
流處理
流處理
1.1簡介
流處理是針對流式數據的實時計算。它具有實時持續、來源眾多、不關註存儲等特點。典型的應用場景有互聯網業務的日誌數據處理、金融領域的銀行股票數據處理等。
1.2 處理流程
傳統數據處理流程是用戶發起查詢請求,請求被翻譯成數據庫查詢語句,最終通過數據戶將查詢結果返回給用戶。此時用戶是主動的,DBMS是被動的
流處理數據處理流程是數據實時采集、實時計算、實時接受查詢服務。用戶接收流處理後的結果。此時用戶是被動的,DBMS是主動的。
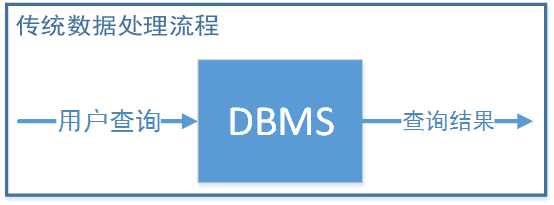
傳統數據處理流程

流處理數據處理流程
2.流處理系統
2.1 Storm
2.1.1Storm簡介
Storm (event processor)是一個分布式計算框架,主要由Clojure編程語言編寫。最初是由Nathan Marz及其團隊創建於BackType,該項目在被Twitter取得後開源。它通過使用者定義的“噴嘴(spouts)”和“閥門(bolts)”來定義數據源和相應的操作來實現批量、分布式處理流式數據。最初版本發布於2011年9月17日,目前最新穩定版本為2016年8月10日的1.0.2版本。
Storm應用被設計稱為一個拓撲結構,該拓撲結構是一個有向無環圖(Directed Acyclic Graph,DAG)。有向無環圖的頂點是“噴嘴”和“閥門”,邊是數據流。一個簡單的拓撲結構如圖2-1所示:
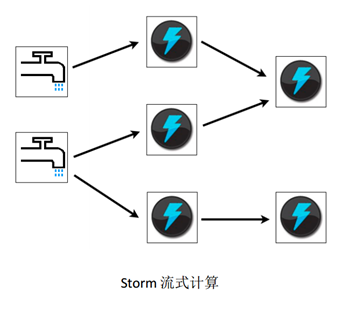
圖2-1 Storm流式計算拓撲
下面對Storm中的重要概念進行簡要介紹。
2.1.1.1Streams(流)
Storm對於流Stream的抽象:流是一個不間斷的無界的連續Tuple(元組,是元素有序列表)。Stream消息流,是一個沒有邊界的Tuple序列,這些Tuples會被以一種分布式的方式並行地創建和處理。如圖2-2所示。

圖2-2 Streams抽象
2.1.1.2 Spouts(噴嘴)
Storm認為每個Stream都有一個源頭,它將這個源頭抽象為Spouts。Spouts流數據源,它會從外部讀取流數據並發出Tuple。如圖2-3所示。

圖2-3 Spouts
2.1.1.3 Bolts(閥門)
Storm將流的中間狀態轉換抽象為Bolts,Bolts可以處理Tuples,同時它也可以發送新的流給其他Bolts使用。Bolts消息處理者,所有的消息處理邏輯被封裝在Bolts裏面,處理輸入的數據流並產生輸出的新數據流,可執行過濾,聚合,查詢數據庫等操作。如圖2-4所示。

圖2-4 Bolts
2.1.1.4 Topology(拓撲)
為了提高效率,在Spout源接上多個Bolts處理器。Storm將這樣的有向無環圖抽象為Topology(拓撲)。Topology是Storm中最高層次的抽象概念,它可以被提交到Storm集群執行,一個拓撲就是一個流轉換圖。圖中的邊表示Bolt訂閱了哪些流。當Spout或者Bolt發送元組到流時,它就發送元組到每個訂閱了該流的Bolt上進行處理。如圖2-5所示:

