
UTF-8和GBK編碼之間的區別(頁面編碼、數據庫編碼區別)以及在實際項目中的應用
第一節:UTF-8和GBK編碼概述
UTF-8 (8-bit Unicode Transformation Format) 是一種針對Unicode的可變長度字符編碼,又稱萬國碼,它包含全世界所有國家需要用到的字符,是國際編碼,通用性強,是用以解決國際上字符的一種多字節編碼。由Ken Thompson於1992年創建。UTF-8用1到4個字節編碼UNICODE字符,它對英文使用8位/8Bit(即1個字節/1Byte),中文使用24位/24Bit(3個字節/3Byte)來編碼。用在網頁上可以同一頁面顯示中文簡體繁體及其它語言(如日文,韓文)。
GBK (Chinese Internal Code Specification)
GBK是國家標準GB2312基礎上擴容後兼容GB2312的標準(GB2312共收錄了7445個字符,包括6763個漢字和682個其它符號;GBK共收錄了27484個漢字,同時還收錄了藏文、蒙文、維吾爾文等主要的少數民族文字)。GBK的文字編碼是用雙字節來表示的,即不論中、英文字符均使用雙字節來表示(註意,GB系列編碼是利用了字節中的最高位和ASCII編碼區分的,可以和ASCII碼混用。所以全角模式下英文是2字節,半角模式英文還是1字節
簡單概況就是:
UTF-8英文1字節中文3字節,在編碼效率和編碼安全性之間做了平衡,適合網絡傳輸,是理想的中文編碼方式.
GBK英文1字節(半角1字節,全角2字節),中文2字節,GBK的範圍比GB2312廣,GBK兼容GB2312。
參考文章:
http://blog.csdn.net/mydriverc2/article/details/50525203
http://blog.csdn.net/liudajiang/article/details/41133077
http://www.cnblogs.com/xiaomia/archive/2010/11/28/1890072.html
第二節:UTF-8和GBK在Web傳輸中的區別
PHP示例代碼:
$str=‘中文‘; // 2個中文
echo strlen($str),‘,‘; // UTF-8長度是:6 (UTF-8編碼: 1個中文3byte,2個中文加起來是6byte)
echo strlen(iconv(‘utf-8‘, ‘GBK‘, $str)),‘,‘; // GBK長度是:4 (GBK編碼:1個中文2byte,2個中文加起來是4byte)
$str=‘a0‘; // 1個英文1個數字
echo strlen($str),‘,‘; // UTF-8長度是:2 (UTF-8編碼: 1個英文或數字是1byte,1個英文和1個數字加起來是2byte)
echo strlen(iconv(‘utf-8‘, ‘GBK‘, $str)),‘,‘; // GBK長度是:2 (GBK編碼:1個英文或數字是1byte, 1個英文和1個數字加起來是2byte)
$str=‘E漢‘; // 1個英文1個中文
