
python字符編碼
1. 字符編碼簡介
階段一:現代計算機起源於美國,最早誕生也是基於英文考慮的ASCII
ASCII:一個Bytes代表一個字符(英文字符/鍵盤上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1種變化,即可以表示256個字符
ASCII最初只用了後七位,127個數字,已經完全能夠代表鍵盤上所有的字符了(英文字符/鍵盤的所有其他字符)
後來為了將拉丁文也編碼進了ASCII表,將最高位也占用了
階段二:為了滿足中文,中國人定制了GBK
GBK:2Bytes代表一個字符
為了滿足其他國家,各個國家紛紛定制了自己的編碼
日本把日文編到Shift_JIS裏,韓國把韓文編到Euc-kr裏
階段三:各國有各國的標準,就會不可避免地出現沖突,結果就是,在多語言混合的文本中,顯示出來會有亂碼。
於是產生了unicode, 統一用2Bytes代表一個字符, 2**16-1=65535,可代表6萬多個字符,因而兼容萬國語言
但對於通篇都是英文的文本來說,這種編碼方式無疑是多了一倍的存儲空間(二進制最終都是以電或者磁的方式存儲到存儲介質中的)
於是產生了UTF-8,對英文字符只用1Bytes表示,對中文字符用3Bytes
需要強調的一點是:
unicode:簡單粗暴,所有字符都是2Bytes,優點是字符->數字的轉換速度快,缺點是占用空間大
utf-8:精準,對不同的字符用不同的長度表示,優點是節省空間,缺點是:字符->數字的轉換速度慢,因為每次都需要計算出字符需要多長的Bytes才能夠準確表示
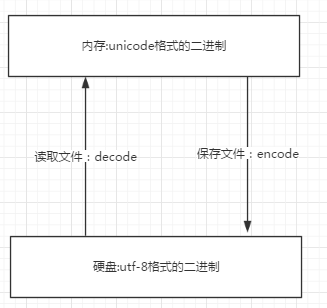
內存中使用的編碼是unicode,用空間換時間(程序都需要加載到內存才能運行,因而內存應該是盡可能的保證快) 硬盤中或者網絡傳輸用utf-8,網絡I/O延遲或磁盤I/O延遲要遠大與utf-8的轉換延遲,而且I/O應該是盡可能地節省帶寬,保證數據傳輸的穩定性。
2.字符編碼的使用
2.1 文本編輯器一鍋端
2.1.2 文本編輯器nodpad++




分析過程?什麽是亂碼
文件從內存刷到硬盤的操作簡稱存文件
文件從硬盤讀到內存的操作簡稱讀文件
亂碼一:存文件時就已經亂碼
存文件時,由於文件內有各個國家的文字,我們單以shiftjis去存,
本質上其他國家的文字由於在shiftjis中沒有找到對應關系而導致存儲失敗,用open函數的write可以測試,f=open(‘a.txt‘,‘w‘,encodig=‘shift_jis‘)
f.write(‘你瞅啥\n何を見て\n‘) #‘你瞅啥‘因為在shiftjis中沒有找到對應關系而無法保存成功,只存‘何を見て\n‘可以成功
但當我們用文件編輯器去存的時候,編輯器會幫我們做轉換,保證中文也能用shiftjis存儲(硬存,必然亂碼),這就導致了,存文件階段就已經發生亂碼
此時當我們用shiftjis打開文件時,日文可以正常顯示,而中文則亂碼了
再或者,存文件時:
f=open(‘a.txt‘,‘wb‘) f.write(‘何を見て\n‘.encode(‘shift_jis‘)) f.write(‘你愁啥\n‘.encode(‘gbk‘)) f.write(‘你愁啥\n‘.encode(‘utf-8‘)) f.close()
以任何編碼打開文件a.txt都會出現其余兩個無法正常顯示的問題
亂碼二:存文件時不亂碼而讀文件時亂碼
存文件時用utf-8編碼,保證兼容萬國,不會亂碼,而讀文件時選擇了錯誤的解碼方式,比如gbk,則在讀階段發生亂碼,讀階段發生亂碼是可以解決的,選對正確的解碼方式就ok了,而存文件時亂碼,則是一種數據的損壞。
2.1.3 文本編輯器pycharm
以gbk格式保存

