
10 張圖幫你搞定 TensorFlow 數據讀取機制
| 導讀 | 在學習tensorflow的過程中,有很多小夥伴反映讀取數據這一塊很難理解。確實這一塊官方的教程比較簡略,網上也找不到什麽合適的學習材料。今天這篇文章就以圖片的形式,用最簡單的語言,為大家詳細解釋一下tensorflow的數據讀取機制,文章的最後還會給出實戰代碼以供參考。 |
一、tensorflow讀取機制圖解
首先需要思考的一個問題是,什麽是數據讀取?以圖像數據為例,讀取數據的過程可以用下圖來表示:
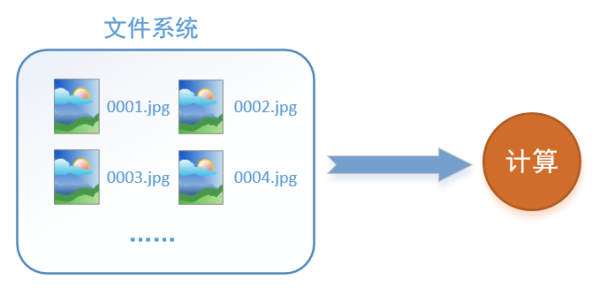
假設我們的硬盤中有一個圖片數據集0001.jpg,0002.jpg,0003.jpg……我們只需要把它們讀取到內存中,然後提供給GPU或是CPU進行計算就可以了。這聽起來很容易,但事實遠沒有那麽簡單。事實上,我們必須要把數據先讀入後才能進行計算,假設讀入用時0.1s,計算用時0.9s,那麽就意味著每過1s,GPU都會有0.1s無事可做,這就大大降低了運算的效率。
如何解決這個問題?方法就是將讀入數據和計算分別放在兩個線程中,將數據讀入內存的一個隊列,如下圖所示:

讀取線程源源不斷地將文件系統中的圖片讀入到一個內存的隊列中,而負責計算的是另一個線程,計算需要數據時,直接從內存隊列中取就可以了。這樣就可以解決GPU因為IO而空閑的問題!
而在tensorflow中,為了方便管理,在內存隊列前又添加了一層所謂的“文件名隊列”。
為什麽要添加這一層文件名隊列?我們首先得了解機器學習中的一個概念:epoch。對於一個數據集來講,運行一個epoch就是將這個數據集中的圖片全部計算一遍。如一個數據集中有三張圖片A.jpg、B.jpg、C.jpg,那麽跑一個epoch就是指對A、B、C三張圖片都計算了一遍。兩個epoch就是指先對A、B、C各計算一遍,然後再全部計算一遍,也就是說每張圖片都計算了兩遍。
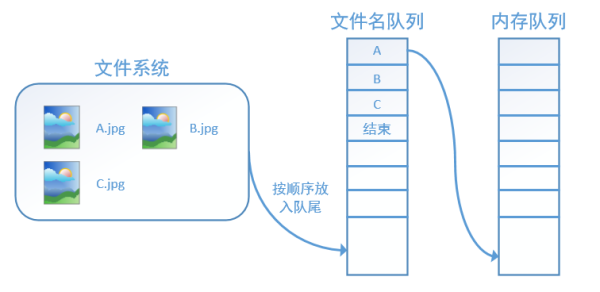
tensorflow使用文件名隊列+內存隊列雙隊列的形式讀入文件,可以很好地管理epoch。下面我們用圖片的形式來說明這個機制的運行方式。如下圖,還是以數據集A.jpg, B.jpg, C.jpg為例,假定我們要跑一個epoch,那麽我們就在文件名隊列中把A、B、C各放入一次,並在之後標註隊列結束。
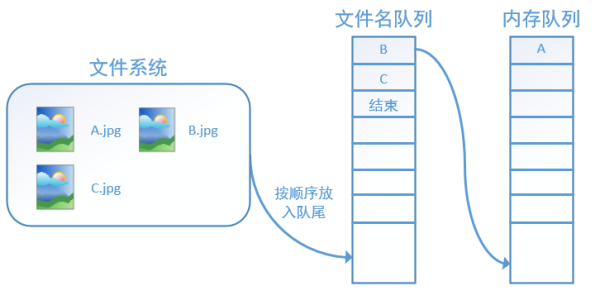
程序運行後,內存隊列首先讀入A(此時A從文件名隊列中出隊):
再依次讀入B和C:
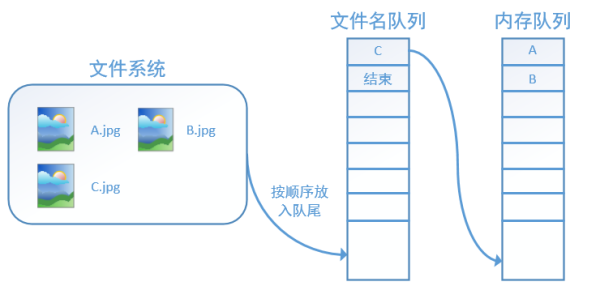
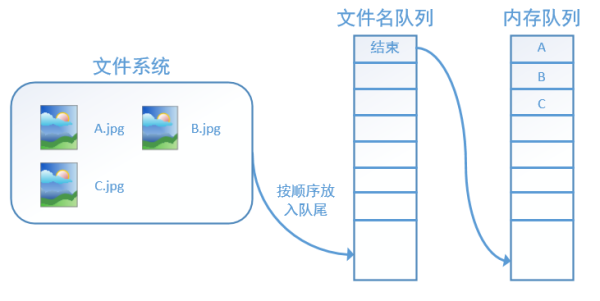
此時,如果再嘗試讀入,系統由於檢測到了“結束”,就會自動拋出一個異常(OutOfRange)。外部捕捉到這個異常後就可以結束程序了。這就是tensorflow中讀取數據的基本機制。如果我們要跑2個epoch而不是1個epoch,那只要在文件名隊列中將A、B、C依次放入兩次再標記結束就可以了。
二、tensorflow讀取數據機制的對應函數
如何在tensorflow中創建上述的兩個隊列呢?
對於文件名隊列,我們使用tf.train.string_input_producer函數。這個函數需要傳入一個文件名list,系統會自動將它轉為一個文件名隊列。
此外tf.train.string_input_producer還有兩個重要的參數,一個是num_epochs,它就是我們上文中提到的epoch數。另外一個就是shuffle,shuffle是指在一個epoch內文件的順序是否被打亂。若設置shuffle=False,如下圖,每個epoch內,數據還是按照A、B、C的順序進入文件名隊列,這個順序不會改變:

