
shell第四篇(下)
摘自王垠的:Unix的缺陷
我想通過這篇文章解釋一下我對 Unix 哲學本質的理解。我雖然指出 Unix 的一個設計問題,但目的並不是打擊人們對 Unix 的興趣。雖然 Unix 在基礎概念上有一個挺嚴重的問題,但是經過多年的發展之後,這個問題恐怕已經被各種別的因素所彌補(比如大量的人力)。但是如果開始正視這個問題,我們也許就可以緩慢的改善系統的結構,從而使得它用起來更加高效,方便和安全,那又未嘗不可。同時也希望這裏對 Unix 命令本質的闡述能幫助人迅速的掌握 Unix,靈活的應用它的潛力,避免它的缺點。
通常所說的“Unix哲學”包括以下三條原則[Mcllroy]:
1、一個程序只做一件事情,並且把它做好。
2、程序之間能夠協同工作。
3、程序處理文本流,因為它是一個通用的接口。
這三條原則當中,前兩條其實早於 Unix 就已經存在,它們描述的其實是程序設計最基本的原則——模塊化原則。任何一個具有函數和調用的程序語言都具有這兩條原則。簡言之,第一條針對函數,第二條針對調用。所謂“程序”,其實是一個叫 “main” 的函數(詳見下文)。
所以只有第三條(用文本流做接口)是 Unix 所特有的。下文的“Unix哲學”如果不加修飾,就特指這第三條原則。但是許多的事實已經顯示出,這第三條原則其實包含了實質性的錯誤。它不但一直在給我們制造無需有的問題,並且在很大程度上破壞前兩條原則的實施。然而,這條原則卻被很多人奉為神聖。許多程序員在他們自己的程序和協議裏大量的使用文本流來表示數據,引發了各種頭痛的問題,卻對此視而不見。
Linux 有它優於 Unix 的革新之處,但是我們必須看到,它其實還是繼承了 Unix 的這條哲學。Linux 系統的命令行,配置文件,各種工具之間都通過非標準化的文本流傳遞數據。這造成了信息格式的不一致和程序間協作的困難。然而,我這樣說並不等於 Windows 或者 Mac 就做得好很多,雖然它們對此有所改進。實際上,幾乎所有常見的操作系統都受到 Unix 哲學潛移默化的影響,以至於它們身上或多或少都存在它的陰影。
Unix 哲學的影響是多方面的。從命令行到程序語言,到數據庫,Web…… 計算機和網絡系統的方方面面無不顯示出它的影子。在這裏,我會把眾多的問題與它們的根源——Unix哲學相關聯。現在我就從最簡單的命令行開始吧,希望你能從這些最簡單例子裏看到 Unix 執行命令的過程,以及其中存在的問題。(文本流的實質就是字符串,所以在下文裏這兩個名詞通用。)
一個 Linux 命令運行的基本過程
幾乎每個 Linux 用戶都為它的命令行困惑過。很多人(包括我在內)用了好幾年 Linux 也沒有完全的掌握命令行的用法。雖然看文檔看書以為都看透了,到時候還是會出現莫名其妙的問題,有時甚至會耗費大半天的時間在上面。其實如果看透了命令行的本質,你就會發現很多問題其實不是用戶的錯。Linux 遺傳了 Unix 的“哲學”,用文本流來表示數據和參數,才導致了命令行難學難用。
我們首先來分析一下 Linux 命令行的工作原理吧。下圖是一個很簡單的 Linux 命令運行的過程。當然這不是全過程,但是更具體的細節跟我現在要說的主題無關。
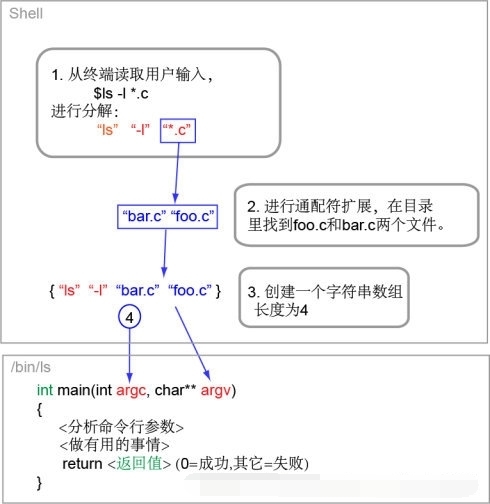
從上圖我們可以看到,在 ls 命令運行的整個過程中,發生了如下的事情:
1、shell(在這個例子裏是bash)從終端得到輸入的字符串 “ls -l *.c”。然後 shell 以空白字符為界,切分這個字符串,得到 “ls”, “-l” 和 “*.c” 三個字符串。
2、shell 發現第二個字符串是通配符 “*.c”,於是在當前目錄下尋找與這個通配符匹配的文件。它找到兩個文件: foo.c 和 bar.c。
3、shell 把這兩個文件的名字和其余的字符串一起做成一個字符串數組 {“ls”, “-l”, “bar.c”, “foo.c”}. 它的長度是 4.
