
基礎很重要~~04.表表達式
閱讀目錄
- 概述:
- 一、視圖
- 二、內聯表值函數
- 三、APPLY運算符
以前總是追求新東西,發現基礎才是最重要的,今年主要的目標是精通SQL查詢和SQL性能優化。
本系列【T-SQL基礎】主要是針對T-SQL基礎的總結。
【T-SQL基礎】01.單表查詢-幾道sql查詢題
【T-SQL基礎】02.聯接查詢
【T-SQL基礎】03.子查詢
【T-SQL基礎】04.表表達式-上篇
【T-SQL基礎】04.表表達式-下篇
【T-SQL基礎】05.集合運算
【T-SQL基礎】06.透視、逆透視、分組集
【T-SQL基礎】07.數據修改
【T-SQL基礎】08.事務和並發
【T-SQL基礎】09.可編程對象
----------------------------------------------------------
【T-SQL進階】01.好用的SQL TVP~~獨家贈送[增-刪-改-查]的例子
----------------------------------------------------------
【T-SQL性能調優】01.TempDB的使用和性能問題
【T-SQL性能調優】02.Transaction Log的使用和性能問題
【T-SQL性能調優】03.執行計劃
【T-SQL性能調優】04.死鎖分析
持續更新......歡迎關註我!
回到頂部概述:
本篇主要是對表表達式中視圖和內聯表值函數基礎的總結。
表表達式包含四種:
1.派生表
2.公用表表達式
3.視圖
4.內聯表值函數
本篇是表表達式的下篇,只會講到視圖和內聯表值函數。
下面是表表達式的思維導圖:
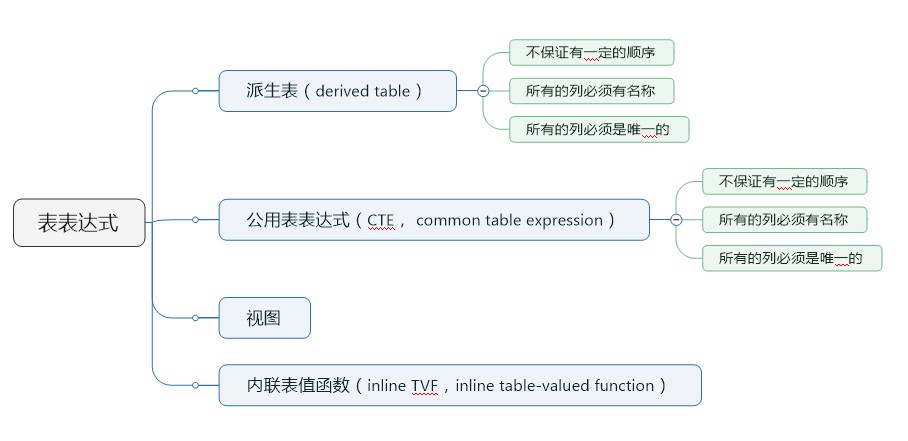
表表達式:
1.一種命名的查詢表達式,代表一個有效的關系表。
2.可以像其他表一樣,在數據處理語句中使用表表達式。
3.在物理上不是真實存在的什麽對象,它們是虛擬的。對於表達式的查詢在數據庫引擎內部都將轉化為對底層對象的查詢。
為什麽使用表表達式:
1.使用表表達式的好處是邏輯方面,在性能上沒有提升。
2.通過模塊化的方法簡化問題的解決方案,規避語言上的某些限制。在外部查詢的任何字句中都可以引用在內部查詢的SELECT字句中分配的列別名。比如在SELECT字句中起的別名,不能在WHERE,group by等字句(邏輯順序位於SELECT字句之前的字句)中使用,通過表表達式可以解決這類問題。
在閱讀下面的章節時,我們可以先把環境準備好,以下的SQL腳本可以幫助大家創建數據庫,創建表,插入數據。
下載腳本文件:TSQLFundamentals2008.zip
回到頂部
一、視圖
1.視圖和派生表和CTE的區別和共同點
區別:
派生表和CTE不可重用:只限於在單個語句的範圍內使用,只要包含這些表表達式的外部查詢完成操作,它們就消失了。
視圖和內聯表值函數是可重用的:它們的定義存儲在一個數據對象中,一旦創建,這些對象就是數據庫的永久部分;只有用刪除語句顯示刪除或用右鍵刪除,它們才會從數據庫中移除。
共同點:
在很多方面,視圖和內聯表值函數的處理方式都類似於派生表和CTE。當查詢視圖和內聯表值函數時,SQL Server會先擴展表表達式的定義,再直接查詢底層對象。
2.語法
下面的例子定義了一個視圖,視圖名稱為Sales.USACusts,查詢所有來自美國的客戶。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
USE TSQLFundamentals2008
IF OBJECT_ID(‘Sales.USACusts‘) IS NOT NULL
DROP VIEW Sales.USACusts;
GO
CREATE VIEW Sales.USACusts
AS
SELECT custid ,
companyname ,
contacttitle ,
address ,
city ,
