
MySQL優化概述
MySQL優化概述
設計: 存儲引擎,字段類型,範式
功能: 索引,緩存,分區。
架構: 主從復制,讀寫分離,負載均衡。
合理SQL: 測試,經驗。
存儲引擎
Create table tableName () engine=myisam|innodb;
一種用來存儲MySQL中對象(記錄和索引)的一種特定的結構(文件結構)
存儲引擎,處於MySQL服務器的最底層,直接存儲數據。導致上層的操作,依賴於存儲引擎的選擇。

Tip:存儲引擎就是特定的數據存儲格式(方案)
Show engines
查看當前MySQL支持的存儲引擎列表


Innodb
>=5.5 默認的存儲引擎,MySQL推薦使用的存儲引擎。
提供事務,行級鎖定,外鍵約束的存儲引擎。
事務安全型存儲引擎。更加註重數據的完整性和安全性。
存儲格式
數據,索引集中存儲,存儲於同一個表空間文件中。
數據(記錄行)
索引(一種檢索機制,也需要一定的空間)
創建innodb表後,存在文件如下:
.frm 表結構文件。

Innodb表空間文件:innodb的數據和索引。

該位置,可以被配置的。
默認,所有的innodb表的表空間文件,都在同一個空間中。
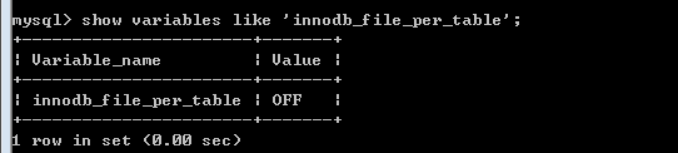
通過配置,達到每張innodb表,
開啟該配置:


數據按照主鍵順序存儲

插入時做排序工作,效率低。
特定功能
事務:
外鍵約束:
維護數據完整性。
並發性處理:
擅長處理並發的。
行級鎖定: row-level locking,實現了行級鎖定,在一定情況下,可以選擇行級鎖來提升並發性。也支持表級鎖定,innodb根據操作選擇。
多版本並發控制, MVCC,效果達到無阻塞讀操作。
MyISAM
<= 5.5 MySQL默認的存儲引擎。
ISAM:Indexed Sequential Access Method(索引順序
擅長與處理 高速讀與寫。
存儲方式
數據索引分別存儲於不同的文件中。

數據的存儲順序為插入順序

插入速度快,空間占用量小。
功能
全文索引支持。(>=5.6 innodb 支持)
數據的壓縮存儲。.MYD文件的壓縮存儲。
壓縮前:

壓縮:工具 myisamPack完成 壓縮功能:

進入到 需要壓縮表的數據目錄:
執行壓縮指令 myisampack 表名

結果:

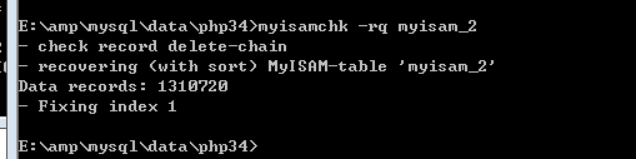
註意,壓縮後,需要重新修復索引:

Tip:壓縮優勢:節省磁盤空間,減少磁盤IO開銷。
特點:壓縮表為只讀表。

如果需要更新,則需要解壓後更新,再壓縮(重新索引):
利用工具:myisamchk –unpack 表名

結果

Flush table myisam_2

並發性:
僅僅支持表級鎖定。
支持 並發插入。寫操作中的插入操作,不會阻塞讀操作(其他操作)
Innodb PK myisam:
數據完整性,並發性處理,擅長更新,刪除。
高速查詢及插入。擅長 插入,查詢。
Archive
存檔型
僅提供 插入和查詢操作。非常高效 無阻塞的插入和查詢。
Memory
內存型
數據存儲於內存中,存儲引擎。緩存型存儲引擎。
插件式存儲引擎
鎖
當客戶端操作表(記錄)時,為了保證操作的隔離性(多個客戶端操作不能互相影響),通過加鎖來處理。
操作方面:
讀鎖:讀操作時增加的鎖,也叫共享鎖,S-lock。特征是 阻塞其他客戶端的寫操作,不阻塞讀操作。
寫鎖:寫操作時增加的鎖,也叫獨占鎖或排他鎖,X-lock。特征,阻塞其他客戶端的讀,寫操作。
鎖定粒度(範圍):
行級:提升並發性,鎖本身開銷大
表級:不利於並發性,鎖本身開銷小。
類型選擇
滿足需求。
原則:
盡可能小(占用存儲空間少)
Tinyint, smallint, mediumint,int, bigint
Varchar(N) varchar(M)
Datetime, timestamp
盡可能定長(占用存儲空間固定)
Char,varchar
Decimal(變長), double(float)(定長)
盡可能使用整數
IPV4, int unsigned, varchar(15)
Enum
Set
多用位運算。
範式,逆範式
Goods
Goods_id, goods_name, cat_id
Category
Cat_id, cat_name,
分類列表查詢:
分類ID 分類名稱 商品數量
3 計算機 567
Select c.*, count(g.goods_id) as goods_count from category as c left join goods as g c.cat_id=g.cat_id group by c.cat_id;
此時商品數量較大。
重新設計category表:增加存當前分類下商品數量的字段。
Category
Cat_id, cat_name, goods_count
每當商品改動時,修改對應分類的數量信息。
再查詢分類列表時:
Select * from category;
此時額外的消耗,出現在維護該字段的正確性上,保證商品的任何更新都正確的處理該數量才可以。
索引的使用
利用關鍵字,就是記錄的部分數據(某個字段,某些字段,某個字段的一部分),建立與記錄位置的對應關系,就是索引。
索引的關鍵字一定是排序的。