4、shell 生成一個新的進程,在裏面執行一個名叫 “ls” 的程序,並且把字符串數組 {“ls”, “-l”, “bar.c”, “foo.c”}和它的長度4,作為ls的main函數的參數。main函數是C語言程序的“入口”,這個你可能已經知道。
5、ls 程序啟動並且得到的這兩個參數(argv,argc)後,對它們做一些分析,提取其中的有用信息。比如 ls 發現字符串數組 argv 的第二個元素 “-l” 以 “-” 開頭,就知道那是一個選項——用戶想列出文件詳細的信息,於是它設置一個布爾變量表示這個信息,以便以後決定輸出文件信息的格式。
6、ls 列出 foo.c 和 bar.c 兩個文件的“長格式”信息之後退出。以整數0作為返回值。
7、shell 得知 ls 已經退出,返回值是 0。在 shell 看來,0 表示成功,而其它值(不管正數負數)都表示失敗。於是 shell 知道 ls 運行成功了。由於沒有別的命令需要運行,shell 向屏幕打印出提示符,開始等待新的終端輸入……
從上面的命令運行的過程中,我們可以看到文本流(字符串)在命令行中的普遍存在:
用戶在終端輸入是字符串。
shell 從終端得到的是字符串,分解之後得到 3 個字符串,展開通配符後得到 4 個字符串。
ls 程序從參數得到那 4 個字符串,看到字符串 “-l” 的時候,就決定使用長格式進行輸出。
接下來你會看到這樣的做法引起的問題。
冰山一角
在《Unix 痛恨者手冊》(The Unix-Hater’s Handbook, 以下簡稱 UHH)這本書開頭,作者列舉了 Unix 命令行用戶界面的一系列罪狀,咋一看還以為是脾氣不好的初學者在謾罵。可是仔細看看,你會發現雖然態度不好,他們某些人的話裏面有非常深刻的道理。我們總是可以從罵我們的人身上學到一些東西,所以仔細看了一下,發現其實這些命令行問題的根源就是“Unix 哲學”——用文本流(字符串)來表示參數和數據。很多人都沒有意識到,文本流的過度使用,引發了太多問題。我會在後面列出這些問題,不過我現在先舉一些最簡單的例子來解釋一下這個問題的本質,你現在就可以自己動手試一下。
這裏列舉的ls實驗,但是我實驗失敗了,下面是實驗過程
在你的 Linux 終端裏執行如下命令(依次輸入:大於號,減號,小寫字母l)。這會在目錄下建立一個叫 “-l” 的文件。
$ >-l
執行命令 ls * (你的意圖是以短格式列出目錄下的所有文件)。
你看到什麽了呢?你沒有給 ls 任何選項,文件卻出人意料的以“長格式”列了出來,而這個列表裏面卻沒有你剛剛建立的那個名叫 “-l” 的文件。比如我得到如下輸出:
-rw-r--r-- 1 wy wy 0 2011-05-22 23:03 bar.c
-rw-r--r-- 1 wy wy 0 2011-05-22 23:03 foo.c
到底發生了什麽呢?重溫一下上面的示意圖吧,特別註意第二步。原來 shell 在調用 ls 之前,把通配符 * 展開成了目錄下的所有文件,那就是 “foo.c”, “bar.c”, 和一個名叫 “-l” 的文件。它把這 3 個字符串加上 ls 自己的名字,放進一個字符串數組 {“ls”, “bar.c”, “foo.c”, “-l”},交給 ls。接下來發生的是,ls 拿到這個字符串數組,發現裏面有個字符串是 “-l”,就以為那是一個選項:用戶想用“長格式”輸出文件信息。因為 “-l” 被認為是選項,就沒有被列出來。於是我就得到上面的結果:長格式,還少了一個文件!