echo strlen($str),‘,‘; // UTF-8長度是:4 (UTF-8編碼: 1個中文3byte,1個英文1byte,加起來是4byte)
echo strlen(iconv(‘utf-8‘, ‘GBK‘, $str)); // GBK長度是:3 (GBK編碼:1個中文2byte,1個英文或數字是1byte, 加起來是3byte)
代碼截圖:

輸出結果:
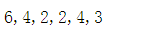
第三節:UTF-8和GBK在數據庫存儲中的區別
====================MySQL測試====================
MySQL示例代碼(UTF8編碼):
-- 創建指定UTF8編碼的表
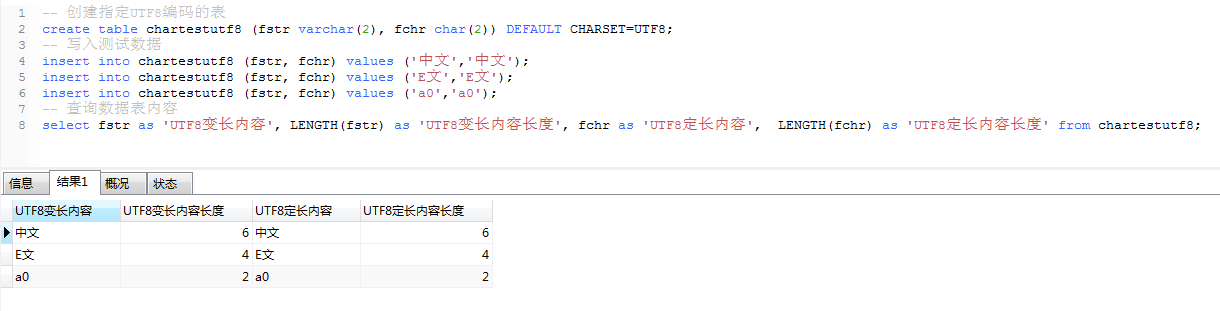
create table chartestutf8 (fstr varchar(2), fchr char(2)) DEFAULT CHARSET=UTF8;
-- 寫入測試數據
insert into chartestutf8 (fstr, fchr) values (‘中文‘,‘中文‘);
insert into chartestutf8 (fstr, fchr) values (‘E文‘,‘E文‘);
insert into chartestutf8 (fstr, fchr) values (‘a0‘,‘a0‘);
-- 查詢數據表內容
select fstr as ‘UTF8變長內容‘, LENGTH(fstr) as ‘UTF8變長內容長度‘, fchr as ‘UTF8定長內容‘, LENGTH(fchr) as ‘UTF8定長內容長度‘ from chartestutf8;
代碼截圖:
內容說明:
UTF-8用1到4個字節編碼UNICODE字符,英文一個字節/1byte (8位/8bit),中文三個字節/3byte (24位/24bit)
‘中文‘ 2個漢字的長度是 3byte * 2 = 6byte
‘E文‘ 1個英文+1個漢字的長度是 1byte + 3byte = 4byte
‘a0‘ 1個英文+1個數字的長度是 1byte + 1byte = 2byte
MySQL示例代碼(GBK編碼):
-- 創建指定GBK編碼的表
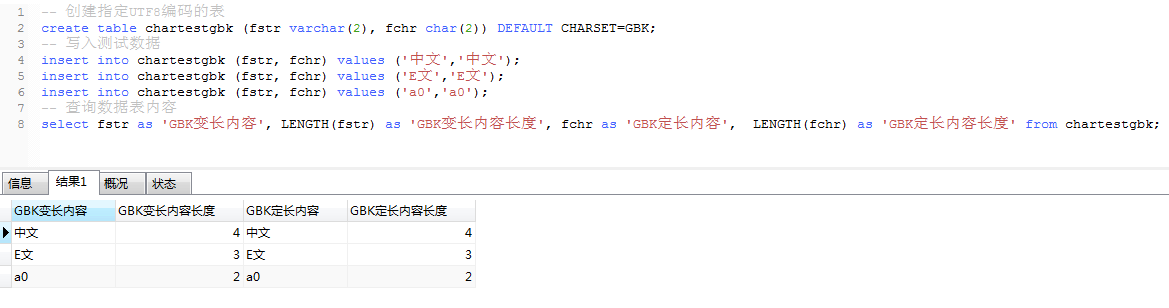
create table chartestgbk (fstr varchar(2), fchr char(2)) DEFAULT CHARSET=GBK;
-- 寫入測試數據
insert into chartestgbk (fstr, fchr) values (‘中文‘,‘中文‘);
insert into chartestgbk (fstr, fchr) values (‘E文‘,‘E文‘);
insert into chartestgbk (fstr, fchr) values (‘a0‘,‘a0‘);
-- 查詢數據表內容
