
PyCharm+Eclipse共用Anaconda的數據科學環境
阿新 • • 發佈:2017-06-02
ctrl+ 程序 cache height from 環境 nac rip 指定 

 或者按下面的方式展開
或者按下面的方式展開
4.復制pyspark的包

1.安裝anaconda2
安裝好之後,本地python環境就采用anaconda自帶的python2.7的環境。
2.安裝py4j
在本地ctrl+r打開控制臺後,直接使用pip安裝py4j,因為anaconda默認是安裝了pip的,當然也可以使用conda安裝。
安裝命令:pip install py4j
如果不安裝py4j可能出現的問題?
答:因為Spark的Python版本的API依賴於py4j,如果不安裝運行程序會拋出如下錯誤。
3.配置環境變量
配置PyCharm的環境變量主要配置兩個變量一個是SPARK_HOME,另外一個是PYTHONPATH。(1).先打開Run Configurations
(2).編輯Environment variables
或者按下面的方式展開
菜單:File-->Settings (圖來源於互聯網~這裏我用的是python2)

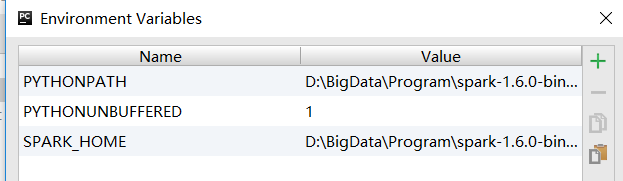
(3).在Environment variables下增加spark和python的環境
增加SPARK_HOME目錄與PYTHONPATH目錄。
- SPARK_HOME:Spark安裝目錄
- PYTHONPATH:Spark安裝目錄下的Python目錄
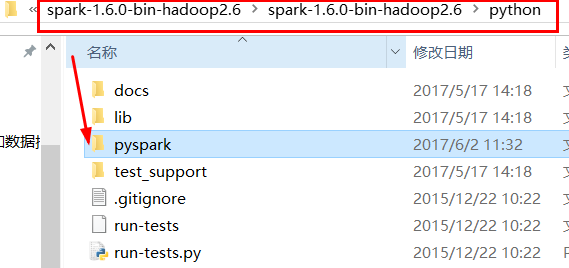
4.復制pyspark的包
編寫Spark程序,復制pyspark的包,增加代碼顯示功能
為了讓我們在PyCharm編寫Spark程序時有代碼提示和補全功能,需要將Spark的pyspark導入到Python中。在Spark的程序中有Python的包,叫做pyspark
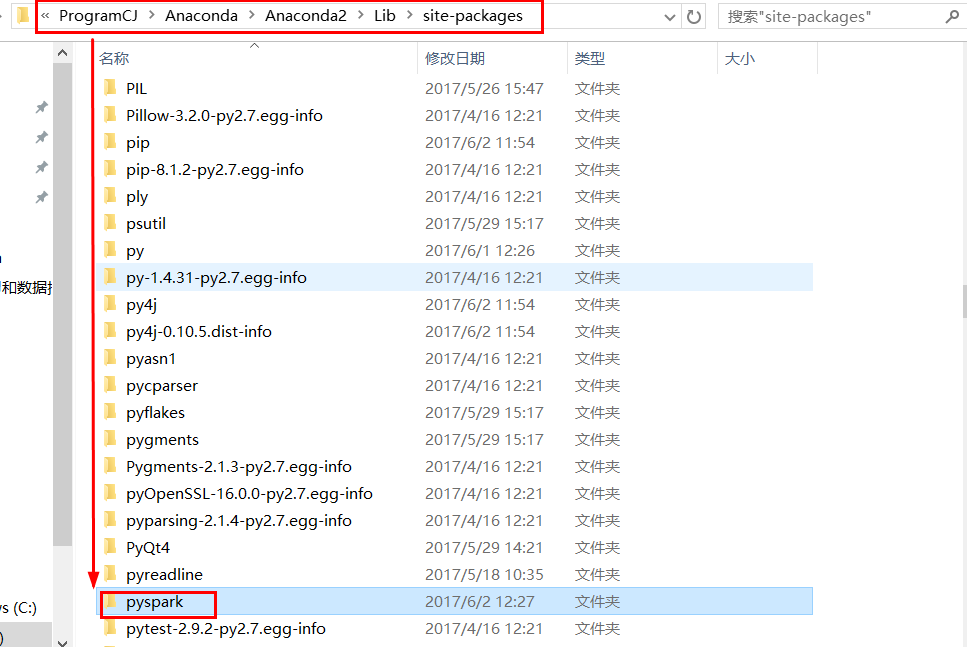
pyspark包
Python導入第三方的包也很容易,只需要把相應的模塊導入到指定的文件夾就可以了。
windows中將pyspark拷貝到Python的site-packages目錄下(這裏使用的是anaconda)
5.測試代碼
import sys
from operator import add
from pyspark import SparkContext
logFile = "D:\\BigData\\Workspace\\PycharmProjects\\MachineLearning1\\word.txt"
sc = SparkContext("local", "PythonWordCount")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: ‘a‘ in s).count()
numBs = logData.filter(lambda s: ‘b‘ in s).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
PyCharm+Eclipse共用Anaconda的數據科學環境