這說明了什麽問題呢?是用戶的錯嗎?高手們也許會笑,怎麽有人會這麽傻,在目錄裏建立一個叫 “-l” 的文件。但是就是這樣的態度,導致了我們對錯誤視而不見,甚至讓它發揚光大。其實撇除心裏的優越感,從理性的觀點看一看,我們就發現這一切都是系統設計的問題,而不是用戶的錯誤
我覺得為了免去責任,一個系統必須提供切實的保障措施,而不只是口頭上的約定來要求用戶“小心”。就像如果你在街上挖個大洞施工,必須放上路障和警示燈。你不能只插一面小旗子在那裏,用一行小字寫著: “前方施工,後果自負。”我想每一個正常人都會判定是施工者的錯誤。
可是 Unix 對於它的用戶卻一直是像這樣的施工者,它要求用戶:“仔細看 man page,否則後果自負。”其實不是用戶想偷懶,而是這些條款太多,根本沒有人能記得住。而且沒被咬過之前,誰會去看那些偏僻的內容啊。但是一被咬,就後悔都來不及。完成一個簡單的任務都需要知道這麽多可能的陷阱,那更加復雜的任務可怎麽辦。其實 Unix 的這些小問題累加起來,不知道讓人耗費了多少寶貴的時間。
、
如果你想更加確信這個問題的危險性,可以試試如下的做法。在這之前,請新建一個測試用的目錄,以免丟失你的文件!
1、在新目錄裏,我們首先建立兩個文件夾 dir-a, dir-b 和三個普通文件 file1,file2 和 “-rf”。然後我們運行 “rm *”,意圖是刪除所有普通文件,而不刪掉目錄。
$ mkdir dir-a dir-b $ touch file1 file2 $ > -rf $ rm *
2、然後用 ls 查看目錄。
你會發現最後只剩下一個文件: “-rf”。本來 “rm *” 只能刪除普通文件,現在由於目錄裏存在一個叫 “-rf” 的文件。rm 以為那是叫它進行強制遞歸刪除的選項,所以它把目錄裏所有的文件連同目錄全都刪掉了(除了 “-rf”)
表面解決方案
難道這說明我們應該禁止任何以 “-” 開頭的文件名的存在,因為這樣會讓程序分不清選項和文件名?可是不幸的是,由於 Unix 給程序員的“靈活性”,並不是每個程序都認為以 “-” 開頭的參數是選項。比如,Linux 下的 tar,ps 等命令就是例外。所以這個方案不大可行。
從上面的例子我們可以看出,問題的來源似乎是因為 ls 根本不知道通配符 * 的存在。是 shell 把通配符展開以後給 ls。其實 ls 得到的是文件名和選項混合在一起的字符串數組。所以 UHH 的作者提出的一個看法:“shell 根本不應該展開通配符。通配符應該直接被送給程序,由程序自己調用一個庫函數來展開。”
這個方案確實可行:如果 shell 把通配符直接給 ls,那麽 ls 會只看到 “*” 一個參數。它會調用庫函數在文件系統裏去尋找當前目錄下的所有文件,它會很清楚的知道 “-l” 是一個文件,而不是一個選項,因為它根本沒有從 shell 那裏得到任何選項(它只得到一個參數:”*”)。所以問題貌似就解決了。
但是這樣每一個命令都自己檢查通配符的存在,然後去調用庫函數來解釋它,大大增加了程序員的工作量和出錯的概率。況且 shell 不但展開通配符,還有環境變量,花括號展開,~展開,命令替換,算術運算展開…… 這些讓每個程序都自己去做?這恰恰違反了第一條 Unix 哲學——模塊化原則。而且這個方法並不是一勞永逸的,它只能解決這一個問題。我們還將遇到文本流引起的更多的問題,它們沒法用這個方法解決。下面就是一個這樣的例子。
