
python爬蟲從入門到放棄(六)之 BeautifulSoup庫的使用
上一篇文章的正則,其實對很多人來說用起來是不方便的,加上需要記很多規則,所以用起來不是特別熟練,而這節我們提到的beautifulsoup就是一個非常強大的工具,爬蟲利器。
beautifulSoup “美味的湯,綠色的濃湯”
一個靈活又方便的網頁解析庫,處理高效,支持多種解析器。
利用它就不用編寫正則表達式也能方便的實現網頁信息的抓取
快速使用
通過下面的一個例子,對bs4有個簡單的了解,以及看一下它的強大之處:
from bs4 import BeautifulSoup html = ‘‘‘ <html><head><title>The Dormouse‘s story</title></head> <body> <p class="title"><b>The Dormouse‘s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p>‘‘‘ soup = BeautifulSoup(html,‘lxml‘) print(soup.prettify()) print(soup.title) print(soup.title.name) print(soup.title.string) print(soup.title.parent.name) print(soup.p) print(soup.p["class"]) print(soup.a) print(soup.find_all(‘a‘)) print(soup.find(id=‘link3‘))
結果如下:

使用BeautifulSoup解析這段代碼,能夠得到一個 BeautifulSoup 的對象,並能按照標準的縮進格式的結構輸出。
同時我們通過下面代碼可以分別獲取所有的鏈接,以及文字內容:
for link in soup.find_all(‘a‘): print(link.get(‘href‘)) print(soup.get_text())
解析器
Beautiful Soup支持Python標準庫中的HTML解析器,還支持一些第三方的解析器,如果我們不安裝它,則 Python 會使用 Python默認的解析器,lxml 解析器更加強大,速度更快,推薦安裝。
下面是常見解析器:
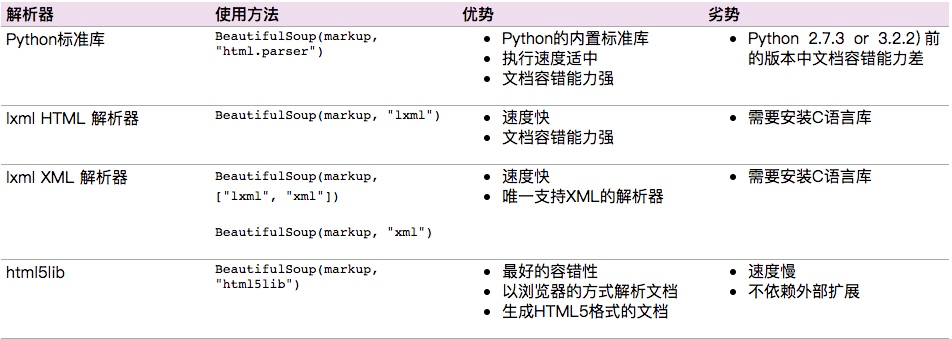
推薦使用lxml作為解析器,因為效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必須安裝lxml或html5lib, 因為那些Python版本的標準庫中內置的HTML解析方法不夠穩定.
基本使用
標簽選擇器
在快速使用中我們添加如下代碼:
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
通過這種soup.標簽名 我們就可以獲得這個標簽的內容
這裏有個問題需要註意,通過這種方式獲取標簽,如果文檔中有多個這樣的標簽,返回的結果是第一個標簽的內容,如上面我們通過soup.p獲取p標簽,而文檔中有多個p標簽,但是只返回了第一個p標簽內容
獲取名稱
當我們通過soup.title.name的時候就可以獲得該title標簽的名稱,即title
獲取屬性
print(soup.p.attrs[‘name‘])
print(soup.p[‘name‘])
上面兩種方式都可以獲取p標簽的name屬性值
獲取內容
print(soup.p.string)
結果就可以獲取第一個p標簽的內容:
The Dormouse‘s story
嵌套選擇
我們直接可以通過下面嵌套的方式獲取
print(soup.head.title.string)
子節點和子孫節點
contents的使用
通過下面例子演示:
html = """ <html> <head> <title>The Dormouse‘s story</title> </head> <body> <p class="story"> Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"> <span>Elsie</span> </a> <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well. </p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html,‘lxml‘) print(soup.p.contents)
結果是將p標簽下的所有子標簽存入到了一個列表中
列表中會存入如下元素
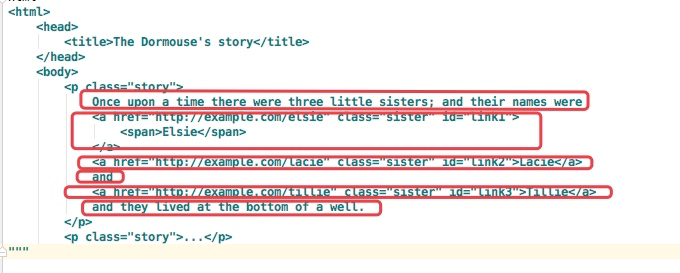
children的使用
通過下面的方式也可以獲取p標簽下的所有子節點內容和通過contents獲取的結果是一樣的,但是不同的地方是soup.p.children是一個叠代對象,而不是列表,只能通過循環的方式獲取素有的信息
print(soup.p.children) for i,child in enumerate(soup.p.children): print(i,child)
通過contents以及children都是獲取子節點,如果想要獲取子孫節點可以通過descendants
print(soup.descendants)同時這種獲取的結果也是一個叠代器
父節點和祖先節點
通過soup.a.parent就可以獲取父節點的信息
通過list(enumerate(soup.a.parents))可以獲取祖先節點,這個方法返回的結果是一個列表,會分別將a標簽的父節點的信息存放到列表中,以及父節點的父節點也放到列表中,並且最後還會講整個文檔放到列表中,所有列表的最後一個元素以及倒數第二個元素都是存的整個文檔的信息
兄弟節點
soup.a.next_siblings 獲取後面的兄弟節點
soup.a.previous_siblings 獲取前面的兄弟節點
soup.a.next_sibling 獲取下一個兄弟標簽
souo.a.previous_sinbling 獲取上一個兄弟標簽
標準選擇器
find_all
find_all(name,attrs,recursive,text,**kwargs)
可以根據標簽名,屬性,內容查找文檔
name的用法
html=‘‘‘ <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ‘‘‘ from bs4 import BeautifulSoup soup = BeautifulSoup(html, ‘lxml‘) print(soup.find_all(‘ul‘)) print(type(soup.find_all(‘ul‘)[0]))
結果返回的是一個列表的方式

