
深入理解JAVA集合系列三:HashMap的死循環解讀
由於在公司項目中偶爾會遇到HashMap死循環造成CPU100%,重啟後問題消失,隔一段時間又會反復出現。今天在這裏來仔細剖析下多線程情況下HashMap所帶來的問題:
1、多線程put操作後,get操作導致死循環。
2、多線程put非null元素後,get操作得到null值。
3、多線程put操作,導致元素丟失。
死循環場景重現
下面我用一段簡單的DEMO模擬HashMap死循環:

1 public class Test extends Thread
2 {
3 static HashMap<Integer, Integer> map = new HashMap<Integer, Integer>(2);
4 static AtomicInteger at = new AtomicInteger();
5
6 public void run()
7 {
8 while(at.get() < 100000)
9 {
10 map.put(at.get(),at.get());
11 at.incrementAndGet();
12 }
13 }
其中map和at都是static的,即所有線程所共享的資源。接著5個線程並發操作該HashMap:
1 public static void main(String[] args)
2 {
3 Test t0 = new Test();
4 Test t1 = new Test();
5 Test t2 = new Test();
6 Test t3 = new Test();
7 Test t4 = new Test();
8 t0.start();
9 t1.start();
10 t2.start();
11 t3.start();
12 t4.start();
13 }
反復執行幾次,出現這種情況則表示死循環了:

接下來我們去查看下CPU以及堆棧情況:
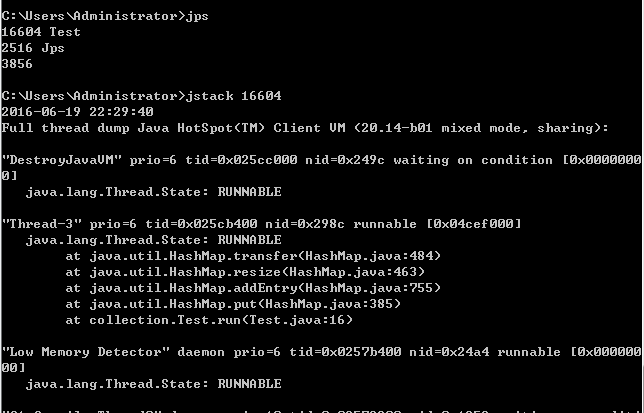
通過堆棧可以看到:Thread-3由於HashMap的擴容操作導致了死循環。
正常的擴容過程
我們先來看下單線程情況下,正常的rehash過程
1、假設我們的hash算法是簡單的key mod一下表的大小(即數組的長度)。
2、最上面是old hash表,其中HASH表的size=2,所以key=3,5,7在mod 2 以後都沖突在table[1]這個位置上了。
3、接下來HASH表擴容,resize=4,然後所有的<key,value>重新進行散列分布,過程如下:
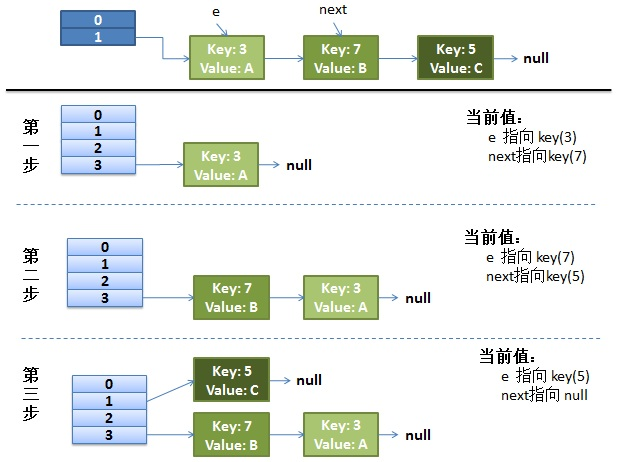
在單線程情況下,一切看起來都很美妙,擴容過程也相當順利。接下來看下並發情況下的擴容。
並發情況下的擴容
1、首先假設我們有兩個線程,分別用紅色和藍色標註了。
2、擴容部分的源代碼:
1 void transfer(Entry[] newTable) {
2 Entry[] src = table;
3 int newCapacity = newTable.length;
4 for (int j = 0; j < src.length; j++) {
5 Entry<K,V> e = src[j];
6 if (e != null) {
7 src[j] = null;
8 do {
9 Entry<K,V> next = e.next;
10 int i = indexFor(e.hash, newCapacity);
11 e.next = newTable[i];
12 newTable[i] = e;
13 e = next;
14 } while (e != null);
15 }
16 }
17 }
3、如果在線程一執行到第9行代碼就被CPU調度掛起,去執行線程2,且線程2把上面代碼都執行完畢。我們來看看這個時候的狀態:
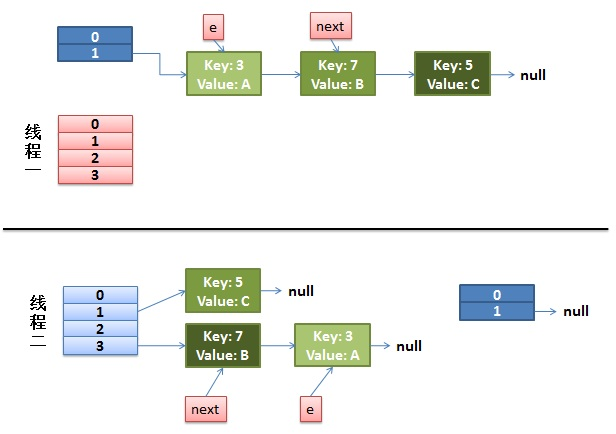
4、接著CPU切換到線程一上來,執行8-14行代碼,首先安置3這個Entry:
這裏需要註意的是:線程二已經完成執行完成,現在table裏面所有的Entry都是最新的,就是說7的next是3,3的next是null;現在第一次循環已經結束,3已經安置妥當。看看接下來會發生什麽事情:
1、e=next=7;
2、e!=null,循環繼續
3、next=e.next=3
4、e.next 7的next指向3
5、放置7這個Entry,現在如圖所示:

