
Centos下裝eclipse測試Hadoop
(一),安裝eclipse
1,下載eclipse,點這裏
2,將文件上傳到Centos7,可以用WinSCP
3,解壓並安裝eclipse
[[email protected] opt]# tar zxvf ‘/home/s/eclipse-jee-neon-1a-linux-gtk-x86_64.tar.gz‘ -C/opt ---------------> 建立文件:[[email protected] opt]# mkdir /usr/bin/eclipse ------------------》添加鏈接,即快捷方式:[[email protected]
(二),建立Hadoop項目
1,下載hadoop plugin 2.7.3 鏈接:http://pan.baidu.com/s/1i5yRyuh 密碼:ms91
2,解壓上述jar包插件,放到eclipse中plugins中,並重啟eclipse
2, 在eclipse中加載dfs庫,點擊Windows 工具欄-------->選擇show view如圖:
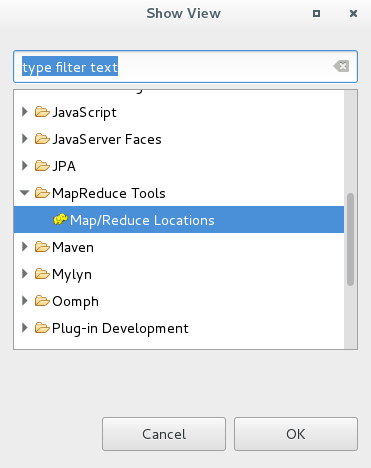
2,打開resource 點擊Window ----->Perspective----------->open Perspective 選擇resource:
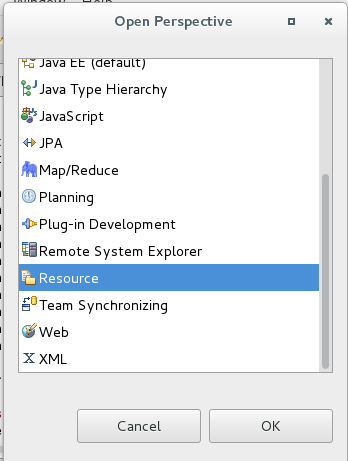
3,配置連接端口,點擊eclipse下放的MapResource Location,點擊添加:其中port號按照hdfs-site.xml 和core-site.xml來填寫。
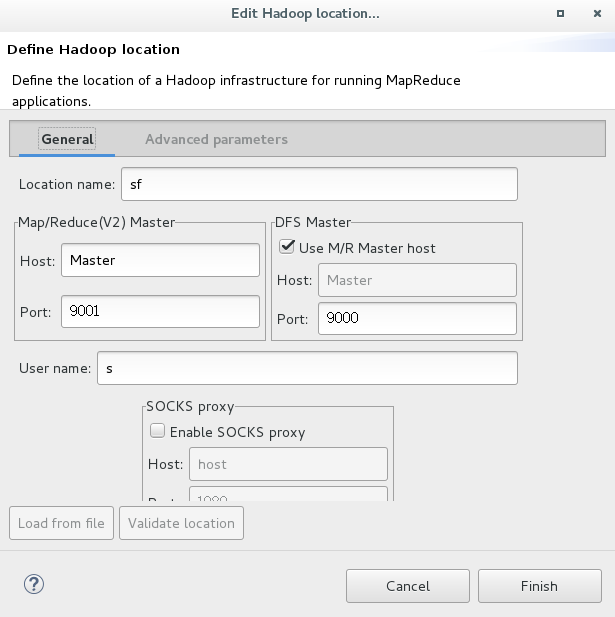
4,上傳輸入文件:使用hdfs dfs -put /home/file1 /data 即可在eclipse中看到如下:(要確保各個機器的防火墻都關閉,出現異常可以暫時不用關,後面跑下例子就全沒了,呵呵)
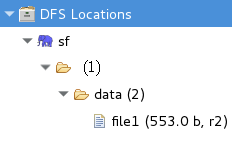
(三),測試WordCount程序
1,新建項目:點擊new ------------》project ----------->Map Reduce,如圖:
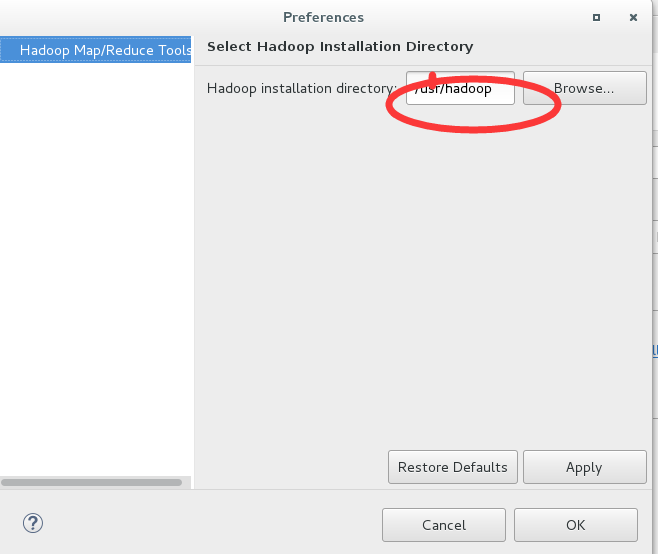
2,給項目配置本地的hadoop文件,圓圈處寫本地hadoop的路徑:
3,新建個mappert類,寫如下代碼:

1 package word;
2
3 import java.io.IOException;
4 import java.util.StringTokenizer;
5
6 import org.apache.hadoop.conf.Configuration;
7 import org.apache.hadoop.fs.Path;
8 import org.apache.hadoop.io.IntWritable;
9 import org.apache.hadoop.io.Text;
10 import org.apache.hadoop.mapreduce.Job;
11 import org.apache.hadoop.mapreduce.Mapper;
12 import org.apache.hadoop.mapreduce.Reducer;
13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
15 import org.apache.hadoop.util.GenericOptionsParser;
16
17 public class mapper {
18
19 public static class TokenizerMapper
20 extends Mapper<Object, Text, Text, IntWritable>{
21
22 private final static IntWritable one = new IntWritable(1);
