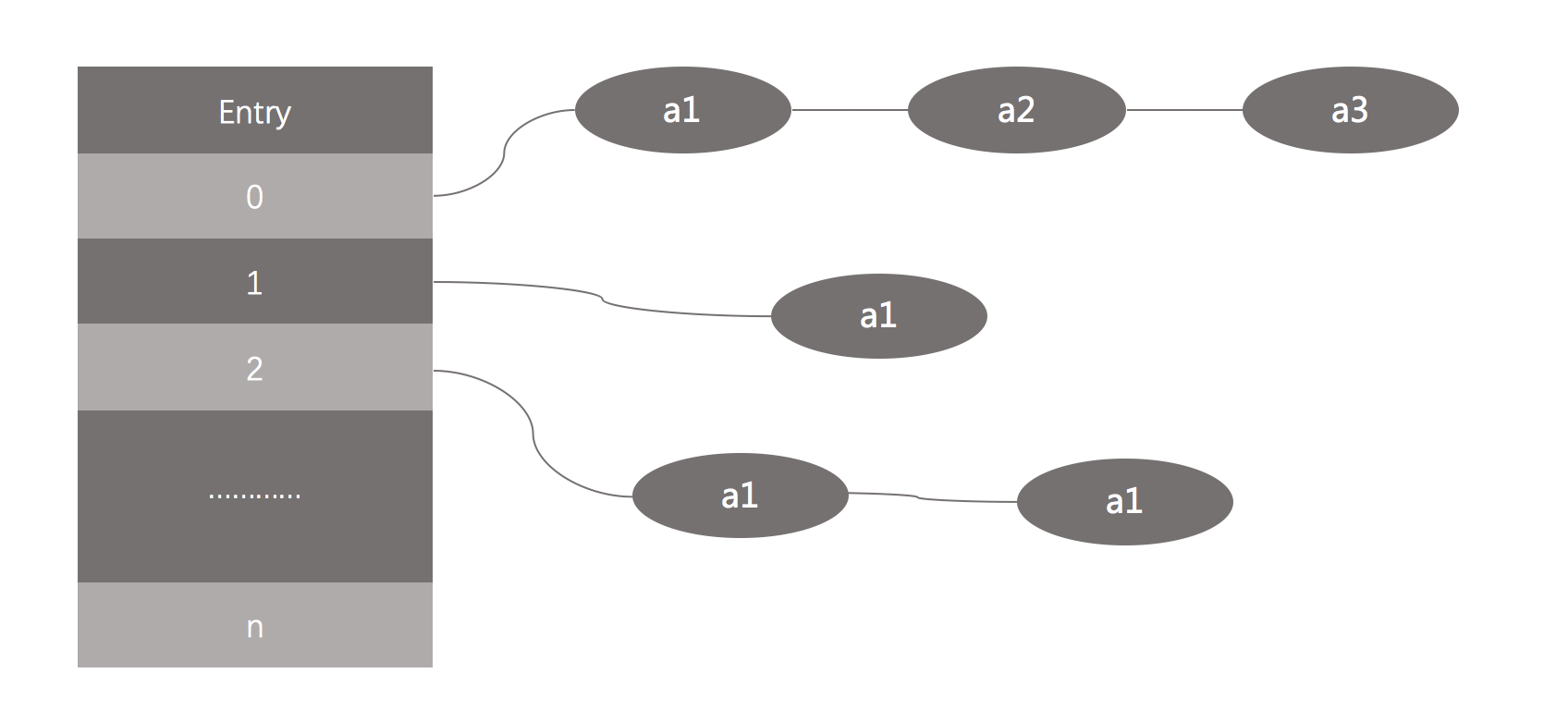
在JDK1.8之前,hashmap采用數組+鏈表的數據結構,如上圖;而在JDK1.8時,其數據結構變為了數據+鏈表+紅黑樹。當鏈表長度超過8時,會自動轉換為紅黑樹(抽時間復習紅黑樹,快忘記了!),提高了查找效率。當向hashmap中添加元素時,hashmap內部實現會根據key值計算其hashcode,如果hashcode值沒有重復,則直接添加到下一個節點。如果hashcode重復了,則會在重復的位置,以鏈表的方式存儲該元素。JDK1.8源碼分析:
1 /** 2 * Associates the specified value with the specified key in thismap. 3 * If the map previously contained a mapping for the key, the old 4 * value is replaced. 5 * 6 */ 7 public V put(K key, V value) { 8 return putVal(hash(key), key, value, false, true); 9 } 10 static final int hash(Object key) { 11 int h; 12 //key的值為null時,hash值返回0,對應的table數組中的位置是0 13 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 14 } 15 16 /** 17 * Implements Map.put and related methods 18 * 19 * @param hash hash for key 20 * @param key the key 21 * @param value the value to put 22 * @param onlyIfAbsent if true, don‘t change existing value 23 * @param evict if false, the table is in creation mode. 24 * @return previous value, or null if none 25 */ 26 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 27 boolean evict) { 28 Node<K,V>[] tab; Node<K,V> p; int n, i; 29 //先將table賦給tab,判斷table是否為null或大小為0,若為真,就調用resize()初始化 30 if ((tab = table) == null || (n = tab.length) == 0) 31 n = (tab = resize()).length; 32 //通過i = (n - 1) & hash得到table中的index值,若為null,則直接添加一個newNode 33 if ((p = tab[i = (n - 1) & hash]) == null) 34 