region ,
postalcode ,
country ,
phone ,
fax
FROM Sales.Customers
WHERE country = N‘USA‘
|
定義好了視圖之後,在數據庫中刷新視圖列表之後就會出現剛剛創建的視圖Sales.USACusts
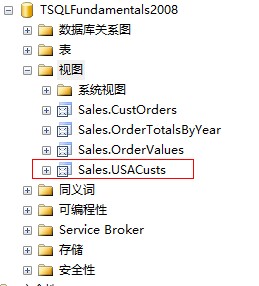
然後,就可以像查詢數據庫中其他表一樣對視圖進行查詢:
| 1 2 3 |
SELECT custid ,
companyname
FROM sales.usacusts
|
3.視圖的權限
可以像其他數據庫對象一樣,對視圖的權限進行控制:如SELECT、INSERT、UPDATE、DELETE權限
4.避免使用SELECT * 語句
列是在編譯視圖時進行枚舉的,新加的列不會自動加到視圖中。以後對視圖中用到的表增加了幾列,這些列不會自動添加到視圖中。可以用sp_refreshview的存儲過程刷新視圖的元數據,但是為了以後的維護,還是在視圖中顯示地需要的列名。如果在底層表中添加了列,而在視圖中需要這些新加的列,可以使用ALTER VIEW語句對視圖定義進行相應的修改。
5.創建視圖的要求:
必須要滿足之前介紹派生表時對表表達式提到的所有要求:
a.列必須有名稱
b.列必須唯一
c.不保證有一定的順序。在定義表表達式的查詢語句中不允許出現ORDER BY字句。因為關系表的行之間沒有順序。
6.加密選項ENCRYPTION
在創建視圖、存儲過程、觸發器及用戶定義函數時,都可以使用ENCRYPTION加密選項。如果指定ENCRYPTION選項,SQL Server在內部會對定義對象的文本信息進行混淆(obfuscated)處理。普通用戶看不到該視圖的文本,只有特權用戶通過特殊手段才能訪問創建對象的文本。
在視圖定義的頭部,用WITH字句來指定ENCRYPTION選項,如下所示:
| 1 | CREATE VIEW Sales.USACusts WITH ENCRYPTION |
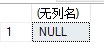
可以用下面的語句查看視圖的文本:
| 1 | SELECT OBJECT_DEFINITION(OBJECT_ID(‘Sales.USACusts‘)) |
結果如下:
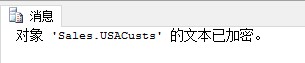
也可以用sp_helptext查看視圖的文本:
| 1 | sp_helptext ‘Sales.USACusts‘ |
結果如下:
只有在對安全要求較高的情況下才需要對視圖進行加密,一般情況不需要加密。
7.架構綁定選項SCHEMABINDING
視圖和用戶自定義函數支持SCHEMABINDING選項。一旦指定了這個選項,視圖引用的對象不能刪除,被引用的列不能刪除或修改。
在視圖定義的頭部,用WITH字句來指定SCHEMABINDING選項,如下所示:
| 1 | CREATE VIEW Sales.USACusts WITH SCHEMABINDING |
可以用下面的語句,更新Sales.USACusts視圖所引用的Sales.Customers對象的address列
| 1 | ALTER TABLE Sales.Customers DROP COLUMN address |
結果如下:

建議在創建視圖時,使用SCHEMABINDING選項。
如果使用SCHEMABINDING選項,必須滿足兩個技術要求:
a.必須在SELECT字句中顯示地列出列名
b.在引用對象時,必須使用帶有架構名稱修飾的完整對象名稱。
8.CHECK OPTION選項
CHECK OPTION選項的目的是為了防止通過視圖執行的數據修改與視圖中設置的過濾條件(假設在定義視圖的查詢中存在過濾條件)發生沖突。
