
MySQL專題3 SQL 優化
這兩天去京東面試,面試官問了我一個問題,如何優化SQL
我上網查了一下資料,找到了不少方法,做一下記錄
(一)、 首先使用慢查詢分析 通過Mysql 的Slow Query log 可以找到哪些SQL運行很慢。耗時間
在my.ini中:
long_query_time=1
log-slow-queries=d:\mysql5\logs\mysqlslow.log
把超過1秒的記錄在慢查詢日誌中
可以用mysqlsla來分析之。也可以在mysqlreport中,有如
DMS分別分析了select ,update,insert,delete,replace等所占的百份比
慢查詢日誌是將mysql服務器中影響數據庫性能的相關SQL語句記錄到日誌文件,通過對這些特殊的SQL語句分析,改進以達到提高數據庫性能的目的。
缺省情況下hostname-slow.log為慢查詢日誌文件安名,存放到數據目錄,同時缺省情況下未開啟慢查詢日誌。
缺省情況下數據庫相關管理型SQL(比如OPTIMIZE TABLE、ANALYZE TABLE和ALTER TABLE)不會被記錄到日誌。
對於管理型SQL可以通過--log-slow-admin-statements開啟記錄管理型慢SQL。
mysqld在語句執行完並且所有鎖釋放後記入慢查詢日誌。記錄順序可以與執行順序不相同。獲得初使表鎖定的時間不算作執行時間。
參考:MySQL 慢查詢日誌(Slow Query Log)
(二)、找到了SQL之後 ,通過Mysql 的查詢分析器進行分析;
可以通過explain 方法 即在執行的sql前面加上explain,
MySQL性能分析及explain用法的知識是本文我們主要要介紹的內容,接下來就讓我們通過一些實際的例子來介紹這一過程,希望能夠對您有所幫助。
使用explain語句去查看分析結果
如explain select * from test1 where id=1;會出現:id selecttype table type possible_keys key key_len ref rows extra各列。
其中,
type=const表示通過索引一次就找到了;
key=primary的話,表示使用了主鍵;
type=all,表示為全表掃描;
key=null表示沒用到索引。type=ref,因為這時認為是多個匹配行,在聯合查詢中,一般為REF。
參考:MySQL性能分析及explain的使用
參考: 查看SQL語句執行效率
(三)、使用 show profiles 分析查詢時間,
Show profiles是5.0.37之後添加的,要想使用此功能,要確保版本在5.0.37之後。
Query Profiler是MYSQL自帶的一種query診斷分析工具,通過它可以分析出一條SQL語句的性能瓶頸在什麽地方。通常我們是使用的explain,以及slow query log都無法做到精確分析,
但是Query Profiler卻可以定位出一條SQL語句執行的各種資源消耗情況,比如CPU,IO等,以及該SQL執行所耗費的時間等。
查看數據庫版本方法:show variables like "%version%"; 或者 select version();

2.確定支持show profile 後,查看profile是否開啟,數據庫默認是不開啟的。變量profiling是用戶變量,每次都得重新啟用。
查看方法: show variables like "%pro%";
設置開啟方法: set profiling = 1;
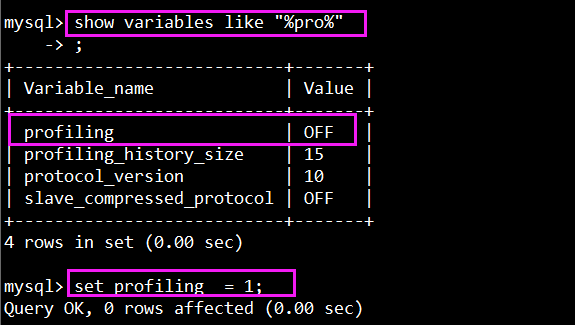
再次查看show variables like "%pro%"; 已經是開啟的狀態了。
3.可以開始執行一些想要分析的sql語句了,執行完後,show profiles;即可查看所有sql的總的執行時間。

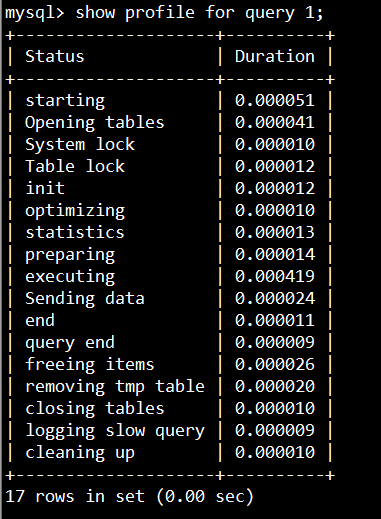
show profile for query 1 即可查看第1個sql語句的執行的各個操作的耗時詳情。
show profile cpu, block io, memory,swaps,context switches,source for query 6;可以查看出一條SQL語句執行的各種資源消耗情況,比如CPU,IO等
show profile all for query 6 查看第6條語句的所有的執行信息。
測試完畢後,關閉參數:
mysql> set profiling=0
參考:查看mysql語句運行時間
(四)以上是總體而言如何對SQL進行優化,具體的對於某一個sql還有如下具體的方法:
1.查詢的模糊匹配
盡量避免在一個復雜查詢裏面使用 LIKE ‘%parm1%‘—— 紅色標識位置的百分號會導致相關列的索引無法使用,最好不要用.