tab[i] = newNode(hash, key, value, null); 35 else { 36 //執行到這裏,說明發生碰撞,即tab[i]不為空,需要組成單鏈表或紅黑樹 37 Node<K,V> e; K k; 38 if (p.hash == hash && 39 ((k = p.key) == key || (key != null && key.equals(k)))) 40 //此時p指的是table[i]中存儲的那個Node,如果待插入的節點中hash值和key值在p中已經存在,則將p賦給e 41 e = p; 42 //如果table數組中node類的hash、key的值與將要插入的Node的hash、key不吻合,就需要在這個node節點鏈表或者樹節點中查找。 43 else if (p instanceof TreeNode) 44 //當p屬於紅黑樹結構時,則按照紅黑樹方式插入 45 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 46 else { 47 //到這裏說明碰撞的節點以單鏈表形式存儲,for循環用來使單鏈表依次向後查找 48 for (int binCount = 0; ; ++binCount) { 49 //將p的下一個節點賦給e,如果為null,創建一個新節點賦給p的下一個節點 50 if ((e = p.next) == null) { 51 p.next = newNode(hash, key, value, null); 52 //如果沖突節點達到8個,調用treeifyBin(tab, hash),這個treeifyBin首先回去判斷當前hash表的長度,如果不足64的話,實際上就只進行resize,擴容table,如果已經達到64,那麽才會將沖突項存儲結構改為紅黑樹。 53 54 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 55 treeifyBin(tab, hash); 56 break; 57 } 58 //如果有相同的hash和key,則退出循環 59 if (e.hash == hash && 60 ((k = e.key) == key || (key != null && key.equals(k)))) 61 break; 62 p = e;//將p調整為下一個節點 63 } 64 } 65 //若e不為null,表示已經存在與待插入節點hash、key相同的節點,hashmap後插入的key值對應的value會覆蓋以前相同key值對應的value值,就是下面這塊代碼實現的 66 if (e != null) { // existing mapping for key 67 V oldValue = e.value; 68 //判斷是否修改已插入節點的value 69 if (!onlyIfAbsent || oldValue == null) 70 e.value = value; 71 afterNodeAccess(e); 72 return oldValue; 73 } 74 } 75 ++modCount;//插入新節點後,hashmap的結構調整次數+1 76 if (++size > threshold) 77 resize();//HashMap中節點數+1,如果大於threshold,那麽要進行一次擴容 78 afterNodeInsertion(evict); 79 return null; 80 }
