
Knowledge Tracing -- 基於貝葉斯的學生知識點追蹤(BKT)
目前,教育領域通過引入人工智能的技術,使得在線的教學系統成為了智能教學系統(ITS),ITS不同與以往的MOOC形式的課程。ITS能夠個性化的為學生制定有效的
學習路徑,通過根據學生的答題情況追蹤學生當前的一個知識點掌握狀況,從而可以做到因材施教。
在智能教學系統中,當前有使用以下三種模型對學生的知識點掌握狀況進行一個追蹤判斷:
- IRT(Item response theory) 項目反應理論
- BKT(Bayesin knowledge tracing) 基於貝葉斯網絡的學生知識點追蹤模型
- DKT(Deep konwledge traing) 基於深度神經網絡的學生知識點追蹤模型
今天我們主要說一下BKT:
BKT是最常用的一個模型,BKT是含有隱變量的馬爾可夫模型(HMM)。因此可以采用EM算法或者bruteForce 算法求解參數。
BKT是對學生知識點的一個變化進行追蹤,可以知道學生知識點的一個掌握情況變化。
一般有個stop_policy準則,用於判斷學生是否經過多輪的做題掌握了相應的知識點。
(Once that probability reaches 0.95, the student can be assumed to have learned the skill. The Cognitive Tutors use this threshold to determine when a student should no longer be asked to answer questions of a particular skill)
(1)首先我們來看一下BKT的模型是如何的:
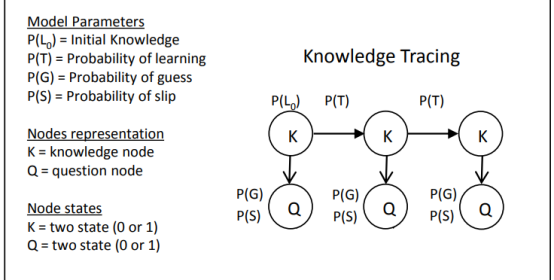
如下圖,是BKT的一個模型,以及對應的4個主要參數,L0,T,G,S。模型需要根據學生以往的歷史答題系列情況學習出這4個對應的參數。
BKT是對不同的的知識點進行建模的,理論上來說,訓練數據有多少個知識點,就有多少組對應的(L0,T,G,S)參數。
L0:表示學生的未開始做這道題目時,或者為開始連續這項知識點的時候,他的一個掌握程度如何(即掌握這個知識點的概率是多少),這個一般我們可以從訓練數據裏面求平均值獲得,也可以使用經驗,比如一般來說掌握的程度是對半概率,那麽L0=0.5
T :表示學生經過做題練習後,知識點從不會到學會的概率
G:表示學生沒掌握這項知識點,但是還是蒙對的概率
S:表示學生實際上掌握了這項知識點,但是還是給做錯了的概率
通過這4個參數,可以構造一個HMM的模型,剩下的事就是訓練這個模型
(2)有什麽改進的嗎?
其實可以發現,這樣構造模型,還是非常簡單的,模型只是只是簡單的針對知識點進行訓練,所有的學生都是用的同一個模型。但是學生有好有壞,
因此可以加個節點,不同的學生使用不同的L0。
另外題目的難度也是可以應用到模型的,比如難度系數大的 G S參數就可以不一樣。根據難度系數訓練多組G S
參考論文:
From Predictive Models to Instructional Policies
Knowledge Tracing -- 基於貝葉斯的學生知識點追蹤(BKT)