以utf-8格式打開

分析過程?
總結:
無論是何種編輯器,要防止文件出現亂碼(請一定註意,存放一段代碼的文件也僅僅只是一個普通文件而已,此處指的是文件沒有執行前,我們打開文件時出現的亂碼)
核心法則就是,文件以什麽編碼保存的,就以什麽編碼方式打開
3. 程序的執行
python test.py (我再強調一遍,執行test.py的第一步,一定是先將文件內容讀入到內存中)
階段一:啟動python解釋器
階段二:python解釋器此時就是一個文本編輯器,負責打開文件test.py,即從硬盤中讀取test.py的內容到內存中
此時,python解釋器會讀取test.py的第一行內容,#coding:utf-8,來決定以什麽編碼格式來讀入內存,這一行就是來設定python解釋器這個軟件的編碼使用的編碼格式這個編碼,
可以用sys.getdefaultencoding()查看,如果不在python文件指定頭信息#-*-coding:utf-8-*-,那就使用默認的
python2中默認使用ascii,python3中默認使用utf-8


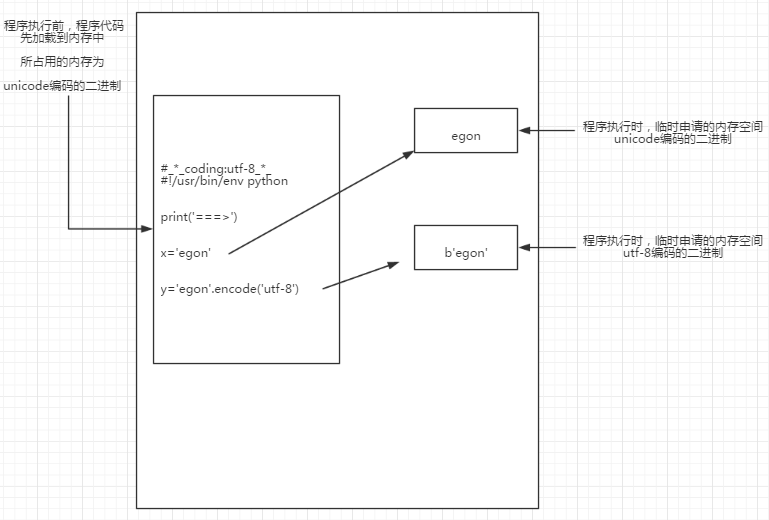
階段三:讀取已經加載到內存的代碼(unicode編碼的二進制),然後執行,執行過程中可能會開辟新的內存空間,比如x="egon"
內存的編碼使用unicode,不代表內存中全都是unicode編碼的二進制,
在程序執行之前,內存中確實都是unicode編碼的二進制,比如從文件中讀取了一行x="egon",其中的x,等號,引號,地位都一樣,都是普通字符而已,都是以unicode編碼的二進制形式存放與內存中的
但是程序在執行過程中,會申請內存(與程序代碼所存在的內存是倆個空間),可以存放任意編碼格式的數據,比如x="egon",會被python解釋器識別為字符串,會申請內存空間來存放"hello",然後讓x指向該內存地址,此時新申請的該內存地址保存也是unicode編碼的egon,如果代碼換成x="egon".encode(‘utf-8‘),那麽新申請的內存空間裏存放的就是utf-8編碼的字符串egon了
針對python3如下圖
瀏覽網頁的時候,服務器會把動態生成的Unicode內容轉換為UTF-8再傳輸到瀏覽器
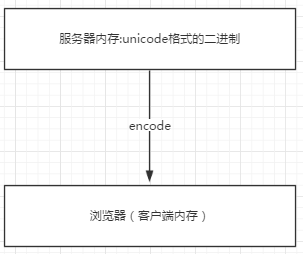
如果服務端encode的編碼格式是utf-8, 客戶端內存中收到的也是utf-8編碼的二進制。
4. python2與python3的區別
4.1 在python2中有兩種字符串類型str和unicode
str類型
當python解釋器執行到產生字符串的代碼時(例如s=‘林‘),會申請新的內存地址,然後將‘林‘encode成文件開頭指定的編碼格式,這已經是encode之後的結果了,所以s只能decode
1 #_*_coding:gbk_*_ 2 #!/usr/bin/env python 3 4 x=‘林‘ 5 # print x.encode(‘gbk‘) #報錯 6 print x.decode(‘gbk‘) #結果:林
所以很重要的一點是:
在python2中,str就是編碼後的結果bytes,str=bytes,所以在python2中,unicode字符編碼的結果是str/bytes