放置7之後,接著運行代碼:
1、e=next=3;
2、判斷不為空,繼續循環
3、next= e.next 這裏也就是3的next 為null
4、e.next=7,就3的next指向7.
5、放置3這個Entry,此時的狀態如圖:
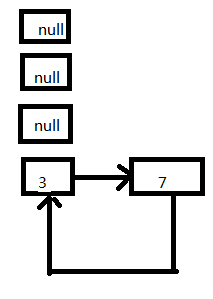
這個時候其實就出現了死循環了,3移動節點頭的位置,指向7這個Entry;在這之前7的next同時也指向了3這個Entry。
代碼接著往下執行,e=next=null,此時條件判斷會終止循環。這次擴容結束了。但是後續如果有查詢(無論是查詢的叠代還是擴容),都會hang死在table【3】這個位置上。現在回過來看文章開頭的那個Demo,就是掛死在擴容階段的transfer這個方法上面。
出現上面這種情況絕不是我要在測試環境弄一批數據專門為了演示這種問題。我們仔細思考一下就會得出這樣一個結論:如果擴容前相鄰的兩個Entry在擴容後還是分配到相同的table位置上,就會出現死循環的BUG。在復雜的生產環境中,這種情況盡管不常見,但是可能會碰到。
多線程put操作,導致元素丟失
下面來介紹下元素丟失的問題。這次我們選取3、5、7的順序來演示:
1、如果在線程一執行到第9行代碼就被CPU調度掛起:
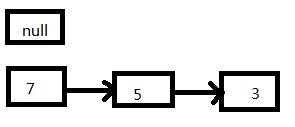
2、線程二執行完成:
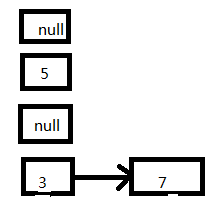
3、這個時候接著執行線程一,首先放置7這個Entry:
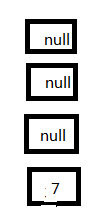
4、再放置5這個Entry:
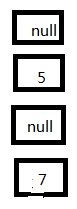
5、由於5的next為null,此時擴容動作結束,導致3這個Entry丟失。
其他
這個問題當初有人上報到SUN公司,不過SUN不認為這是一個問題。因為HashMap本來就不支持並發。
如果大家想在並發場景下使用HashMap,有兩種解決方法:
1、使用ConcurrentHashMap。
2、使用Collections.synchronizedMap(Mao<K,V> m)方法把HashMap變成一個線程安全的Map。
深入理解JAVA集合系列三:HashMap的死循環解讀