2-5 Topology
2.1.1.5 Stream Groupings(消息分組策略)
定義一個 Topology 的其中一步是定義每個Bolt 接收什麽樣的流作為輸入。Stream Grouping 就是用來定義一個Stream 應該如何分配給Bolts 上面的多個Tasks。Storm 裏面有6 種類型的Stream Grouping。
● Shuffle Grouping:隨機分組,隨機派發Stream 裏面的tuple,保證每個Bolt 接收到的tuple 數目相同。
● Fields Grouping:按字段分組,比如按userid 來分組,具有同樣userid 的tuple 會被分到相同的Bolts,而不同的userid 則會被分配到不同的Bolts。
● All Grouping:廣播發送,對於每一個tuple,所有的Bolts 都會收到。
● Global Grouping: 全局分組,這個tuple 被分配到Storm 中一個Bolt 的其中一個Task。再具體一點就是分配給id 值最低的那個Task。
● Non Grouping:不分組,這個分組的意思是Stream 不關心到底誰會收到它的tuple。目前這種分組和Shuffle Grouping 是一樣的效果,有一點不同的是Storm 會把這個Bolt 放到此Bolt 的訂閱者同一個線程裏面去執行。
● Direct Grouping:直接分組,這是一種比較特別的分組方法,用這種分組意味著消息的發送者指定由消息接收者的哪個Task 處理這個消息。只有被聲明為Direct Stream 的消息流可以聲明這種分組方法。而且這種消息tuple 必須使用emitDirect 方法來發送。消息處理者可以通過TopologyContext 來獲取處理它的消息的taskid(OutputCollector.emit 方法也會返回taskid)。
2.1.1.6 Reliability(可靠性)
Storm 可以保證每個消息tuple 會被Topology 完整地處理,Storm 會追蹤每個從Spout 發送出的消息tuple 在後續處理過程中產生的消息樹(Bolt 接收到的消息完成處理後又可以產生0 個或多個消息,這樣反復進行下去,就會形成一棵消息樹),Storm 會確保這棵消息樹被成功地執行。Storm 對每個消息都設置了一個超時時間,如果在設定的時間內,Storm 沒有檢測到某個從Spout 發送的tuple 是否執行成功,Storm 會假設該tuple 執行失敗,因此會重新發送該tuple。這樣就保證了每條消息都被正確地完整地執行。
Storm 保證消息的可靠性是通過在發送一個tuple 和處理完一個tuple 的時候都需要像Storm 一樣返回確認信息來實現的,這一切是由OutputCollector 來完成的。通過它的emit 方法來通知一個新的tuple 產生,通過它的ack 方法通知一個tuple 處理完成。
2.1.1.7 Task(任務)
在 Storm 集群上,每個Spout 和Bolt 都是由很多個Task 組成的,每個Task對應一個線程,流分組策略就是定義如何從一堆Task 發送tuple 到另一堆Task。在實現自己的Topology 時可以調用TopologyBuilder.setSpout() 和TopBuilder.setBolt()方法來設置並行度,也就是有多少個Task。
2.1.1.8 Worker(工作進程)
一個 Topology 可能會在一個或者多個工作進程裏面執行,每個工作進程執行整個Topology 的一部分。比如,對於並行度是300 的Topology 來說,如果我們使用50 個工作進程來執行,那麽每個工作進程會處理其中的6 個Tasks(其實就是每個工作進程裏面分配6 個線程)。Storm 會盡量均勻地把工作分配給所有的工作進程。
2.1.1.9 Config(配置)
在 Storm 裏面可以通過配置大量的參數來調整Nimbus、Supervisor 以及正在運行的Topology 的行為,一些配置是系統級別的,一些配置是Topology 級別的。所有有默認值的配置的默認配置是配置在default.xml 裏面的,用戶可以通過定義一個storm.xml 在classpath 裏來覆蓋這些默認配置。並且也可以使用Storm Submitter 在代碼裏面設置一些Topology 相關的配置信息。當然,這些配置的優先級是default.xml<storm.xml<TOPOLOGY-SPECIFIC 配置。
Storm集群表面類似Hadoop集群:
- 在Hadoop上運行的是“MapReduce jobs”,在Storm上運行的是
- “Topologies”。兩者大不相同,一個關鍵不同是一個MapReduce的Job
最終會結束,而一個Topology永遠處理消息(或直到kill它)。
- Storm集群有兩種節點:控制(Master)節點和工作者(Worker)節點。
- 控制節點運行一個稱之為“Nimbus”的後臺程序,負責在集群範圍內分
