
大數據量多維分析項目Kylin調研二期
一、 cube構建步驟
- 登錄頁面
- 創建Project
- 同步數據
1) 加載Hive表
2) 從同步的目錄中導入,即將上張圖中左側的數據庫中的表導入
3) 上傳Hive表
4) 添加流表。
- 創建Model
事實表關聯其他表創建一個model
1) 填寫基本信息
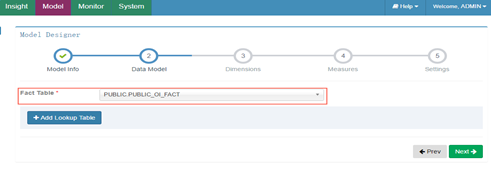
2) 選擇事實表
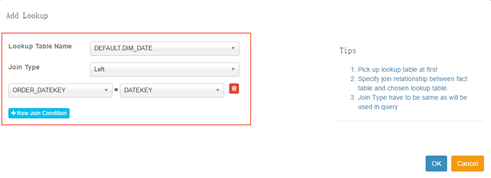
3) 填寫關聯表(lookup_table)及關聯方式
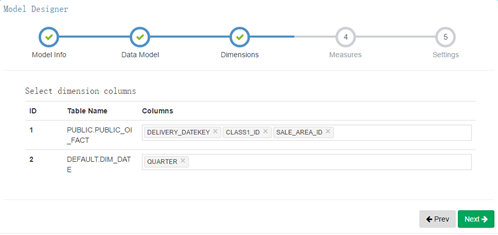
4) 選擇維度
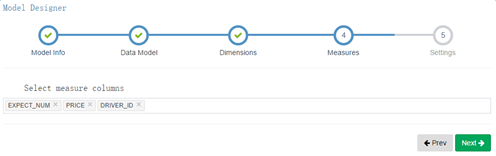
5) 選擇統計值
創建cube
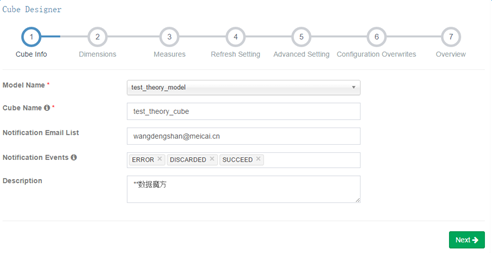
1) cube信息
2) 填寫維度信息
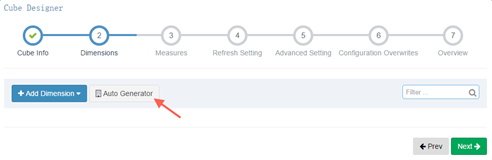
選擇自動生成,全部勾選
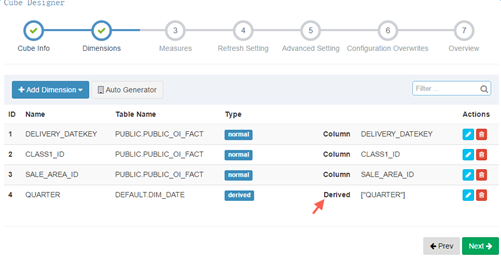
兩種維度說明:為了減少cuboid的數目
Normal,為最常見的類型,與所有其他的dimension組合構成cuboid。
Derived,指該dimensions與維表的primary key是一一對應關系,可以更有效地減少cuboid數量,並且derived dimension只能由lookup table的列生成。
3) 度量信息
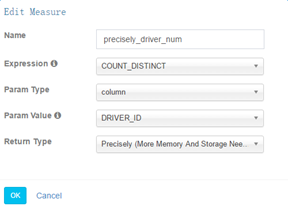
支持去重精確計算
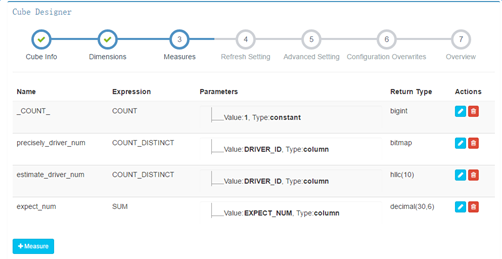
kylin會為每一個cube創建一個聚合函數為count(1)的度量,它不需要關聯任何列,用戶自定義的度量可以選擇SUM、COUNT、DISTINCT COUNT、MIN、MAX,而每一個度量定義時還可以選擇這些聚合函數的參數,可以選擇常量或者事實表的某一列,一般情況下我們當然選擇某一列。這裏我們發現kylin並不提供AVG等相對較復雜的聚合函數(方差、平均差更沒有了),主要是因為它需要基於緩存的cube做增量計算並且合並成新的cube,而這些復雜的聚合函數並不能簡單的對兩個值計算之後得到新的值,例如需要增量合並的兩個cube中某一個key對應的sum值分別為A和B,那麽合並之後的則為A+B,而如果此時的聚合函數是AVG,那麽我們必須知道這個key的count和sum之後才能做聚合。這就要求使用者必須自己想辦法自己計算了。
4) 更新設置
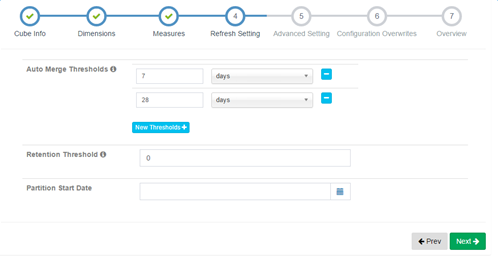