假設想通過Sales.USACusts視圖往Sales.Customers表中插入數據,可以使用下面的語句:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
INSERT INTO Sales.USACusts
( companyname ,
contactname ,
contacttitle ,
address ,
city ,
region ,
postalcode ,
country ,
phone ,
fax
)
VALUES ( ‘A‘ ,
‘A‘ ,
‘A‘ ,
‘A‘ ,
‘London‘ ,
‘A‘ ,
‘A‘ ,
‘UK‘ ,
‘123‘ ,
‘123‘
)
|
然後查詢Sales.Customers表,如下所示:
| 1 2 3 |
SELECT custid,companyname,country
FROM Sales.Customers
WHERE companyname = ‘A‘
|
結果:

如果用視圖進行查詢,如下所示:
| 1 2 3 4 5 |
SELECT custid ,
companyname ,
country
FROM Sales.USACusts
WHERE companyname = ‘A‘
|
則得到的是一個空的結果集,因為視圖中的WHERE條件WHERE country = N‘USA‘只篩選來自美國的客戶。
如果想防止這種與視圖的查詢過濾條件相沖突的修改,只須在定義視圖的查詢語句末尾加上WITH CHECK OPTION即可:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
ALTER VIEW [Sales].[USACusts]
AS
SELECT custid ,
companyname ,
contactname ,
contacttitle ,
address ,
city ,
region ,
postalcode ,
country ,
phone ,
fax
FROM Sales.Customers
WHERE country = N‘USA‘
WITH CHECK OPTION;
GO
|
再試下插入與視圖的過濾條件相沖突的記錄:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
INSERT INTO Sales.USACusts
( companyname ,
contactname ,
contacttitle ,
address ,
city ,
region ,
postalcode ,
country ,
phone ,
fax
)
VALUES ( ‘A‘ ,
‘A‘ ,
‘A‘ ,
‘A‘ ,
‘London‘ ,
‘A‘ ,
‘A‘ ,
‘UK‘ ,
‘123‘ ,
‘123‘
)
|
結果如下:

9.練習題:
(1)創建一個視圖,返回每個雇員每年處理的總訂貨量:
期望結果:
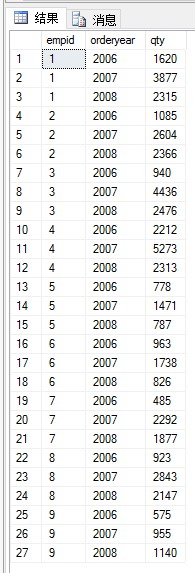
本題考察視圖的創建
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
IF OBJECT_ID(‘Sales.VEmpOrders‘) IS NOT NULL
DROP VIEW Sales.VEmpOrders;
GO
CREATE VIEW Sales.VEmpOrders
AS
SELECT empid ,
YEAR(orderdate) AS orderyear ,
SUM(qty) AS qty
FROM Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS D ON O.orderid = D.orderid
GROUP BY empid ,
YEAR(orderdate);
GO
|
(2)寫一個對Sales.VEmpOrders表的查詢,返回每個雇員每年處理過的連續總訂貨量