冰山又一角
這些看似微不足道的問題裏面其實包含了 Unix 本質的問題。如果不能正確認識到它,我們跳出了一個問題,還會進入另一個。我講一個自己的親身經歷吧。我前年夏天在 Google 實習快結束的時候發生了這樣一件事情……
由於我的項目對一個開源項目的依賴關系,我必須在 Google 的 Perforce 代碼庫中提交這個開源項目的所有文件。這個開源項目裏面有 9000 多個文件,而 Perforce 是如此之慢,在提交進行到一個小時的時候,突然報錯退出了,說有兩個文件找不到。又試了兩次(順便出去喝了咖啡,打了臺球),還是失敗,這樣一天就快過去了。於是我搜索了一下這兩個文件,確實不存在。怎麽會呢?我是用公司手冊上的命令行把項目的文件導入到 Perforce 的呀,怎麽會無中生有?這條命令是這樣:
find -name *.java -print | xargs p4 add
它的工作原理是,find 命令在目錄樹下找到所有的以 “.java” 結尾的文件,把它們用空格符隔開做成一個字符串,然後交給 xargs。之後 xargs 以空格符把這個字符串拆開成多個字符串,放在 “p4 add” 後面,組合成一條命令,然後執行它。基本上你可以把 find 想象成 Lisp 裏的 “filter”,而 xargs 就是 “map”。所以這條命令轉換成 Lisp 樣式的偽碼就是:
(map (lambda (x) (p4 add x)) (filter (lambda (x) (regexp-match? "*.java" x)) (files-in-current-dir)))
問題出在哪裏呢?經過一下午的困惑之後我終於發現,原來這個開源項目裏某個目錄下,有一個叫做 “App Launcher.java” 的文件。由於它的名字裏面含有一個空格,被 xargs 拆開成了兩個字符串: “App” 和 “Launcher.java”。當然這兩個文件都不存在了!所以 Perforce 在提交的時候抱怨找不到它們。我告訴組裏的負責人這個發現後,他說:“這些家夥,怎麽能給 Java 程序起這樣一個名字?也太菜了吧!”
但是我卻不認為是這個開源項目的程序員的錯誤,這其實顯示了 Unix 的問題。這個問題的根源是因為 Unix 的命令 (find, xargs) 把文件名以字符串的形式傳遞,它們默認的“協議”是“以空格符隔開文件名”。而這個項目裏恰恰有一個文件的名字裏面有空格符,所以導致了歧義的產生。該怪誰呢?既然 Linux 允許文件名裏面有空格,那麽用戶就有權使用這個功能。到頭來因此出了問題,用戶卻被叫做菜鳥,為什麽自己不小心,不看 man page。
後來我仔細看了一下 find 和 xargs 的 man page,發現其實它們的設計者其實已經意識到這個問題。所以 find 和 xargs 各有一個選項:”-print0″ 和 “-0″。它們可以讓 find 和 xargs 不用空格符,而用 “NULL”(ASCII字符 0)作為文件名的分隔符,這樣就可以避免文件名裏有空格導致的問題。可是,似乎每次遇到這樣的問題總是過後方知。難道用戶真的需要知道這麽多,小心翼翼,才能有效的使用 Unix 嗎?
