
Java線程池的分析和使用
1. 引言
合理利用線程池能夠帶來三個好處。第一:降低資源消耗。通過重復利用已創建的線程降低線程創建和銷毀造成的消耗。第二:提高響應速度。當任務到達 時,任務可以不需要的等到線程創建就能立即執行。第三:提高線程的可管理性。線程是稀缺資源,如果無限制的創建,不僅會消耗系統資源,還會降低系統的穩定 性,使用線程池可以進行統一的分配,調優和監控。但是要做到合理的利用線程池,必須對其原理了如指掌。
2.線程池的使用
線程池的創建
我們可以通過ThreadPoolExecutor來創建一個線程池。
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, milliseconds,runnableTaskQueue, threadFactory,handler);
創建一個線程池需要輸入幾個參數:
- corePoolSize(線程池的基本大小):當提交一個任務到線程池時,線程池會創建一個線程來執行任務,即使其他空閑的基本線程能夠執行新 任務也會創建線程,等到需要執行的任務數大於線程池基本大小時就不再創建。如果調用了線程池的prestartAllCoreThreads方法,線程池 會提前創建並啟動所有基本線程。
- runnableTaskQueue(任務隊列):用於保存等待執行的任務的阻塞隊列。可以選擇以下幾個阻塞隊列。
- ArrayBlockingQueue:是一個基於數組結構的有界阻塞隊列,此隊列按 FIFO(先進先出)原則對元素進行排序。
- LinkedBlockingQueue:一個基於鏈表結構的阻塞隊列,此隊列按FIFO (先進先出) 排序元素,吞吐量通常要高於ArrayBlockingQueue。靜態工廠方法Executors.newFixedThreadPool()使用了這個隊列。
- SynchronousQueue:一個不存儲元素的阻塞隊列。每個插入操作必須等到另一個線程調用移除操作,否則插入操作一直處於阻塞狀態,吞 吐量通常要高於LinkedBlockingQueue,靜態工廠方法Executors.newCachedThreadPool使用了這個隊列。
- PriorityBlockingQueue:一個具有優先級得無限阻塞隊列。
- maximumPoolSize(線程池最大大小):線程池允許創建的最大線程數。如果隊列滿了,並且已創建的線程數小於最大線程數,則線程池會再創建新的線程執行任務。值得註意的是如果使用了無界的任務隊列這個參數就沒什麽效果。
- ThreadFactory:用於設置創建線程的工廠,可以通過線程工廠給每個創建出來的線程設置更有意義的名字,Debug和定位問題時非常又幫助。
RejectedExecutionHandler(飽和策略):當隊列和線程池都滿了,說明線程池處於飽和狀態,那麽必須采取一種策略處理提交的 新任務。這個策略默認情況下是AbortPolicy,表示無法處理新任務時拋出異常。以下是JDK1.5提供的四種策略。n AbortPolicy:直接拋出異常。
- CallerRunsPolicy:只用調用者所在線程來運行任務。
- DiscardOldestPolicy:丟棄隊列裏最近的一個任務,並執行當前任務。
- DiscardPolicy:不處理,丟棄掉。
- 當然也可以根據應用場景需要來實現RejectedExecutionHandler接口自定義策略。如記錄日誌或持久化不能處理的任務。
- keepAliveTime(線程活動保持時間):線程池的工作線程空閑後,保持存活的時間。所以如果任務很多,並且每個任務執行的時間比較短,可以調大這個時間,提高線程的利用率。
- TimeUnit(線程活動保持時間的單位):可選的單位有天(DAYS),小時(HOURS),分鐘(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。
向線程池提交任務
我們可以使用execute提交的任務,但是execute方法沒有返回值,所以無法判斷任務知否被線程池執行成功。通過以下代碼可知execute方法輸入的任務是一個Runnable類的實例。
threadsPool.execute(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
}
});
我們也可以使用submit 方法來提交任務,它會返回一個future,那麽我們可以通過這個future來判斷任務是否執行成功,通過 future的get方法來獲取返回值,get方法會阻塞住直到任務完成,而使用get(long timeout, TimeUnit unit)方法則會阻塞一段時間後立即返回,這時有可能任務沒有執行完。
try {
Object s = future.get();
} catch (InterruptedException e) {
// 處理中斷異常
} catch (ExecutionException e) {
// 處理無法執行任務異常
} finally {
// 關閉線程池
executor.shutdown();
}
線程池的關閉
我們可以通過調用線程池的shutdown或shutdownNow方法來關閉線程池,但是它們的實現原理不同,shutdown的原理是只是將線 程池的狀態設置成SHUTDOWN狀態,然後中斷所有沒有正在執行任務的線程。shutdownNow的原理是遍歷線程池中的工作線程,然後逐個調用線程 的interrupt方法來中斷線程,所以無法響應中斷的任務可能永遠無法終止。shutdownNow會首先將線程池的狀態設置成STOP,然後嘗試停 止所有的正在執行或暫停任務的線程,並返回等待執行任務的列表。
只要調用了這兩個關閉方法的其中一個,isShutdown方法就會返回true。當所有的任務都已關閉後,才表示線程池關閉成功,這時調用 isTerminaed方法會返回true。至於我們應該調用哪一種方法來關閉線程池,應該由提交到線程池的任務特性決定,通常調用shutdown來關 閉線程池,如果任務不一定要執行完,則可以調用shutdownNow。