設置增量cube信息,首先需要選擇事實表中的某一個時間類型的分區列(只能是按照天進行分區),然後再指定本次構建的cube的時間範圍(起始時間點),這一步的結果會作為原始數據查詢的where條件,保證本次構建的cube只包含這個閉區間時間內的數據,如果事實表沒有時間類型的分區列或者沒有選擇任何分區則表示數據不會動態更新,也就不可以增量的創建cube了。
除了build這種每個時間區間向前或者向後的新數據計算,還存在兩種對已完成計算數據的處理方式。第一種稱之為Refresh,當某個數據區間的原始數據(hive中)發生變化時,預計算的結果就會出現不一致,因此需要對這個區間的segment進行刷新,即重新計算。第二種稱之為Merge,由於每一個輸入區間對應著一個Segment,結果存儲在一個htable中,久而久之就會出現大量的htable,如果一次查詢涉及的時間跨度比較久會導致對很多表的掃描,性能下降,因此可以通過將多個segment合並成一個大的segment優化。但是merge
在kylin中可以設置merge的時間區間,默認是7、28,表示每當build了前一天的數據就會自動進行一個merge,將這7天的數據放到一個segment中,當最近28天的數據計算完成之後再次merge,以減小掃描的htable數量。但是對於經常需要refresh的數據就不能這樣設置了,因為一旦合並之後,刷新就需要將整個合並之後的segment進行刷新,這無疑是浪費的。
註意:kylin不支持刪除某一天的數據,如果不希望這一天數據存在,可以在hive中刪除並重新refresh這段數據
5) 高級設置
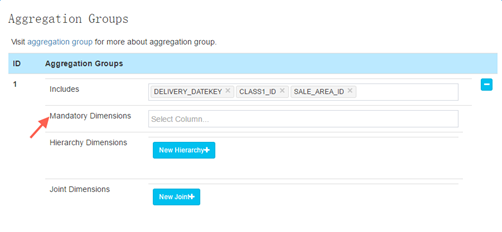
這裏有一個可以修改的是mandatory dimension,如果一個維度需要在每次查詢的時候都出現,那麽可以設置這個dimension為mandatory,可以省去很多存儲空間。
6) 覆蓋配置設置
選默認
7) 保存
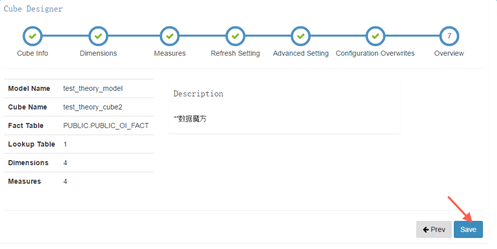
- 構建 cube
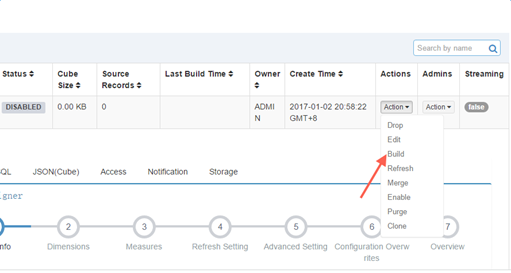
- 查看 cube 構建過程
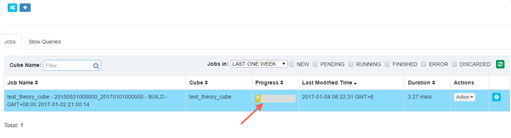
雙擊job查看詳細構建步驟
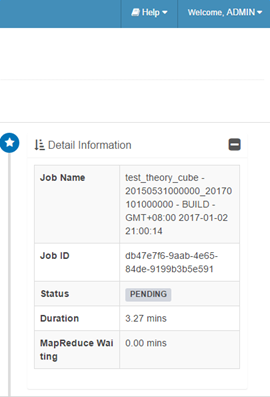
參考:http://www.jianshu.com/p/c49c61b654da
二、 cube構建原理
1. 計算cuboid文件
1) 生成原始數據(Create Intermediate Flat Hive Table)
根據cube的定義創建一個hive外部表,再根據cube中定義的星狀模型,查詢出維度(對於DERIVED類型的維度使用的是外鍵列)和度量的值插入到新創建的表中,然後通過hive -e的方式執行執行以下shell命令:
- drop TABLE IF EXISTS xxx.
