
Hive 基礎入門
阿新 • • 發佈:2017-06-10
加載 http 基礎入門 沒有 運行 轉化 自定義 函數 images
Hive的官方網站:
https://hive.apache.org/
Hive簡介:
Hive 是基於Hadoop 的一個數據倉庫工具,可以將結構化的數據文件映射成一張表,並提供類SQL查詢功能。
Hive在企業中作為一種工作,可以很容易的對數據進行ETL。
Hive可以對各種各樣的數據進行一種結構化的查詢。(按照一定結構進行查詢)。
Hive 處理的數據都是存在 HDFS 之上,並且能夠與 HBase 進行集成。
分析數據底層的實現都是 MapReduce ,運行都是運行在 yarn 上邊。
Hive的用途:
數據的查詢、數據的管理。
ETL簡介 :
E : 提取數據
T:轉換數據
L:加載數據
HQL:
HQL 就是 Hive 查詢使用的語句。
Hive本質 :
就是將 HQL 語句轉化為 MapReduce 。
Hive 和 Hadoop 之間的關聯:
都是使用 HDFS 進行數據存儲。
都是使用 yarn 進行資源管理。
都是使用 MapReduce 進行數據處理。
Hive的執行方式:
Hive 就是將數據映射成一個關系型數據庫(RDBMS)的表。而執行方式就是 SQL 語句。
執行SQL語句,底層就會自動的將語句翻譯為MapReduce程序,提交給 YARN 去執行。
Hive 在 Hadoop 生態系統中的地位:
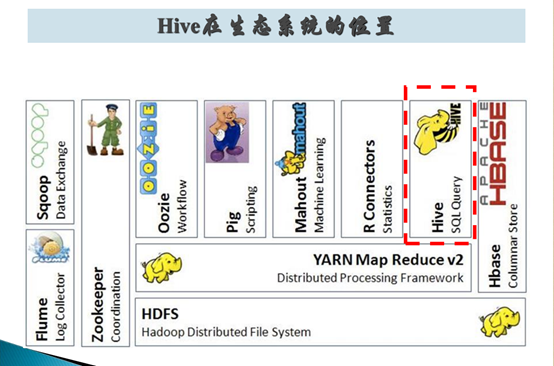
Hive 的架構:

Hive的優點及使用場景
優點:
- 操作接口采用類SQL語法,提供快速開發的能力(簡單、容易上手);
- 避免了去寫MapReduce,減少開發人員的學習成本;
- 統一的元數據管理,可與impala/spark等共享元數據;
- 易擴展(HDFS+MapReduce:可以擴展集群規模;支持自定義函數
使用場景:
- 數據的離線處理;比如:日誌分析,海量結構化數據離線分析…
- Hive的執行延遲比較高,因此hive常用於數據分析的,對實時性要求不高的場合;
- Hive優勢在於處理大數據,對於處理小數據沒有優勢,因為Hive的執行延遲比較高。
Hive 基礎入門