3. 線程池的分析
流程分析:線程池的主要工作流程如下圖:
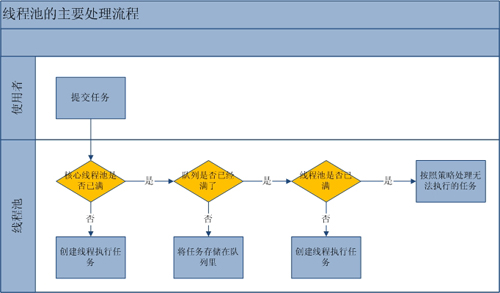
從上圖我們可以看出,當提交一個新任務到線程池時,線程池的處理流程如下:
- 首先線程池判斷基本線程池是否已滿?沒滿,創建一個工作線程來執行任務。滿了,則進入下個流程。
- 其次線程池判斷工作隊列是否已滿?沒滿,則將新提交的任務存儲在工作隊列裏。滿了,則進入下個流程。
- 最後線程池判斷整個線程池是否已滿?沒滿,則創建一個新的工作線程來執行任務,滿了,則交給飽和策略來處理這個任務。
源碼分析。上面的流程分析讓我們很直觀的了解的線程池的工作原理,讓我們再通過源代碼來看看是如何實現的。線程池執行任務的方法如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//如果線程數小於基本線程數,則創建線程並執行當前任務
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
//如線程數大於等於基本線程數或線程創建失敗,則將當前任務放到工作隊列中。
if (runState == RUNNING && workQueue.offer(command)) {
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
//如果線程池不處於運行中或任務無法放入隊列,並且當前線程數量小於最大允許的線程數量,則創建一個線程執行任務。
else if (!addIfUnderMaximumPoolSize(command))
//拋出RejectedExecutionException異常
reject(command); // is shutdown or saturated
}
}
工作線程。線程池創建線程時,會將線程封裝成工作線程Worker,Worker在執行完任務後,還會無限循環獲取工作隊列裏的任務來執行。我們可以從Worker的run方法裏看到這點:
public void run() {
try {
Runnable task = firstTask;
firstTask = null;
while (task != null || (task = getTask()) != null) {
runTask(task);
task = null;
}
} finally {
workerDone(this);
}
}
4. 合理的配置線程池
要想合理的配置線程池,就必須首先分析任務特性,可以從以下幾個角度來進行分析:
- 任務的性質:CPU密集型任務,IO密集型任務和混合型任務。
- 任務的優先級:高,中和低。
- 任務的執行時間:長,中和短。
- 任務的依賴性:是否依賴其他系統資源,如數據庫連接。
任務性質不同的任務可以用不同規模的線程池分開處理。CPU密集型任務配置盡可能少的線程數量,如配置Ncpu+1個線程的線程池。IO密集型任務則由於需要等待IO操作,線程並不是一直在執行任務,則配置盡可能多的線程,如2*Ncpu。 混合型的任務,如果可以拆分,則將其拆分成一個CPU密集型任務和一個IO密集型任務,只要這兩個任務執行的時間相差不是太大,那麽分解後執行的吞吐率要 高於串行執行的吞吐率,如果這兩個任務執行時間相差太大,則沒必要進行分解。我們可以通過 Runtime.getRuntime().availableProcessors()方法獲得當前設備的CPU個數。
優先級不同的任務可以使用優先級隊列PriorityBlockingQueue來處理。它可以讓優先級高的任務先得到執行,需要註意的是如果一直有優先級高的任務提交到隊列裏,那麽優先級低的任務可能永遠不能執行。
執行時間不同的任務可以交給不同規模的線程池來處理,或者也可以使用優先級隊列,讓執行時間短的任務先執行。
依賴數據庫連接池的任務,因為線程提交SQL後需要等待數據庫返回結果,如果等待的時間越長CPU空閑時間就越長,那麽線程數應該設置越大,這樣才能更好的利用CPU。
建議使用有界隊列,有界隊列能增加系統的穩定性和預警能力,可以根據需要設大一點,比如幾千。有一次我們組使用的後臺任務線程池的隊 列和線程池全滿了,不斷的拋出拋棄任務的異常,通過排查發現是數據庫出現了問題,導致執行SQL變得非常緩慢,因為後臺任務線程池裏的任務全是需要向數據 庫查詢和插入數據的,所以導致線程池裏的工作線程全部阻塞住,任務積壓在線程池裏。如果當時我們設置成無界隊列,線程池的隊列就會越來越多,有可能會撐滿 內存,導致整個系統不可用,而不只是後臺任務出現問題。當然我們的系統所有的任務是用的單獨的服務器部署的,而我們使用不同規模的線程池跑不同類型的任 務,但是出現這樣問題時也會影響到其他任務。
5. 線程池的監控
通過線程池提供的參數進行監控。線程池裏有一些屬性在監控線程池的時候可以使用
- taskCount:線程池需要執行的任務數量。
- completedTaskCount:線程池在運行過程中已完成的任務數量。小於或等於taskCount。
- largestPoolSize:線程池曾經創建過的最大線程數量。通過這個數據可以知道線程池是否滿過。如等於線程池的最大大小,則表示線程池曾經滿了。
- getPoolSize:線程池的線程數量。如果線程池不銷毀的話,池裏的線程不會自動銷毀,所以這個大小只增不減。
- getActiveCount:獲取活動的線程數。
通過擴展線程池進行監控。通過繼承線程池並重寫線程池的beforeExecute,afterExecute和terminated方法,我們可以在任務執行前,執行後和線程池關閉前幹一些事情。如監控任務的平均執行時間,最大執行時間和最小執行時間等。這幾個方法在線程池裏是空方法。如:
<b>protected</b> <b>void</b> beforeExecute(Thread t, Runnable r) { }
6. 參考資料
- Java並發編程實戰。
- JDK1.6源碼。
Java線程池的分析和使用