如果設置shuffle=True,那麽在一個epoch內,數據的前後順序就會被打亂,如下圖所示:

在tensorflow中,內存隊列不需要我們自己建立,我們只需要使用reader對象從文件名隊列中讀取數據就可以了,具體實現可以參考下面的實戰代碼。
除了tf.train.string_input_producer外,我們還要額外介紹一個函數:tf.train.start_queue_runners。初學者會經常在代碼中看到這個函數,但往往很難理解它的用處,在這裏,有了上面的鋪墊後,我們就可以解釋這個函數的作用了。
在我們使用tf.train.string_input_producer創建文件名隊列後,整個系統其實還是處於“停滯狀態”的,也就是說,我們文件名並沒有真正被加入到隊列中(如下圖所示)。此時如果我們開始計算,因為內存隊列中什麽也沒有,計算單元就會一直等待,導致整個系統被阻塞。

而使用tf.train.start_queue_runners之後,才會啟動填充隊列的線程,這時系統就不再“停滯”。此後計算單元就可以拿到數據並進行計算,整個程序也就跑起來了,這就是函數tf.train.start_queue_runners的用處。

三、實戰代碼
我們用一個具體的例子感受tensorflow中的數據讀取。如圖,假設我們在當前文件夾中已經有A.jpg、B.jpg、C.jpg三張圖片,我們希望讀取這三張圖片5個epoch並且把讀取的結果重新存到read文件夾中。

對應的代碼如下:
# 導入tensorflow
import tensorflow as tf
# 新建一個Session
with tf.Session() as sess:
# 我們要讀三幅圖片A.jpg, B.jpg, C.jpg
filename = [‘A.jpg‘, ‘B.jpg‘, ‘C.jpg‘]
# string_input_producer會產生一個文件名隊列
filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)
# reader從文件名隊列中讀數據。對應的方法是reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
# tf.train.string_input_producer定義了一個epoch變量,要對它進行初始化
tf.local_variables_initializer().run()
# 使用start_queue_runners之後,才會開始填充隊列
threads = tf.train.start_queue_runners(sess=sess)
i = 0
while True:
i += 1
# 獲取圖片數據並保存
image_data = sess.run(value)
with open(‘read/test_%d.jpg‘ % i, ‘wb‘) as f:
f.write(image_data)我們這裏使用filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)建立了一個會跑5個epoch的文件名隊列。並使用reader讀取,reader每次讀取一張圖片並保存。
運行代碼後,我們得到就可以看到read文件夾中的圖片,正好是按順序的5個epoch:

如果我們設置filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)中的shuffle=True,那麽在每個epoch內圖像就會被打亂,如圖所示:

我們這裏只是用三張圖片舉例,實際應用中一個數據集肯定不止3張圖片,不過涉及到的原理都是共通的。
四、總結
這篇文章主要用圖解的方式詳細介紹了tensorflow讀取數據的機制,最後還給出了對應的實戰代碼,希望能夠給大家學習tensorflow帶來一些實質性的幫助。如果各位小夥伴還有什麽疑問,歡迎評論或私信告訴我,謝謝~
原文地址:http://www.linuxprobe.com/tensorflow-learn.html
本文出自 “小華的博客” 博客,請務必保留此出處http://coderhsf.blog.51cto.com/12629645/1936420
10 張圖幫你搞定 TensorFlow 數據讀取機制