23 private Text word = new Text();
24
25 public void map(Object key, Text value, Context context
26 ) throws IOException, InterruptedException {
27 StringTokenizer itr = new StringTokenizer(value.toString());
28 while (itr.hasMoreTokens()) {
29 word.set(itr.nextToken());
30 context.write(word, one);
31 }
32 }
33 }
34
35 public static class IntSumReducer
36 extends Reducer<Text,IntWritable,Text,IntWritable> {
37 private IntWritable result = new IntWritable();
38
39 public void reduce(Text key, Iterable<IntWritable> values,
40 Context context
41 ) throws IOException, InterruptedException {
42 int sum = 0;
43 for (IntWritable val : values) {
44 sum += val.get();
45 }
46 result.set(sum);
47 context.write(key, result);
48 }
49 }
50
51 public static void main(String[] args) throws Exception {
52 Configuration conf = new Configuration();
53
54 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
55 if (otherArgs.length != 2) {
56 System.err.println(otherArgs.length);
57 System.err.println("Usage: wordcount <in> <out>");
58 System.exit(2);
59 }
60 Job job = new Job(conf, "word count");
61 job.setJarByClass(mapper.class);
62 job.setMapperClass(TokenizerMapper.class);
63 job.setCombinerClass(IntSumReducer.class);
64 job.setReducerClass(IntSumReducer.class);
65 job.setOutputKeyClass(Text.class);
66 job.setOutputValueClass(IntWritable.class);
67 FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
68 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
69 System.out.print("ok");
70 System.exit(job.waitForCompletion(true) ? 0 : 1);
71 }
72 }
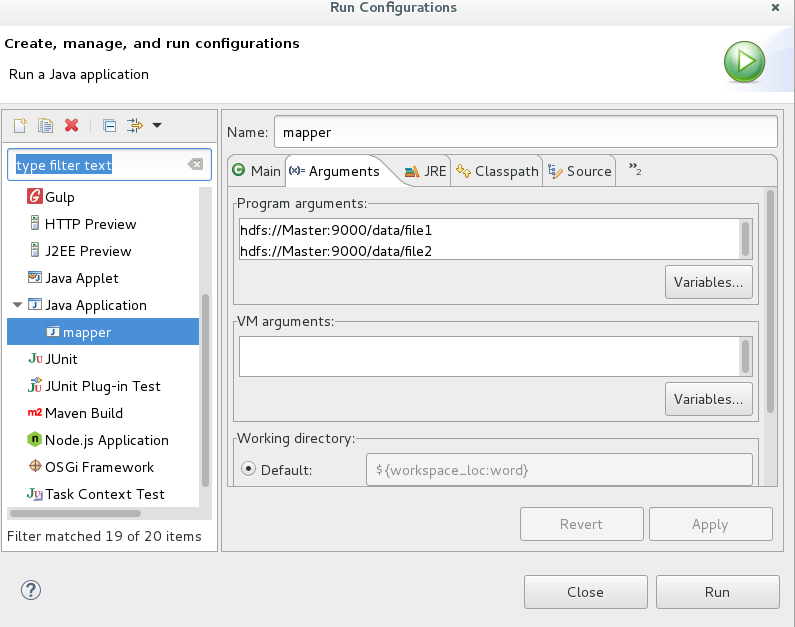
2,點擊run as ------------>RunConfigurations ---------->設置input和output文件參數
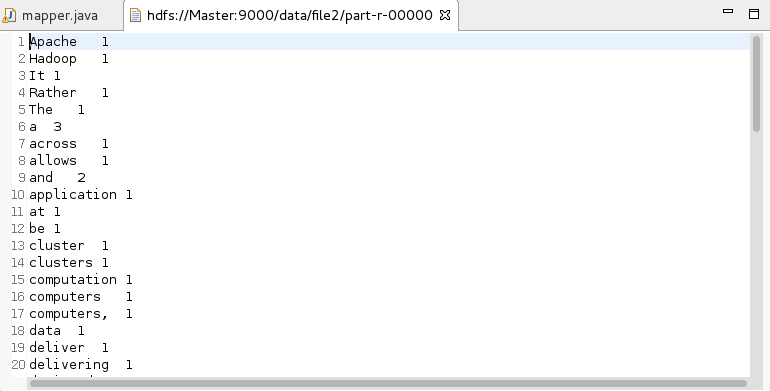
3,點擊run,查看結果
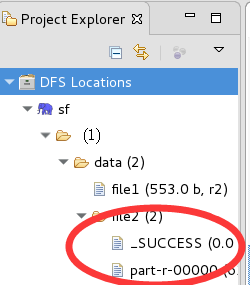
文件的內容:
Centos下裝eclipse測試Hadoop