#coding:utf-8 s=‘林‘ #在執行時,‘林‘會被以conding:utf-8的形式保存到新的內存空間中 print repr(s) #‘\xe6\x9e\x97‘ 三個Bytes,證明確實是utf-8 print type(s) #<type ‘str‘> s.decode(‘utf-8‘) # s.encode(‘utf-8‘) #報錯,s為編碼後的結果bytes,所以只能decode
unicode類型
當python解釋器執行到產生字符串的代碼時(例如s=u‘林‘),會申請新的內存地址,然後將‘林‘以unicode的格式存放到新的內存空間中,所以s只能encode,不能decode
s=u‘林‘ print repr(s) #u‘\u6797‘ print type(s) #<type ‘unicode‘> # s.decode(‘utf-8‘) #報錯,s為unicode,所以只能encode s.encode(‘utf-8‘)
打印到終端
對於print需要特別說明的是:
當程序執行時,比如
x=‘林‘
print(x) #這一步是將x指向的那塊新的內存空間(非代碼所在的內存空間)中的內存,打印到終端,而終端仍然是運行於內存中的,所以這打印可以理解為從內存打印到內存,即內存->內存,unicode->unicode
對於unicode格式的數據來說,無論怎麽打印,都不會亂碼
python3中的字符串與python2中的u‘字符串‘,都是unicode,所以無論如何打印都不會亂碼
在pycharm中

在windows終端

但是在python2中存在另外一種非unicode的字符串,此時,print x,會按照終端的編碼執行x.decode(‘終端編碼‘),變成unicode後,再打印,此時終端編碼若與文件開頭指定的編碼不一致,亂碼就產生了
在pycharm中(終端編碼為utf-8,文件編碼為utf-8,不會亂碼)
在windows終端(終端編碼為gbk,文件編碼為utf-8,亂碼產生)

思考題:
分別驗證在pycharm中和cmd中下述的打印結果
#coding:utf-8 s=u‘林‘ #當程序執行時,‘林‘會被以unicode形式保存新的內存空間中 #s指向的是unicode,因而可以編碼成任意格式,都不會報encode錯誤 s1=s.encode(‘utf-8‘) s2=s.encode(‘gbk‘) print s1 #打印正常否? print s2 #打印正常否 print repr(s) #u‘\u6797‘ print repr(s1) #‘\xe6\x9e\x97‘ 編碼一個漢字utf-8用3Bytes print repr(s2) #‘\xc1\xd6‘ 編碼一個漢字gbk用2Bytes print type(s) #<type ‘unicode‘> print type(s1) #<type ‘str‘> print type(s2) #<type ‘str‘>
4.2 在python三種也有兩種字符串類型str和bytes
str是unicode
#coding:utf-8 s=‘林‘ #當程序執行時,無需加u,‘林‘也會被以unicode形式保存新的內存空間中, #s可以直接encode成任意編碼格式 s.encode(‘utf-8‘) s.encode(‘gbk‘) print(type(s)) #<class ‘str‘>
bytes是bytes
#coding:utf-8 s=‘林‘ #當程序執行時,無需加u,‘林‘也會被以unicode形式保存新的內存空間中, #s可以直接encode成任意編碼格式 s1=s.encode(‘utf-8‘) s2=s.encode(‘gbk‘) print(s) #林 print(s1) #b‘\xe6\x9e\x97‘ 在python3中,是什麽就打印什麽 print(s2) #b‘\xc1\xd6‘ 同上 print(type(s)) #<class ‘str‘> print(type(s1)) #<class ‘bytes‘> print(type(s2)) #<class ‘bytes‘>
參考http://www.cnblogs.com/linhaifeng/articles/5950339.html
python字符編碼