期望的輸出:
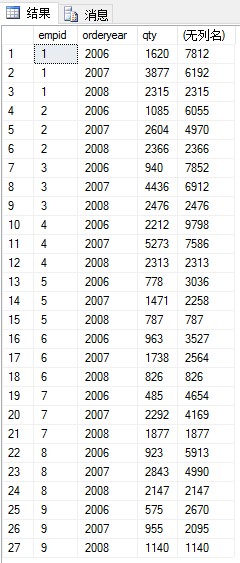
此題需要用到相關子查詢:
| 1 2 3 4 5 6 7 8 9 10 |
SELECT empid ,
orderyear ,
qty ,
( SELECT SUM(qty) AS runqty
FROM Sales.VEmpOrders AS EO2
WHERE EO1.empid = EO2.empid
AND EO1.orderyear <= EO2.orderyear
)
FROM Sales.VEmpOrders AS EO1
ORDER BY EO1.empid ,
|
子查詢返回訂單年份小於或等於外查詢當前行的訂單年份的所有行,並計算這些行的訂貨量之和。
回到頂部二、內聯表值函數
1.什麽是內聯表值函數
一種可重用的表表達式,能夠支持輸入參數。除了支持輸入參數以外,內聯表值函數在其他方面都與視圖相似。
2.如何定義內聯表值函數
下面的例子創建了一個函數fn_GetCustOrders。這個內聯表值接收一個輸入客戶ID參數@cid,另外一個輸入參數訂單年份參數@orderdateyear,返回客戶ID等於@cid的客戶下的所有訂單,且訂單的訂單年份等於@orderdateyear
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
IF OBJECT_ID(‘dbo.fn_GetCustOrders‘) IS NOT NULL
DROP FUNCTION dbo.fn_GetCustOrders
GO
CREATE FUNCTION dbo.fn_GetCustOrders ( @cid AS INT ,@orderdateyear AS DATETIME)
RETURNS TABLE
AS RETURN
SELECT orderid ,
custid ,
empid ,
orderdate ,
requireddate ,
shippeddate ,
shipperid ,
freight ,
shipname ,
shipaddress ,
shipcity ,
shipregion ,
shippostalcode ,
shipcountry
FROM Sales.Orders
WHERE custid = @cid AND YEAR(orderdate) = YEAR(@orderdateyear)
Go
|
定義好了內聯表值函數之後,在數據庫中刷新可編程性-函數-表值函數列表之後就會出現剛剛創建的函數fn_GetCustOrders
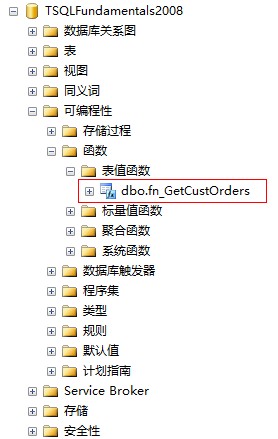
3.如何使用內聯表值函數
可以用內聯表值函數查詢出客戶id=1,訂單日期年份=2008的所有訂單:
| 1 | SELECT orderid,custid,orderdate FROM fn_GetCustOrders(1,‘2008‘) |
內聯表值函數也可以用在聯接查詢中:
下面的例子是用內聯表值函數與HR.Employees表進行關聯,查詢出客戶id=1,訂單日期年份=2008的所有訂單,以及處理對應訂單的員工詳情:
| 1 2 3 4 5 6 7 8 9 |
SELECT orderid ,
custid ,
orderdate ,
empid ,
lastname ,
firstname ,
title
FROM fn_GetCustOrders(1, ‘2008‘)
INNER JOIN HR.Employees AS E ON dbo.fn_GetCustOrders.empid = E.empid
|
結果如下:
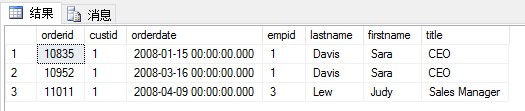
4.練習題
(1)創建一個內聯表值函數,其輸入參數為供應商ID(@supid AS INT)和要求的產品數量(@n AS INT)。該函數返回給定供應商@supid提供的產品中,單價最高的@n個產品。