解決辦法:
其實只需要對該腳本略做改進,查詢速度便會提高近百倍。改進方法如下:
a、修改前臺程序——把查詢條件的供應商名稱一欄由原來的文本輸入改為下拉列表,用戶模糊輸入供應商名稱時,直接在前臺就幫忙定位到具體的供應商,這樣在調用後臺程序時,這列就可以直接用等於來關聯了。
b、直接修改後臺——根據輸入條件,先查出符合條件的供應商,並把相關記錄保存在一個臨時表裏頭,然後再用臨時表去做復雜關聯
2.索引問題
在做性能跟蹤分析過程中,經常發現有不少後臺程序的性能問題是因為缺少合適索引造成的,有些表甚至一個索引都沒有。這種情況往往都是因為在設計表時,沒去定義索引,而開發初期,由於表記錄很少,索引創建與否,可能對性能沒啥影響,開發人員因此也未多加重視。然一旦程序發布到生產環境,隨著時間的推移,表記錄越來越多
這時缺少索引,對性能的影響便會越來越大了。
這個問題需要數據庫設計人員和開發人員共同關註
法則:不要在建立的索引的數據列上進行下列操作:
◆避免對索引字段進行計算操作
◆避免在索引字段上使用not,<>,!=
◆避免在索引列上使用IS NULL和IS NOT NULL
◆避免在索引列上出現數據類型轉換
◆避免在索引字段上使用函數
◆避免建立索引的列中使用空值。
3.復雜操作
部分UPDATE、SELECT 語句 寫得很復雜(經常嵌套多級子查詢)——可以考慮適當拆成幾步,先生成一些臨時數據表,再進行關聯操作
4.update
同一個表的修改在一個過程裏出現好幾十次,如:
update table1 set col1=... where col2=...; update table1 set col1=... where col2=... ......
象這類腳本其實可以很簡單就整合在一個UPDATE語句來完成(前些時候在協助xxx項目做性能問題分析時就發現存在這種情況)
5.在可以使用UNION ALL的語句裏,使用了UNION
UNION 因為會將各查詢子集的記錄做比較,故比起UNION ALL ,通常速度都會慢上許多。一般來說,如果使用UNION ALL能滿足要求的話,務必使用UNION ALL。還有一種情況大家可能會忽略掉,就是雖然要求幾個子集的並集需要過濾掉重復記錄,但由於腳本的特殊性,不可能存在重復記錄,這時便應該使用UNION ALL,如xx模塊的某個查詢程序就曾經存在這種情況,見,由於語句的特殊性,在這個腳本中幾個子集的記錄絕對不可能重復,故可以改用UNION ALL)
6.在WHERE 語句中,盡量避免對索引字段進行計算操作
這個常識相信絕大部分開發人員都應該知道,但仍有不少人這麽使用,我想其中一個最主要的原因可能是為了編寫寫簡單而損害了性能,那就不可取了
9月份在對XX系統做性能分析時發現,有大量的後臺程序存在類似用法,如:
......
where trunc(create_date)=trunc(:date1)
雖然已對create_date 字段建了索引,但由於加了TRUNC,使得索引無法用上。此處正確的寫法應該是
where create_date>=trunc(:date1) and create_date<trunc(:date1)+1< pre="">
或者是
where create_date between trunc(:date1) and trunc(:date1)+1-1/(24*60*60)
註意:因between 的範圍是個閉區間(greater than or equal to low value and less than or equal to high value.),
故嚴格意義上應該再減去一個趨於0的小數,這裏暫且設置成減去1秒(1/(24*60*60)),如果不要求這麽精確的話,可以略掉這步。
7.對Where 語句的法則
7.1 避免在WHERE子句中使用in,not in,or 或者having。
可以使用 exist 和not exist代替 in和not in。
原因:1.exist,not exist一般都是與子查詢一起使用. In可以與子查詢一起使用,也可以直接in (a,b.....)。
2.exist會針對子查詢的表使用索引. not exist會對主子查詢都會使用索引. in與子查詢一起使用的時候,只能針對主查詢使用索引. not in則不會使用任何索引. 註意,一直以來認為exists比in效率高的說法是不準確的。
可以使用表鏈接代替 exist。Having可以用where代替,如果無法代替可以分兩步處理。
having 和where 都是用來篩選用的
having 是篩選組 而where是篩選記錄
他們有各自的區別
1》當分組篩選的時候 用having
2》其它情況用where
用having就一定要和group by連用,
用group by不一有having (它只是一個篩選條件用的)
例子
SELECT * FROM ORDERS WHERE CUSTOMER_NAME NOT IN
(SELECT CUSTOMER_NAME FROM CUSTOMER)
優化
SELECT * FROM ORDERS WHERE CUSTOMER_NAME not exist
(SELECT CUSTOMER_NAME FROM CUSTOMER)
7.2 不要以字符格式聲明數字,要以數字格式聲明字符值。(日期同樣)否則會使索引無效,產生全表掃描。
例子使用:
SELECT emp.ename, emp.job FROM emp WHERE emp.empno = 7369;
不要使用:SELECT emp.ename, emp.job FROM emp WHERE emp.empno = ‘7369’
8.對Select語句的法則
在應用程序、包和過程中限制使用select * from table這種方式。看下面例子
使用SELECT empno,ename,category FROM emp WHERE empno = ‘7369‘ 而不要使用SELECT * FROM emp WHERE empno = ‘7369‘
9. 排序
避免使用耗費資源的操作,帶有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL語句會啟動SQL引擎 執行,耗費資源的排序(SORT)功能. DISTINCT需要一次排序操作, 而其他的至少需要執行兩次排序
10.臨時表
慎重使用臨時表可以極大的提高系統性能
參考: SQL關於IN和EXISTS的用法和區別的比較
參考:高手詳解SQL性能優化十條經驗
MySQL專題3 SQL 優化