測試查詢,添加索引前後比對執行時間:

索引的類型
4種類型:
主索引,唯一索引,普通索引,全文索引。
無論任何類型,都是通過建立關鍵字與位置的對應關系來實現的。
以上類型的差異:對索引關鍵字的要求不同。
關鍵字:記錄的部分數據(某個字段,某些字段,某個字段的一部分)。
普通索引,index: 對關鍵字沒有要求。
唯一索引,unique index: 要求關鍵字不能重復。同時增加唯一約束。
主鍵索引,primary key: 要求關鍵字不能重復,也不能為NULL。同時增加主鍵約束。
全文索引,fulltext key: 關鍵字的來源不是所有字段的數據,而是從字段中提取的特別關鍵詞。
關鍵字的來源:可以是某個字段,也可以是某些字段。如果一個索引通過在多個字段上提取的關鍵字,稱之為 復合索引。
alter table emp add index (field1, field2);
管理索引的語法
創建
建表時

TiP;索引可以起名字,但是主索引不能起名字,因為一個表僅僅可以有一個主索引,其他索引可以出現多個。名字可以省略,mysql會默認生成,通常使用字段名來充當。
更新表結構

Tip:
1, 如果表中存在數據,數據符合唯一或主鍵的約束才可能創建成功。
2, Auto_increment屬性,依賴於一個KEY。
刪除

Tip: 別忘了 auto_increment依賴於KEY
Explain 執行計劃
可以通過在select語句前使用 explain,來獲取該查詢語句的執行計劃,而不是真正執行該語句。

刪除索引時,再看執行計劃:

Tip:select語句才能獲取到執行計劃。(新版本會擴展其他語句的執行計劃的獲取)
索引的使用
使用場景
索引檢索
條件過濾
索引排序
如果order by 排序需要的字段,上存在索引,可能使用到索引。
例如,按照ename字段排序查詢:

此時,沒有任何索引。
在ename字段上建立索引:

Tip:對比以上兩個執行計劃:
extra位置:


其中:extra額外信息。
Using filesort,表示使用文件排序(外部排序,內存外部)。
索引覆蓋
索引擁有的關鍵字內容,覆蓋了查詢所需要的全部數據,此時,就不需要在數據區獲取數據,僅僅在索引區即可。
例如,利用名字檢索:

可以在ename字段建立索引:

分析執行:

再增加一個索引:

完成相同的查詢:

再例如:
說明,不是非要查詢用到,才可以索引覆蓋,只要滿足要求都可以覆蓋!


直到索引使用場景時:
建立索引索引時,不要僅僅考慮where檢索了吧,同時考慮其他的使用場景。
(在所有的where字段上增加索引,就是不合理的)
使用原則
索引存在,沒有滿足使用原則,導致索引無效:
列獨立
如果需要某個字段上使用索引,則需要在字段參與的表達中,保證字段獨立在一側。

第三個語句 empno-1就不是列獨立:就不能用索引。類似函數內等。(write_time < unix_timestamp()-$gc_maxlifetime)

其他兩個列獨立可以使用:

左原則
Like:匹配模式必須要左邊確定不能以通配符開頭。

業務邏輯上出現: field like ‘%keywork%’;類似查詢,需要使用全文索引。
復合索引:
一個索引關聯多個字段。
僅僅針對左邊字段有效果。


結果:
Ename的查詢,使用了索引:

Empno的查詢沒有使用索引:

OR的使用
必須要保證 OR 兩端的條件都存在可以用的索引,該查詢才可以使用索引。
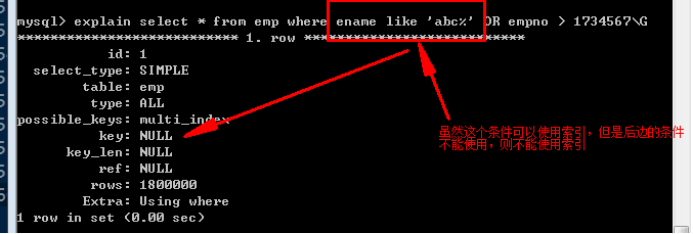
為後面的條件增加可以使用的索引:

MySQL智能選擇
即使滿足了上面說原則,MySQL也能棄用索引:

棄用索引的主要原因:
查詢即使使用索引,會導致出現大量的 隨機IO,相對於從數據記錄的第一條遍歷到最後一條的順序IO開銷,還要大。
目的:建立索引時,建立滿足使用原則的字段上。
MySQL優化概述