hashmap不安全的原因:上面分析了JDK源碼,知道了put方法不是同步的,如果多個線程,在某一時刻同時操作HashMap並執行put操作,而有大於兩個key的hash值相同,這個時候需要解決碰撞沖突,而解決沖突的辦法采用拉鏈法解決碰撞沖突,對於鏈表的結構在這裏不再贅述,暫且不討論是從鏈表頭部插入還是從尾部插入,這個時候兩個線程如果恰好都取到了對應位置的頭結點e1,而最終的結果可想而知,這兩個數據中勢必會有一個會丟失。同理,hashmap擴容的方法也如此,當多個線程同時檢測到總數量超過門限值的時候就會同時調用resize操作,各自生成新的數組並rehash後賦給該map底層的數組table,結果最終只有最後一個線程生成的新數組被賦給table變量,其他線程的均會丟失。而且當某些線程已經完成賦值而其他線程剛開始的時候,就會用已經被賦值的table作為原始數組,這樣也會有問題。
hashtable原理
HashTable容器使用synchronized來保證線程安全,但在線程競爭激烈的情況下HashTable的效率非常低下。因為當一個線程訪問HashTable的同步方法,其他線程也訪問HashTable的同步方法時,會進入阻塞或輪詢狀態。如線程1使用put進行元素添加,線程2不但不能使用put方法添加元素,也不能使用get方法來獲取元素,所以競爭越激烈效率越低。
ConcurrentHashMap登場
ConcurrentHashMap鎖分段技術:HashTable容器在競爭激烈的並發環境下表現出效率低下的原因是所有訪問HashTable的線程都必須競爭同一把鎖,假如容器裏有多把鎖,每一把鎖用於鎖容器其中一部分數據,那麽當多線程訪問容器裏不同數據段的數據時,線程間就不會存在鎖競爭,從而可以有效提高並發訪問效率,這就是ConcurrentHashMap所使用的鎖分段技術。首先將數據分成一段一段地存儲,然後給每一段數據配一把鎖,當一個線程占用鎖訪問其中一個段數據的時候,其他段的數據也能被其他線程訪問。以下是ConcurrentHashMap的數據結構:
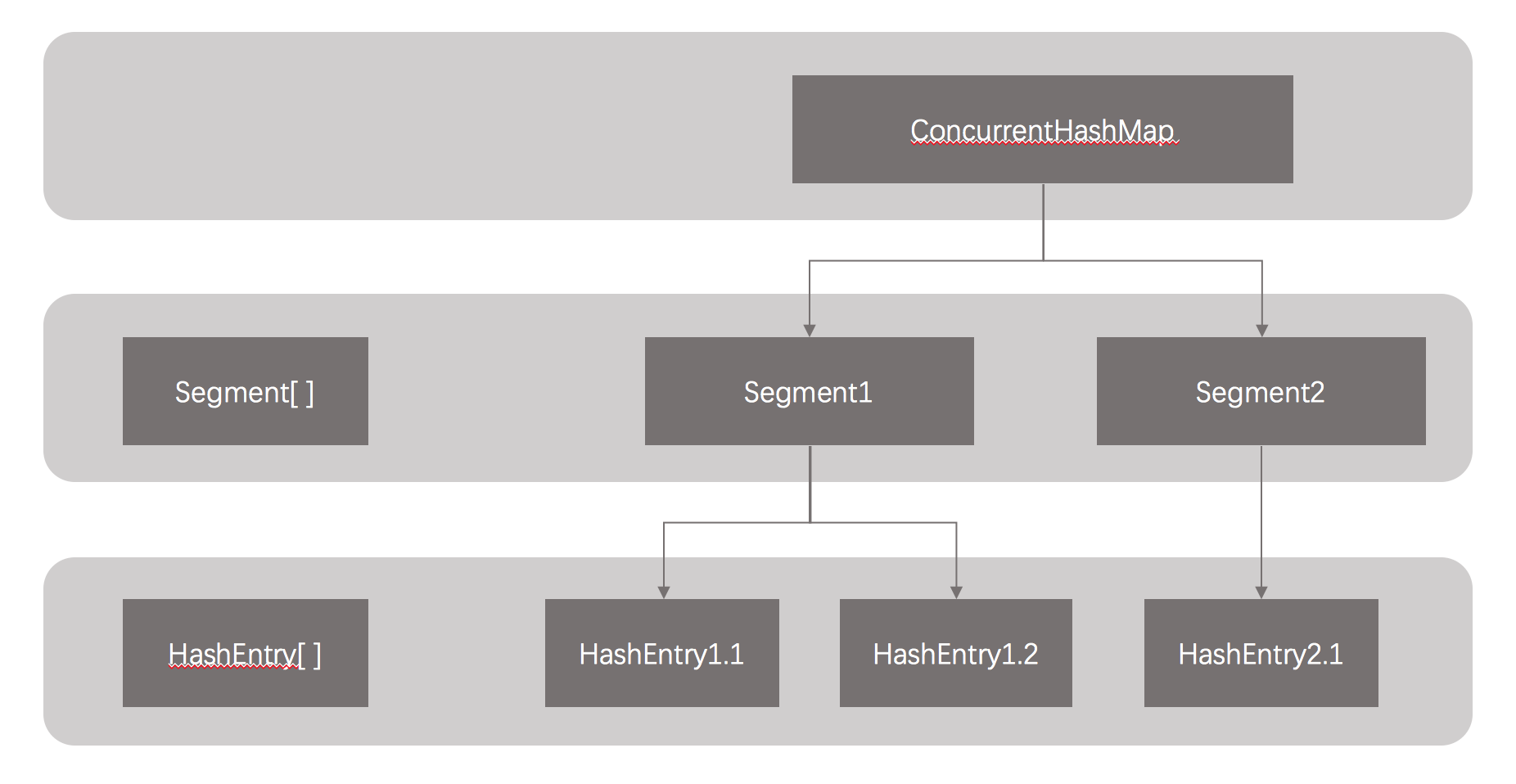
ConcurrentHashMap是由Segment數組結構和HashEntry數組結構組成。Segment是一種可重入鎖(ReentrantLock),在ConcurrentHashMap裏扮演鎖的角色;HashEntry則用於存儲鍵值對數據。一個ConcurrentHashMap裏包含一個Segment數組。Segment的結構和HashMap類似,是一種數組和鏈表結構。一個Segment裏包含一個HashEntry數組,每個HashEntry是一個鏈表結構的元素每Segment守護著一個HashEntry數組裏的元素,當對HashEntry數組的數據進行修改時,必須首先獲得與它對應的Segment鎖。
Fork/Join框架
什麽是Fork/Join框架?