同時我們是可以針對結果再次find_all,從而獲取所有的li標簽信息
for ul in soup.find_all(‘ul‘): print(ul.find_all(‘li‘))
attrs
例子如下:
html=‘‘‘ <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1" name="elements"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ‘‘‘ from bs4 import BeautifulSoup soup = BeautifulSoup(html, ‘lxml‘) print(soup.find_all(attrs={‘id‘: ‘list-1‘})) print(soup.find_all(attrs={‘name‘: ‘elements‘}))
attrs可以傳入字典的方式來查找標簽,但是這裏有個特殊的就是class,因為class在python中是特殊的字段,所以如果想要查找class相關的可以更改attrs={‘class_‘:‘element‘}或者soup.find_all(‘‘,{"class":"element}),特殊的標簽屬性可以不寫attrs,例如id,class等
text
例子如下:
html=‘‘‘ <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ‘‘‘ from bs4 import BeautifulSoup soup = BeautifulSoup(html, ‘lxml‘) print(soup.find_all(text=‘Foo‘))
結果返回的是查到的所有的text=‘Foo‘的文本

find
find(name,attrs,recursive,text,**kwargs)
find返回的匹配結果的第一個元素
其他一些類似的用法:
find_parents()返回所有祖先節點,find_parent()返回直接父節點。
find_next_siblings()返回後面所有兄弟節點,find_next_sibling()返回後面第一個兄弟節點。
find_previous_siblings()返回前面所有兄弟節點,find_previous_sibling()返回前面第一個兄弟節點。
find_all_next()返回節點後所有符合條件的節點, find_next()返回第一個符合條件的節點
find_all_previous()返回節點後所有符合條件的節點, find_previous()返回第一個符合條件的節點
CSS選擇器
通過select()直接傳入CSS選擇器就可以完成選擇
熟悉前端的人對CSS可能更加了解,其實用法也是一樣的
.表示class #表示id
標簽1,標簽2 找到所有的標簽1和標簽2
標簽1 標簽2 找到標簽1內部的所有的標簽2
[attr] 可以通過這種方法找到具有某個屬性的所有標簽
[atrr=value] 例子[target=_blank]表示查找所有target=_blank的標簽
html=‘‘‘ <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ‘‘‘ from bs4 import BeautifulSoup soup = BeautifulSoup(html, ‘lxml‘) print(soup.select(‘.panel .panel-heading‘)) print(soup.select(‘ul li‘)) print(soup.select(‘#list-2 .element‘)) print(type(soup.select(‘ul‘)[0]))
獲取內容
通過get_text()就可以獲取文本內容
html=‘‘‘ <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ‘‘‘ from bs4 import BeautifulSoup soup = BeautifulSoup(html, ‘lxml‘) for li in soup.select(‘li‘): print(li.get_text())
獲取屬性
或者屬性的時候可以通過[屬性名]或者attrs[屬性名]
html=‘‘‘ <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ‘‘‘ from bs4 import BeautifulSoup soup = BeautifulSoup(html, ‘lxml‘) for ul in soup.select(‘ul‘): print(ul[‘id‘]) print(ul.attrs[‘id‘])
總結
推薦使用lxml解析庫,必要時使用html.parser
標簽選擇篩選功能弱但是速度快
建議使用find()、find_all() 查詢匹配單個結果或者多個結果
如果對CSS選擇器熟悉建議使用select()
記住常用的獲取屬性和文本值的方法
python爬蟲從入門到放棄(六)之 BeautifulSoup庫的使用