當執行以下查詢時:
| 1 | SELECT * FROM fn_TopProducts(5,2) |
期望結果:
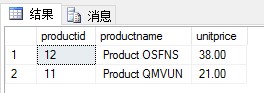
本題可以分三個步驟:
1.寫一個查詢語句
| 1 2 3 4 5 6 7 |
SELECT TOP ( 1 )
productid ,
productname ,
unitprice
FROM Production.Products
WHERE supplierid = 1
ORDER BY unitprice DESC;
|
2.將參數替換進去:
| 1 2 3 4 5 6 7 |
SELECT TOP ( @n )
productid ,
productname ,
unitprice
FROM Production.Products
WHERE supplierid = @supid
ORDER BY unitprice DESC;
|
3.將這個查詢放到內聯表值函數中
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
IF OBJECT_ID(‘dbo.fn_TopProducts‘) IS NOT NULL
DROP FUNCTION dbo.fn_TopProducts
GO
CREATE FUNCTION dbo.fn_TopProducts ( @supid AS INT, @n AS INT )
RETURNS TABLE
AS RETURN
SELECT TOP ( @n )
productid ,
productname ,
unitprice
FROM Production.Products
WHERE supplierid = @supid
ORDER BY unitprice DESC;
Go
|
三、APPLY運算符
1.APPLY運算符
APPLY運算符是一個非標準標準運算符。APPLY運算符對兩個輸入進行操作,其中右邊的表可以是一個表表達式。
CROSS APPLY:把右邊表達式應用到左表中的每一行,再把結果集組合起來,生成一個統一的結果表。和交叉連接相似
OUTER APPLY:把右邊表達式應用到左表中的每一行,再把結果集組合起來,然後添加外部行。和左外聯接中增加外部行的那一步相似
2.練習題
(1)使用CROSS APPLY運算符和fn_TopProducts函數,為每個供應商返回兩個價格最貴的產品。
涉及到的表:Production.Suppliers
期望結果:
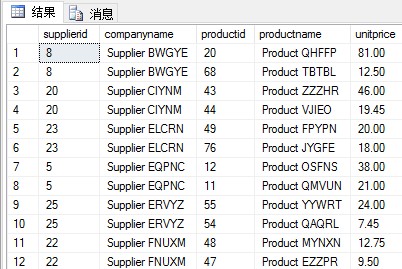
使用CROSS APPLY運算符為每個供應商應用前一個fn_TopProducts函數。
| 1 2 3 4 5 6 7 |
SELECT supplierid ,
companyname ,
productid ,
productname ,
unitprice
FROM Production.Suppliers AS S
CROSS APPLY fn_TopProducts(S.supplierid, 2) AS P
|
參考資料:
《SQL2008技術內幕:T-SQL語言基礎》
作 者: Jackson0714
出 處:http://www.cnblogs.com/jackson0714/
關於作者:專註於微軟平臺的項目開發。如有問題或建議,請多多賜教!
版權聲明:本文版權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文鏈接。
特此聲明:所有評論和私信都會在第一時間回復。也歡迎園子的大大們指正錯誤,共同進步。或者直接私信我
聲援博主:如果您覺得文章對您有幫助,可以點擊文章右下角【推薦】一下。您的鼓勵是作者堅持原創和持續寫作的最大動力!
基礎很重要~~04.表表達式