select fstr as ‘GBK變長內容‘, LENGTH(fstr) as ‘GBK變長內容長度‘, fchr as ‘GBK定長內容‘, LENGTH(fchr) as ‘GBK定長內容長度‘ from chartestgbk;
代碼截圖:
內容說明:
GBK的文字編碼用雙字節來表示,即不論中、英文字符均使用雙字節來表示
‘中文‘ 2個漢字的長度是 2byte * 2 = 4byte
‘E文‘ 1個英文+1個漢字的長度是 1byte + 2byte = 3byte
‘a0‘ 1個英文+1個數字的長度是 1byte + 1byte = 2byte
註意:varchar(N), 這裏的N是指字符數,並不是字節數.占用的字節數與編碼有關。
參考文章:
http://www.oschina.net/question/199396_37127
====================SQL Server測試====================
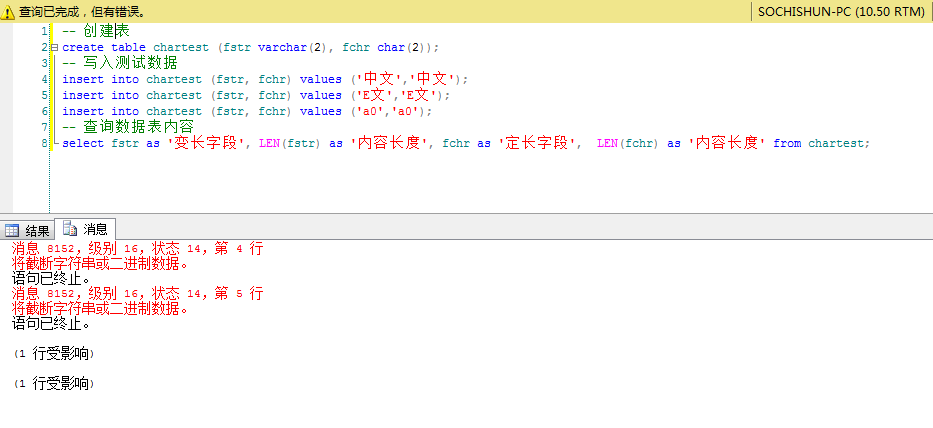
SQL Server示例代碼(Varchar):
-- 創建表
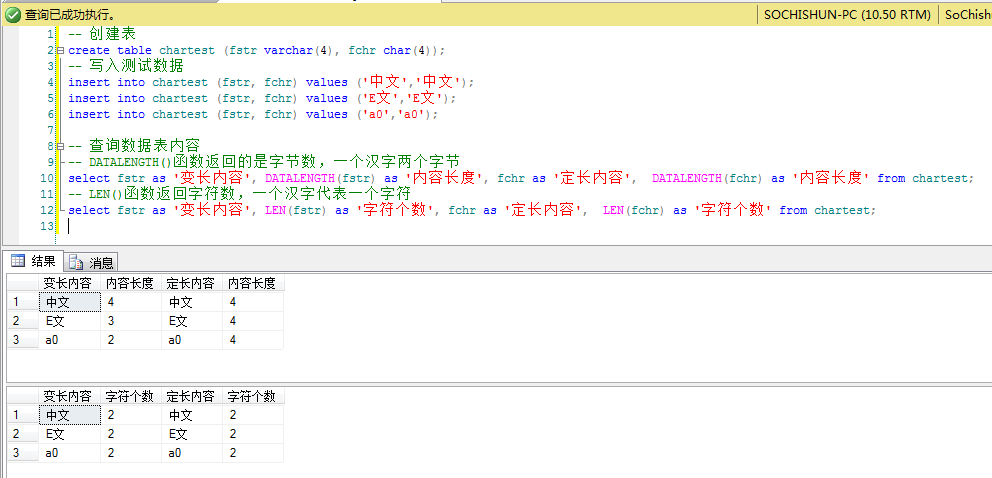
create table chartest (fstr varchar(4), fchr char(4));
-- 寫入測試數據
insert into chartest (fstr, fchr) values (‘中文‘,‘中文‘);
insert into chartest (fstr, fchr) values (‘E文‘,‘E文‘);
insert into chartest (fstr, fchr) values (‘a0‘,‘a0‘);
-- 查詢數據表內容
-- DATALENGTH()函數返回的是字節數,一個漢字兩個字節
select fstr as ‘變長內容‘, DATALENGTH(fstr) as ‘內容長度‘, fchr as ‘定長內容‘, DATALENGTH(fchr) as ‘內容長度‘ from chartest;
-- LEN()函數返回字符數,一個漢字代表一個字符
select fstr as ‘變長內容‘, LEN(fstr) as ‘字符個數‘, fchr as ‘定長內容‘, LEN(fchr) as ‘字符個數‘ from chartest;
代碼截圖:
SQL Server示例代碼(NVarchar):
-- 創建表
create table chartestn (fstr nvarchar(2), fchr nchar(2));
-- 寫入測試數據
insert into chartestn (fstr, fchr) values (‘中文‘,‘中文‘);
insert into chartestn (fstr, fchr) values (‘E文‘,‘E文‘);
insert into chartestn (fstr, fchr) values (‘a0‘,‘a0‘);
-- 查詢數據表內容
-- DATALENGTH()函數返回的是字節數,一個漢字兩個字節