文本流不是可靠的接口
這些例子其實從不同的側面顯示了同一個本質的問題:用文本流來傳遞數據有嚴重的問題。是的,文本流是一個“通用”的接口,但是它卻不是一個“可靠”或者“方便”的接口。Unix 命令的工作原理基本是這樣:
●從標準輸入得到文本流,處理,向標準輸出打印文本流。
●程序之間用管道進行通信,讓文本流可以在程序間傳遞。
這其中主要有兩個過程:
1、程序向標準輸出“打印”的時候,數據被轉換成文本。這是一個編碼過程。
2、文本通過管道(或者文件)進入另一個程序,這個程序需要從文本裏面提取它需要的信息。這是一個解碼過程。
編碼的貌似很簡單,你只需要隨便設計一個“語法”,比如“用空格隔開”,就能輸出了。可是編碼的設計遠遠不是想象的那麽容易。要是編碼格式沒有設計好,解碼的人就麻煩了,輕則需要正則表達式才能提取出文本裏的信息,遇到復雜一點的編碼(比如程序文本),就得用 parser。最嚴重的問題是,由於鼓勵使用文本流,很多程序員很隨意的設計他們的編碼方式而不經過嚴密思考。這就造成了 Unix 的幾乎每個程序都有各自不同的輸出格式,使得解碼成為非常頭痛的問題,經常出現歧義和混淆。
上面 find/xargs 的問題就是因為 find 編碼的分隔符(空格)和文件名裏可能存在的空格相混淆——此空格非彼空格也。而之前的 ls 和 rm 的問題就是因為 shell 把文件名和選項都“編碼”為“字符串”,所以 ls 程序無法通過解碼來辨別它們的到底是文件名還是選項——此字符串非彼字符串也!
如果你使用過 Java 或者函數式語言(Haskell 或者 ML),你可能會了解一些類型理論(type theory)。在類型理論裏,數據的類型是多樣的,Integer, String, Boolean, List, record…… 程序之間傳遞的所謂“數據”,只不過就是這些類型的數據結構。然而按照 Unix 的設計,所有的類型都得被轉化成 String 之後在程序間傳遞。這樣帶來一個問題:由於無結構的 String 沒有足夠的表達力來區分其它的數據類型,所以經常會出現歧義。相比之下,如果用 Haskell 來表示命令行參數,它應該是這樣:
Shell data Parameter = Option String | File String | ... 1 data Parameter = Option String | File String | ...
雖然兩種東西的實質都是 String,但是 Haskell 會給它們加上“標簽”以區分 Option 還是 File。這樣當 ls 接收到參數列表的時候,它就從標簽判斷哪個是選項,哪個是參數,而不是通過字符串的內容來瞎猜。
文本流帶來太多的問題
綜上所述,文本流的問題在於,本來簡單明了的信息,被編碼成為文本流之後,就變得難以提取,甚至丟失。前面說的都是小問題,其實文本流的帶來的嚴重問題很多,它甚至創造了整個的研究領域。文本流的思想影響了太多的設計。比如:
●配置文件:幾乎每一個都用不同的文本格式保存數據。想想吧:.bashrc, .Xdefaults, .screenrc, .fvwm, .emacs, .vimrc, /etc目錄下那系列!這樣用戶需要了解太多的格式,然而它們並沒有什麽本質區別。為了整理好這些文件,花費了大量的人力物力。
●程序文本:這個以後我會專門講。程序被作為文本文件,所以我們才需要 parser。這導致了整個編譯器領域花費大量人力物力研究 parsing。其實程序完全可以被作為 parse tree 直接存儲,這樣編譯器可以直接讀取 parse tree,不但節省編譯時間,連 parser 都不用寫。
●數據庫接口:程序與關系式數據庫之間的交互使用含有 SQL 語句的字符串,由於字符串裏的內容跟程序的類型之間並無關聯,導致了這種程序非常難以調試。
●XML: 設計的初衷就是解決數據編碼的問題,然而不幸的是,它自己都難 parse。它跟 SQL 類似,與程序裏的類型關聯性很差。程序裏的類型名字即使跟 XML 裏面的定義有所偏差,編譯器也不會報錯。Android 程序經常出現的 “force close”,大部分時候是這個原因。與 XML 相關的一些東西,比如 XSLT, XQuery, XPath 等等,設計也非常糟糕。
●Web:JavaScript 經常被作為字符串插入到網頁中。由於字符串可以被任意組合,這引起很多安全性問題。Web安全研究,有些就是解決這類問題的。
●IDE接口:很多編譯器給編輯器和 IDE 提供的接口是基於文本的。編譯器打印出出錯的行號和信息,比如 “102:32 variable x undefined”,然後由編輯器和 IDE 從文本裏面去提取這些信息,跳轉到相應的位置。一旦編譯器改變打印格式,這些編輯器和 IDE 就得修改。
●log分析: 有些公司調試程序的時候打印出文本 log 信息,然後專門請人寫程序分析這種 log,從裏面提取有用的信息,非常費時費力。
●測試:很多人寫 unit test 的時候,喜歡把數據結構通過 toString 等函數轉化成字符串之後,與一個標準的字符串進行比較,導致這些測試在字符串格式改變之後失效而必須修改。
還有很多的例子,你只需要在你的身邊去發現。
什麽是“人類可讀”和“通用”接口?
