
Java之IO(九)其它字節流
轉載請註明源出處:http://www.cnblogs.com/lighten/p/7063161.html
1.前言
之前的章節已經介紹了java的io包中所有成對(輸入、輸出對應)的字節流,本章介紹剩余的一些字節流,包括:LineNumberInputStream、SequenceInputStream、StringBufferInputStream。在JDK8的版本中,只有中間的SequenceInputStream沒有被廢棄,其它兩個都被指出已廢棄了。
2.LineNumberInputStream
這個輸入流通過添加函數功能,能保持對輸入流的行數的追蹤。行號從0開始,每次增加1。順便說一下,這個類是在JDK1.0就存在了。被廢棄的原因在類的註釋中也給出了:這個類錯誤地假設bytes能夠足夠表示characters。在JDK1.1中,也就是此類後面的版本,更好的方式來操作字符流就是創建一個新的字符流,這個流中包含了一個用於計算行號的類。這也就是在JDK1.1中出現的LineNumberReader,此節不講,是字符流的內容。
LineNumberInputStream繼承於FilterInputStream,類結構如下:
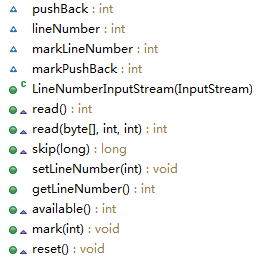
可以看出,對於抽象父類InputStream,其多了set和get行號的兩個方法。下面先看基本的數據流的方法實現。

之前看的結構圖有四個變量,兩個一組應該很好理解,mark開頭的主要是讓Inputstream的mark()方法使用,記錄一下。lineNumber就是記錄的行號了,pushBack有什麽作用呢?看上圖的read邏輯。pushBack默認情況下為-1,-1的時候就讀取一個,不是-1的時候就返回這個暫存的值。讀取一個字節會判斷其是否是\n,是行號就直接加1了,如果是\r,就讓pushBack再讀一個,如果是\n就重置為-1。這段寫的很繞,通俗的說就是:read()方法是讀取一個字節,我們都知道流讀取了就不能再讀取,但是判斷換行符的時候就麻煩了,\r的時候需要判斷一下下一個是否是\n,所以需要再讀取一個字節,這個時候就要保存一下這個字節了,就存在pushback中,pushback一般都是-1,意味著直接讀一個就可以了,不是-1的時候就是說之前判斷的是\r,但下一個不是\n,所以保存了一下這個非\n的字符,本次就直接返回了。上面有一個坑的地方,其判斷了\r之後就還會執行\n,因為沒有break。這會造成下例效果:
@Test
public void test() throws IOException {
ByteArrayInputStream bais = new ByteArrayInputStream("123\r\t\n456\r\n789\r\n".getBytes());
LineNumberInputStream lnis = new LineNumberInputStream(bais);
byte[] buffer = new byte[1024];
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int length;
while((length = lnis.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
System.out.println(new String(baos.toByteArray()));
System.out.println(lnis.getLineNumber());
}
多出現了一個空行。實際上面確實\r\t\n,這個產生了兩個回車,實際上直接輸出也是兩個回車。(-。-)!!!可能廢棄的真正原因就如上所說的byte不能表示所有的字符吧。
3.SequenceInputStream
一個SequenceInputStream表示其他輸入流的邏輯連接。它從一個有序的輸入流開始,從第一個開始直到到達文件的末尾,然後從第二個文件中讀取,以此類推,直到最後一個包含的輸入流到達文件的末尾。
這個流很簡單,結構如下:

就是接受了一組有序的輸入流,讀取的時候,一個個讀到為罷了。

像接力棒一樣,讀完一個又接一個,知道全部讀取完畢。
@Test
public void test2() throws IOException {
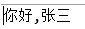
ByteArrayInputStream bais = new ByteArrayInputStream("你好".getBytes());
ByteArrayInputStream bais2 = new ByteArrayInputStream(",張三".getBytes());
SequenceInputStream sis = new SequenceInputStream(bais, bais2);
byte[] buffer = new byte[1024];
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int length;
while((length = sis.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
System.out.println(new String(baos.toByteArray()));
}
4.StringBufferInputStream
這個流也是一個廢棄的方法,其理由是:這個類不能正確地將字符轉換成字節。在JDK 1.1中,從字符串創建流的首選方法是通過StringReader類。
這個類允許應用程序創建一個輸入流,其中讀取的字節是由字符串的內容提供的。應用程序還可以使用ByteArrayInputStream從字節數組中讀取字節。這個類只使用字符串中每個字符的低8位。結構也很簡單:

buffer就是緩存的字符串,count就是這個字符串的長度了。read()方法就是將字符串按字節讀取:

官方雖然給出了這兩個流被廢棄的原因,就是字符和字節之間的轉換問題,但是個人還是不明白哪裏會出問題,對編碼還是所知甚少,目前最大的困惑就是所有的流都是以-1為結束標誌符,C語言的文件流EOF也是-1,為什麽不怕中間有個字節正好是-1呢?這裏有篇文章說了一下這個問題:http://blog.csdn.net/jkler_doyourself/article/details/5645925。沒有完全理解,但是-1是0xFFFFFFFF,而很多流讀取的時候都&0xFF,測試如下:
@Test
public void test3() {
byte[] a = new byte[]{-1};
ByteArrayInputStream bis = new ByteArrayInputStream(a);
System.out.println(bis.read());
}
-1讀出來是255。問題的根本在於並不是說讀取到-1,主要的判斷還是是否結束了,即再取值是否能取到,或者是已知其是否結束。這個方法才是判斷流是否結束了,返回-1。而其它情況&0xFF之後就不會表現成-1了,-1是0xFFFFFFFF。這也是一個比較重要的手段。當然實際上值並沒有改變,因為你再強轉成byte又回到了-1,這裏返回int也就規避了這個問題,取了int的0~255範圍,所以你能夠通過使用read()!=-1來判斷結尾,再通過強轉回byte變成原有的值。我個人是這麽理解的。如有錯誤,請指教一下。
Java之IO(九)其它字節流