select fstr as ‘變長內容‘, DATALENGTH(fstr) as ‘內容長度‘, fchr as ‘定長內容‘, DATALENGTH(fchr) as ‘內容長度‘ from chartestn;
-- LEN()函數返回字符數,一個漢字代表一個字符
select fstr as ‘變長內容‘, LEN(fstr) as ‘字符個數‘, fchr as ‘定長內容‘, LEN(fchr) as ‘字符個數‘ from chartestn;
代碼截圖:
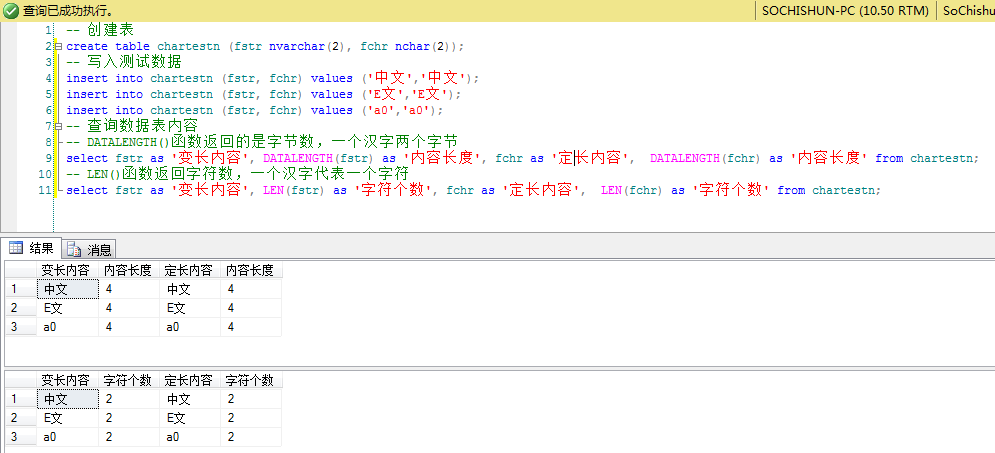
內容說明:
‘中文‘ 2個漢字的長度是 2byte * 2 = 4byte,所以會提示將截斷字符串或二進制數據的錯誤。
‘E文‘ 1個英文+1個漢字的長度是 1byte + 2byte = 3byte
‘a0‘ 1個英文+1個數字的長度是 1byte + 1byte = 2byte
SQL Server定長數據類型(char(n)),不足的補英文半角空格,所以查詢出來的長度都是固定的。
項目應用:
varchar按實際字節長度存儲,1個漢字1字節,1個英文1字節,長度1-8000。
nvarchar按字符數量存儲,不論漢字或英文,都是2字節,長度1-4000。
補充知識:
sql server中的varchar和Nvarchar的區別:
1. Varchar是一個英文和一個漢字都站兩個字節,長度介於1和8000之間,存儲大小為輸入數據的字節的實際長度
2. Nvarchar是一個英文占一個字節,漢字占兩個字節,長度介於1與4000之間,存儲大小是所輸入字符個數的兩倍(n前綴的,n表示Unicode字符,即所有字符都占兩個字節)
3. 從存儲方式上,nvarchar是按字符存儲的,而 varchar是按字節存儲的
4. 從存儲量上考慮, varchar比較節省空間,因為存儲大小為字節的實際長度,而 nvarchar是雙字節存儲
5. 如果你做的項目可能涉及不同國家語言之間的轉換,建議用nvarchar,因為nvarchar是使用Unicode編碼,會減少亂碼的出現幾率
6. Char/NChar固定長度數據類型,不足的補英文半角空格。
LEN()函數:返回給定字符串表達式的字符(而不是字節)個數,其中不包含尾隨空格。(Len只返回字符數,一個漢字代表一個字符)
DATALENGTH()函數:返回任何表達式所占用的字節數。(Datalength返回的是字節數,一個漢字兩個字節)
Len()不包含空格在內長度,而DATALENGTH()包含空格。
參考文章:
http://www.cnblogs.com/14lcj/archive/2012/07/08/2581234.html
http://blog.163.com/rihui_7/blog/static/212285143201211123342333/?NdsKey=246770
|
版權聲明:本文采用署名-非商業性使用-相同方式共享(CC BY-NC-SA 3.0 CN)國際許可協議進行許可,轉載請註明作者及出處。 |
UTF-8和GBK編碼之間的區別(頁面編碼、數據庫編碼區別)以及在實際項目中的應用