當我提到文本流做接口的各種弊端時,經常有人會指出,雖然文本流不可靠又麻煩,但是它比其它接口更通用,因為它是唯一人類可讀 (human-readable) 的格式,任何編輯器都可以直接看到文本流的內容,而其它格式都不是這樣的。對於這一點我想說的是:
1、什麽叫做“人類可讀”?文本流真的就是那麽的可讀嗎?幾年前,普通的文本編輯器遇到中文的時候經常亂碼,要折騰好一陣子才能讓它們支持中文。幸好經過全世界的合作,我們現在有了 Unicode。
2、現在要閱讀 Unicode 的文件,你不但要有支持 Unicode 的編輯器/瀏覽器,你還得有能顯示相應碼段的字體。文本流達到“人類可讀”真的不費力氣?
3、除了文本流,其實還有很多人類可讀的格式,比如 JPEG。它可比文本流“可讀”和“通用”多了,連字體都用不著。
所以,文本流的根本就不是“人類可讀”和“通用”的關鍵。真正的關鍵在於“標準化”。如果其它的數據類型被標準化,那麽我們可以在任何編輯器,瀏覽器,終端裏加入對它們的支持,完全達到人類和機器都可輕松讀取,就像我們今天讀取文本和 JPEG 一樣。
解決方案
其實有一個簡單的方式可以一勞永逸的解決所有這些問題:
1、保留數據類型本來的結構。不用文本流來表示除文本以外的數據。
2、用一個開放的,標準化的,可擴展的方式來表示所有數據類型。
3、程序之間的數據傳遞和存儲,就像程序內部的數據結構一樣。
Unix 命令行的本質
雖然文本流引起了這麽多問題,但是 Unix 還是不會消亡,因為畢竟有這麽多的上層應用已經依賴於它,它幾乎是整個 Internet 的頂梁柱。所以這篇文章對於當前狀況的一個實際意義,也許是可以幫助人們迅速的理解 Unix 的命令行機制,並且鼓勵程序員在新的應用中使用結構化的數據。
Unix 命令雖然過於復雜而且功能冗余,但是如果你看透了它們的本質,就能輕而易舉的學會它們的使用方法。簡而言之,你可以用普通的編程思想來解釋所有的 Unix 命令:
1、函數:每一個 Unix 程序本質上是一個函數 (main)。
2、參數:命令行參數就是這個函數的參數。 所有的參數對於 C 語言來說都是字符串,但是經過 parse,它們可能有幾種不同的類型:
1、變量名:實際上文件名就是程序中的變量名,就像 x, y。而文件的本質就是程序裏的一個對象。
2、字符串:這是真正的程序中的字符串,就像 “hello world”。
3、keyword argument: 選項本質上就是“keyword argument”(kwarg),類似 Python 或者 Common Lisp 裏面那個對應的東西,短選項(看起來像 “-l”, “-c” 等等),本質上就是 bool 類型的 kwarg。比如 “ls -l” 以 Python 的語法就是 ls(l=true)。長選項本質就是 string 類型的 kwarg。比如 “ls –color=auto” 以 Python 的語法就是 ls(color=auto)。
3、返回值:由於 main 函數只能返回整數類型(int),我們只好把其它類型 (string, list, record, …) 的返回值序列化為文本流,然後通過文件送給另一個程序。這裏“文件”通指磁盤文件,管道等等。它們是文本流通過的信道。我已經提到過,文件的本質是程序裏的一個對象。