Fork/Join框架是Java 7提供的一個用於並行執行任務的框架,是**一個把大任務分割成若幹個小任務,最終匯總每個小任務結果後得到大任務結果的框架。**Fork就是把一個大任務切分為若幹子任務並行的執行,Join就是合並這些子任務的執行結果,最後得到這個大任務的結果。比如計算1+2+…+10000,可以分割成10個子任務,每個子任務分別對1000個數進行求和,最終匯總這10個子任務的結果。如圖:
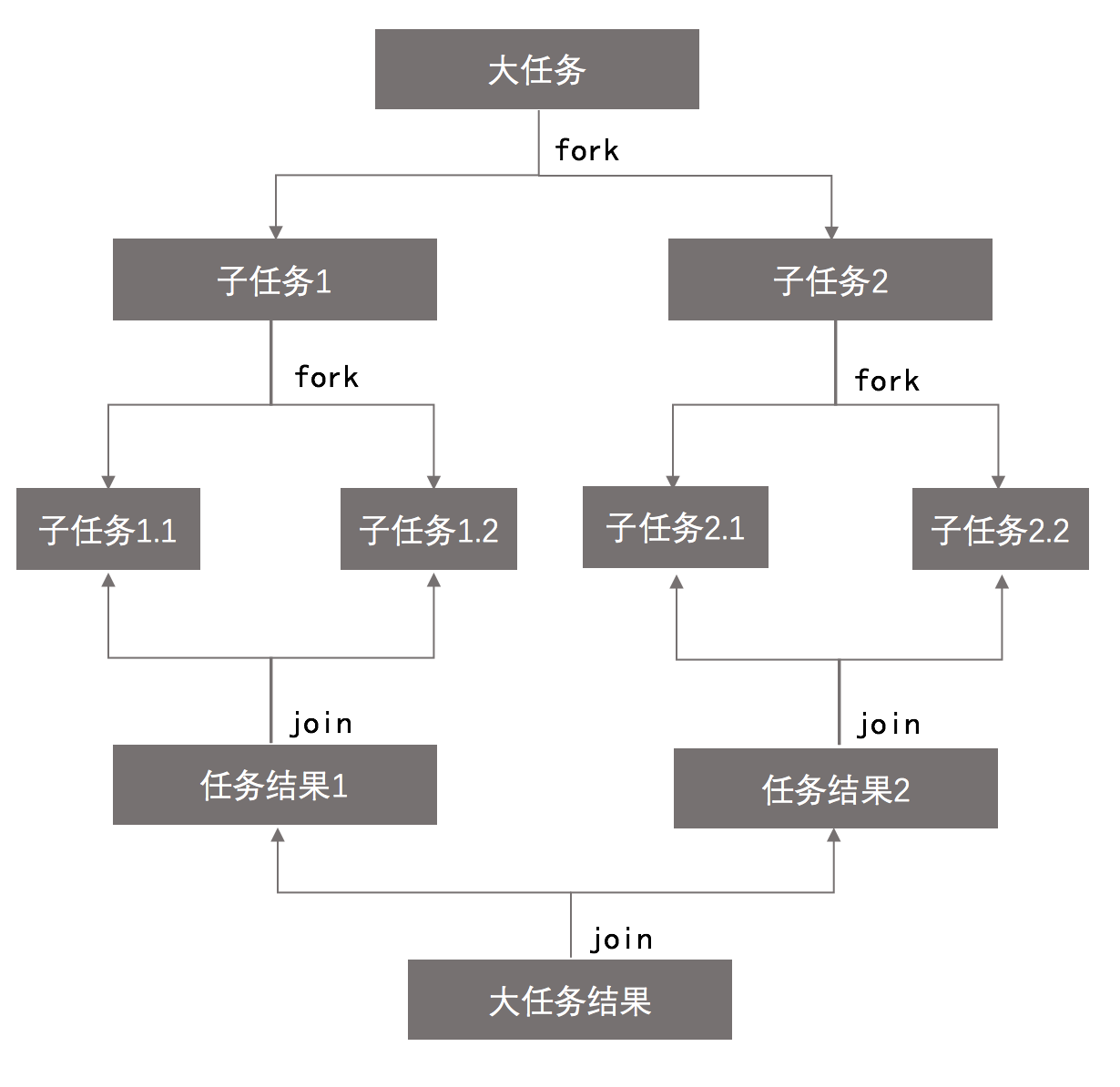
工作竊取算法
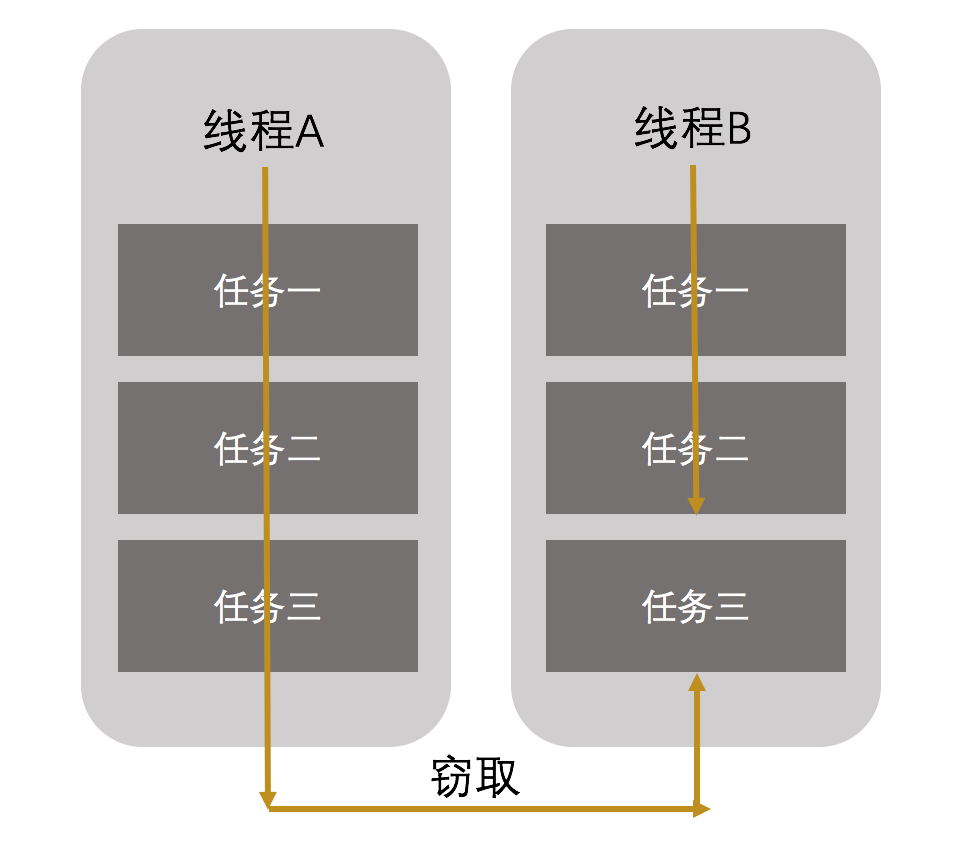
工作竊取(work-stealing)算法是指某個線程從其他隊列裏竊取任務來執行。假如我們需要做一個比較大的任務,可以把這個任務分割為若幹互不依賴的子任務,為了減少線程間的競爭,把這些子任務分別放到不同的隊列裏,並為每個隊列創建一個單獨的線程來執行隊列裏的任務,線程和隊列一一對應。比如A線程負責處理A隊列裏的任務。但是,有的線程會先把自己隊列裏的任務幹完,而其他線程對應的隊列裏還有任務等待處理。幹完活的線程與其等著,不如去幫其他線程幹活,於是它就去其他線程的隊列裏竊取一個任務來執行。而在這時它們會訪問同一個隊列,所以為了減少竊取任務線程和被竊取任務線程之間的競爭,通常會使用雙端隊列,被竊取任務線程永遠從雙端隊列的頭部拿任務執行,而竊取任務的線程永遠從雙端隊列的尾部拿任務執行。如下圖:
該篇文章主要記錄一些關於線程中鎖機制的基礎,以及簡單分析了一下HashMap,HashTable以及ConcurrentHashMap的相關原理,文章最後簡單的涉及了一下Fork-Join框架,由於本周比較忙,所以還未深入學習,下篇博客將會使用Fork-Join框架寫一些demo幫助理解。
讀《Java並發編程的藝術》(二)