- CREATE EXTERNAL TABLE IF NOT EXISTS xxx() ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\177’ STORED AS SEQUENCEFILE LOCATION xxxx
- INSERT OVERWRITE TABLE xxx SELECT xxxx
這一步執行完成之後location指定的目錄下就有了原始數據的文件,為接下來的任務提供了輸入。
2) 創建事實表distinct column文件(Extract Fact Table Distinct Columns)
根據上一步生成的hive表計算出原表中的每一個出現在事實表中的度量的distinct值
根據上一步生成的hive表計算出每一個出現在事實表中的度量的distinct值寫入到文件中。它是啟動一個MR任務完成的,MR任務的輸入是HCatInputFormat,它關聯的表就是上一步創建的臨時表,這個MR任務的map階段首先在setup函數中得到所有度量中出現在事實表的度量在臨時表的index,根據每一個index得到該列在臨時表中在每一行的值value,然後將<index, value>作為mapper的輸出,該任務還啟動了一個combiner,它所做的只是對同一個key的值進行去重(同一個mapper的結果),reducer所做的事情也是進行去重(所有mapper的結果),然後將每一個index對應的值一行行的寫入到以列名命名的文件中。如果某一個維度列的distinct值比較大,那麽可能導致MR任務執行過程中的OOM。
3) 創建維度詞典(Build Dimension Dictionary)
創建所有維度的dictionary
如果是事實表上的維度則可以從上一步生成的文件中讀取該列的distinct成員值(FileTable),否則則需要從原始的hive表中讀取每一列的信息(HiveTable)。獲取所有的列去重之後的成員列表生成dictionary並作為cube的元數據存儲到kylin元數據庫。
計算維度表的snapshotTable
從原始的hive維度表中順序得讀取每一行每一列的值,將每一列的值使用編碼之後的id進行替換得到了一個只有id的維度表的snapshotTable並存儲到kylin的元數據庫中。
4) 計算生成BaseCuboid文件(Build Base Cuboid Data)
這一步也是通過一個MR任務完成的,輸入是臨時表的路徑和分隔符,map對於每一行首先進行split,然後獲取每一個維度列的值並替換為dictionary中的id組合成rowKey,combiner和reducer中根據cube定義中度量的函數按rowKey分組計算每個度量的值。
5) 計算第N層cuboid文件(Build N-Dimension Cuboid Data)
由於最底層的cuboid(base)已經計算完成,下一層cuboid計算的輸出是上一層cuboid執行MR任務的輸入。 mapper的過程只需要根據這一行輸入的key(例如A、B、C、D中四個成員的組合)獲取可能的下一層的的組合(例如只有A、B、C和B、C、D),那麽只需要將這些可能的組合提取出來作為新的key,value不變進行輸出就可以了。它的reducer和base cuboid的reducer過程基本一樣的(相同rowkey的measure執行聚合運算)。
如果有N個維度,那麽就需要有N +1層cuboid,每一層cuboid可能是由多個維度的組合,但是它包含的維度個數相同。
2. 輸出到hbase
1) 計算分組
計算的全部的cuboid文件作為輸入。mapper階段按照cuboid文件的順序(層次的順序)一次讀取每一個key-value,每當統計到1GB的數據將當前的這個key和當前數據量總和輸出。在reducer階段根據用戶創建cube時指定的cube大小(SMALL,MEDIUM和LARGE)和總的大小計算出實際需要劃分為多少分區。再根據實際數據量大小和分區數計算出每一個分區的邊界key,為下一步創建htable做準備。
2) 創建HTable