發代碼、為worker分配任務和故障監測。
- 每個工作者節點運行一個稱之“Supervisor”的後臺程序,監聽分配給它
所在機器的工作,基於Nimbus分配給它的事情來決定啟動或停止工作者進程。
Storm工作流程如圖2-6所示:
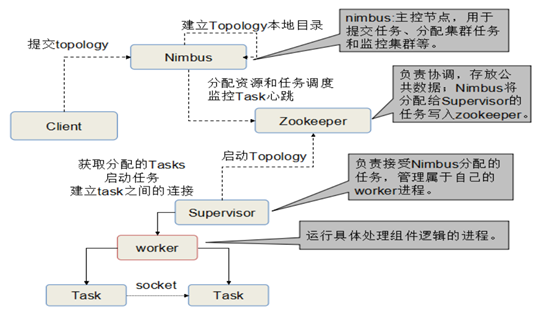
圖2-6 Storm工作流程
2.1.2 Storm特征
Storm 在官方網站中列舉了它的幾大關鍵特征。
● 適用場景廣:Storm 可以用來處理消息和更新數據庫(消息的流處理),對一個數據量進行持續的查詢並將結果返回給客戶端(連續計算),對於耗費資源的查詢進行並行化處理(分布式方法調用),Storm 提供的計算原語可以滿足諸如以上所述的大量場景。
● 可伸縮性強:Storm 的可伸縮性可以讓Storm 每秒處理的消息量達到很高,如100 萬。實現計算任務的擴展,只需要在集群中添加機器,然後提高計算任務的並行度設置。Storm 網站上給出了一個具有伸縮性的例子,一個Storm應用在一個包含10 個節點的集群上每秒處理1 000 000 個消息,其中包括每秒100 多次的數據庫調用。Storm 使用Apache ZooKeeper 來協調集群中各種配置的同步,這樣Storm 集群可以很容易地進行擴展。
● 保證數據不丟失:實時計算系統的關鍵就是保證數據被正確處理,丟失數據的系統使用場景會很窄,而Storm 可以保證每一條消息都會被處理,這是Storm 區別於S4(Yahoo 開發的實時計算系統)系統的關鍵特征。
● 健壯性強:不像Hadoop 集群很難進行管理,它需要管理人員掌握很多Hadoop 的配置、維護、調優的知識。而Storm 集群很容易進行管理,容易管理是Storm 的設計目標之一。
● 高容錯:Storm 可以對消息的處理過程進行容錯處理,如果一條消息在處理過程中失敗,那麽Storm 會重新安排出錯的處理邏輯。Storm 可以保證一個處理邏輯永遠運行。
● 語言無關性:Storm 應用不應該只能使用一種編程平臺,Storm 雖然是使用Clojure 語言開發實現,但是,Storm 的處理邏輯和消息處理組件都可以使用任何語言來進行定義,這就是說任何語言的開發者都可以使用Storm。默認支持Clojure、Java、Ruby和Python。要增加對其他語言的支持,只需要實現一個簡單的額Storm通信協議即可。
2.1.3 Storm容錯處理
Storm 的容錯分為如下幾種類型。
(1)工作進程worker 失效:如果一個節點的工作進程worker“死掉”,supervisor 進程會嘗試重啟該worker。如果連續重啟worker 失敗或者worker 不能定期向Nimbus 報告“心跳”,Nimbus 會分配該任務到集群其他的節點上執行。
(2)集群節點失效:如果集群中某個節點失效,分配給該節點的所有任務會因超時而失敗,Nimbus 會將分配給該節點的所有任務重新分配給集群中的其他節點。
(3)Nimbus 或者supervisor 守護進程失敗:Nimbus 和supervisor 都被設計成快速失敗(遇到未知錯誤時迅速自我失敗)和無狀態的(所有的狀態信息都保存在Zookeeper 上或者是磁盤上)。Nimbus 和supervisor 守護進程必須在一些監控工具(例如,daemontools 或者monitor)的輔助下運行,一旦Nimbus 或者supervisor 失敗,可以立刻重啟它們,整個集群就好像什麽事情也沒發生。最重要的是,沒有工作進程worker 會因為Nimbus 或supervisor 的失敗而受到影響,Storm 的這個特性和Hadoop 形成了鮮明的對比,如果JobTracker 失效,所有的任務都會失敗。
(4)Nimbus 所在的節點失效:如果Nimbus 守護進程駐留的節點失敗,工作節點上的工作進程worker 會繼續執行計算任務,而且,如果worker 進程失敗,supervisor 進程會在該節點上重啟失敗的worker 任務。但是,沒有Nimbus的影響時,所有worker 任務不會分配到其他的工作節點機器上,即使該worker所在的機器失效。
2.1.4 Storm 典型應用場景
Storm 有許多應用領域,包括實時分析、在線機器學習、信息流處理(例如,可以使用Storm 處理新的數據和快速更新數據庫)、連續性的計算(例如,使用Storm 連續查詢,然後將結果返回給客戶端,如將微博上的熱門話題轉發給用戶)、分布式RPC(遠過程調用協議,通過網絡從遠程計算機程序上請求服務)、ETL(Extraction Transformation Loading,數據抽取、轉換和加載)等。
2.1.5 Storm處理性能
Storm 的處理速度驚人,經測試,每個節點每秒可以處理100 萬個數據元組。Storm 可擴展且具有容錯功能,很容易設置和操作。Storm 集成了隊列和數據庫技術,Storm 拓撲網絡通過綜合的方法,將數據流在每個數據平臺間進行重新分配。
流處理