4、組合:所謂“管道”,不過是一種簡單的函數組合(composition)。比如 “A x | B”,用函數來表示就是 “B(A(x))”。 但是註意,這裏的計算過程,本質上是 lazy evaluation (類似 Haskell)。當 B “需要”數據的時候,A 才會讀取更大部分的 x,並且計算出結果送給 B。並不是所有函數組合都可以用管道表示,比如,如何用管道表示 “C(B(x), A(y))”?所以函數組合是更加通用的機制。
5、分支:如果需要把返回值送到兩個不同的程序,你需要使用 tee。這相當於在程序裏把結果存到一個臨時變量,然後使用它兩次。
6、控制流:main 函數的返回值(int型)被 shell 用來作為控制流。shell 可以根據 main 函數返回值來中斷或者繼續運行一個腳本。這就像 Java 的 exception。
7、shell: 各種 shell 語言的本質都是用來連接這些 main 函數的語言,而 shell 的本質其實是一個 REPL (read-eval-print-loop,類似 Lisp)。用程序語言的觀點,shell 語言完全是多余的東西,我們其實可以在 REPL 裏用跟應用程序一樣的程序語言。Lisp 系統就是這樣做的。
數據直接存儲帶來的可能性
由於存儲的是結構化的數據,任何支持這種格式的工具都可以讓用戶直接操作這個數據結構。這會帶來意想不到的好處。
1、因為命令行操作的是結構化的參數,系統可以非常智能的按類型補全命令,讓你完全不可能輸入語法錯誤的命令。
2、可以直接在命令行裏插入顯示圖片之類的 “meta data”。
3、Drag&Drop 桌面上的對象到命令行裏,然後執行。
4、因為代碼是以 parse tree 結構存儲的,IDE 會很容易的擴展到支持所有的程序語言。
5、你可以在看 email 的時候對其中的代碼段進行 IDE 似的結構化編輯,甚至編譯和執行。
6、結構化的版本控制和程序比較(diff)。(參考我的talk)
還有很多很多,僅限於我們的想象力。
程序語言,操作系統,數據庫三位一體
如果 main 函數可以接受多種類型的參數,並且可以有 keyword argument,它能返回一個或多個不同類型的對象作為返回值,而且如果這些對象可以被自動存儲到一種特殊的“數據庫”裏,那麽 shell,管道,命令行選項,甚至連文件系統都沒有必要存在。我們甚至可以說,“操作系統”這個概念變得“透明”。因為這樣一來,操作系統的本質不過是某種程序語言的“運行時系統”(runtime system)。這有點像 JVM 之於 Java。其實從本質上講,Unix 就是 C 語言的運行時系統。
如果我們再進一步,把與數據庫的連接做成透明的,即用同一種程序語言來“隱性”(implicit)的訪問數據庫,而不是像 SQL 之類的專用數據庫語言,那麽“數據庫”這個概念也變得透明了。我們得到的會是一個非常簡單,統一,方便,而且強大的系統。這個系統裏面只有一種程序語言,程序員直接編寫高級語言程序,用同樣的語言從命令行執行它們,而且不用擔心數據放在什麽地方。這樣可以大大的減小程序員工作的復雜度,讓他們專註於問題本身,而不是系統的內部結構。
實際上,類似這樣的系統在歷史上早已存在過 (Lisp Machine, System/38,Oberon),而且收到了不錯的效果。但是由於某些原因(歷史的,經濟的,政治的,技術的),它們都消亡了。但是不得不說它們的這種方式比 Unix 現有的方式優秀,所以何不學過來?我相信,隨著程序語言和編譯器技術發展,它們的這種簡單而統一的設計理念,有一天會改變這個世界。
shell第四篇(下)