根據上一步計算出的rowKey分布情況(split數組)創建HTable,創建一個HTable的時候還需要考慮一下幾個事情:1、列簇的設置,2、每一個列簇的壓縮方式,3、部署coprocessor,4、HTable中每一個region的大小。在hbase中存儲的數據key是維度成員的組合,value是對應聚合函數的結果,列組針對的是value的,一般情況下在創建cube的時候只會設置一個列組,該列包含所有的聚合函數的結果;在創建HTable時默認使用LZO壓縮;kylin強依賴於hbase的coprocessor,所以需要在創建HTable為該表部署coprocessor,這個文件會首先上傳到HBase所在的HDFS上,然後在表的元信息中關聯。
參考:http://blog.csdn.net/hljlzc2007/article/details/12652243
3) 構建hfile文件
將cuboid文件轉換成HTable格式的Hfile文件, 通過bulkLoad的方式將文件和HTable進行關聯。
創建完了HTable之後一般會通過插入接口將數據插入到表中,但是由於cuboid中的數據量巨大,頻繁的插入會對Hbase的性能有非常大的影響,所以kylin采取了首先將cuboid文件轉換成HTable格式的Hfile文件,然後在通過bulkLoad的方式將文件和HTable進行關聯,這樣可以大大降低Hbase的負載,這個過程通過一個MR任務完成。
所有的cuboid文件作為mapper階段的輸入,reducer按照行排序輸出。
4) BulkLoad文件
參考:https://my.oschina.net/leejun2005/blog/187309
3. 收尾工作
- 更新狀態
這一步主要是更新cube的狀態,其中需要更新的包括cube是否可用、以及本次構建的數據統計,包括構建完成的時間,輸入的record數目,輸入數據的大小,保存到Hbase中數據的大小等,並將這些信息持久到元數據庫中。
- 垃圾文件回收
這一步是否成功對正確性不會有任何影響,因為經過上一步之後這個segment就可以在這個cube中被查找到了,但是在整個執行過程中產生了很多的垃圾文件,其中包括:1、臨時的hive表,2、因為hive表是一個外部表,存儲該表的文件也需要額外刪除,3、fact distinct 這一步將數據寫入到HDFS上為建立詞典做準備,這時候也可以刪除了,4、rowKey統計的時候會生成一個文件,此時可以刪除。5、生成HFile時文件存儲的路徑和hbase真正存儲的路徑不同,雖然load是一個remove操作,但是上層的目錄還是存在的,也需要刪除。這一步kylin做的比較簡單,並沒有完全刪除所有的臨時文件,其實在整個計算過程中,真正還需要保留的數據只有多個cuboid文件(需要增量build的cube),這個因為在不同segment進行merge的時候是基於cuboid文件的,而不是根據HTable的。
參考:http://blog.csdn.net/yu616568/article/details/50365240
4. 基本概念
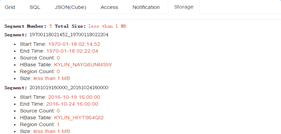
- Cube Segment
每個Cube Segment是對特定時間範圍的數據計算而成的Cube。每個Segment對應一張HBase表。
- Mandotary - 必需的維度:這種類型用於對Cube生成樹做剪枝:如果一個維度被標記為“Mandatory”,會認為所有的查詢都會包含此維度,故所有不含此維度的組合,在Cube構建時都會被剪枝(不計算).
- Hierarchy 維度
Hierarchy - 層級維度:如果多個維度之間有層級(或包含)的關系,通過設置為“Hierarchy”,那些不滿足層級的組合會被剪枝。如果A, B, C是層級,並且A>B>C,那麽只需要計算組合A, AB, ABC; 其它組合如B, C, BC, AC將不做預計算。
- Derived 維度
Derived - 衍生維度:維度表的列值,可以從它的主鍵值衍生而來,那麽通過將這些列定義為衍生維度,可以僅將主鍵加入到Cube的預計算來,而在運行時通過使用維度表的快照,衍生出非PK列的值,從而起到降維的效果。
大數據量多維分析項目Kylin調研二期