
K8S基礎概念
一、核心概念
1、Node
Node作為集群中的工作節點,運行真正的應用程序,在Node上Kubernetes管理的最小運行單元是Pod。Node上運行著Kubernetes的Kubelet、kube-proxy服務進程,這些服務進程負責Pod的創建、啟動、監控、重啟、銷毀、以及實現軟件模式的負載均衡。
Node包含的信息:
- Node地址:主機的IP地址,或Node ID。
- Node的運行狀態:Pending、Running、Terminated三種狀態。
- Node Condition:…
- Node系統容量:描述Node可用的系統資源,包括CPU、內存、最大可調度Pod數量等。
- 其他:內核版本號、Kubernetes版本等。
查看Node信息:
kubectl describe node
2、Pod
Pod是Kubernetes最基本的操作單元,包含一個或多個緊密相關的容器,一個Pod可以被一個容器化的環境看作應用層的“邏輯宿主機”;一個Pod中的多個容器應用通常是緊密耦合的,Pod在Node上被創建、啟動或者銷毀;每個Pod裏運行著一個特殊的被稱之為Pause的容器,其他容器則為業務容器,這些業務容器共享Pause容器的網絡棧和Volume掛載卷,因此他們之間通信和數據交換更為高效,在設計時我們可以充分利用這一特性將一組密切相關的服務進程放入同一個Pod中。
同一個Pod裏的容器之間僅需通過localhost就能互相通信。

一個Pod中的應用容器共享同一組資源:
- PID命名空間:Pod中的不同應用程序可以看到其他應用程序的進程ID;
- 網絡命名空間:Pod中的多個容器能夠訪問同一個IP和端口範圍;
- IPC命名空間:Pod中的多個容器能夠使用SystemV IPC或POSIX消息隊列進行通信;
- UTS命名空間:Pod中的多個容器共享一個主機名;
- Volumes(共享存儲卷):Pod中的各個容器可以訪問在Pod級別定義的Volumes;
Pod的生命周期通過Replication Controller來管理;通過模板進行定義,然後分配到一個Node上運行,在Pod所包含容器運行結束後,Pod結束。
Kubernetes為Pod設計了一套獨特的網絡配置,包括:為每個Pod分配一個IP地址,使用Pod名作為容器間通信的主機名等。
3、Service
在Kubernetes的世界裏,雖然每個Pod都會被分配一個單獨的IP地址,但這個IP地址會隨著Pod的銷毀而消失,這就引出一個問題:如果有一組Pod組成一個集群來提供服務,那麽如何來訪問它呢?Service!
一個Service可以看作一組提供相同服務的Pod的對外訪問接口,Service作用於哪些Pod是通過Label Selector來定義的。
- 擁有一個指定的名字(比如my-mysql-server);
- 擁有一個虛擬IP(Cluster IP、Service IP或VIP)和端口號,銷毀之前不會改變,只能內網訪問;
- 能夠提供某種遠程服務能力;
- 被映射到了提供這種服務能力的一組容器應用上;
如果Service要提供外網服務,需指定公共IP和NodePort,或外部負載均衡器;
NodePort
系統會在Kubernetes集群中的每個Node上打開一個主機的真實端口,這樣,能夠訪問Node的客戶端就能通過這個端口訪問到內部的Service了
4、Volume
Volume是Pod中能夠被多個容器訪問的共享目錄。
5、Label
Label以key/value的形式附加到各種對象上,如Pod、Service、RC、Node等,以識別這些對象,管理關聯關系等,如Service和Pod的關聯關系。
6、RC(Replication Controller)
- 目標Pod的定義;
- 目標Pod需要運行的副本數量;
- 要監控的目標Pod標簽(Lable);
Kubernetes通過RC中定義的Lable篩選出對應的Pod實例,並實時監控其狀態和數量,如果實例數量少於定義的副本數量(Replicas),則會根據RC中定義的Pod模板來創建一個新的Pod,然後將此Pod調度到合適的Node上啟動運行,直到Pod實例數量達到預定目標。
二、Kubernetes總體架構
Master和Node
Kubernetes將集群中的機器劃分為一個Master節點和一群工作節點(Node)。其中,Master節點上運行著集群管理相關的一組進程etcd、API Server、Controller Manager、Scheduler,後三個組件構成了Kubernetes的總控中心,這些進程實現了整個集群的資源管理、Pod調度、彈性伸縮、安全控制、系統監控和糾錯等管理功能,並且全都是自動完成。在每個Node上運行Kubelet、Proxy、Docker daemon三個組件,負責對本節點上的Pod的生命周期進行管理,以及實現服務代理的功能。
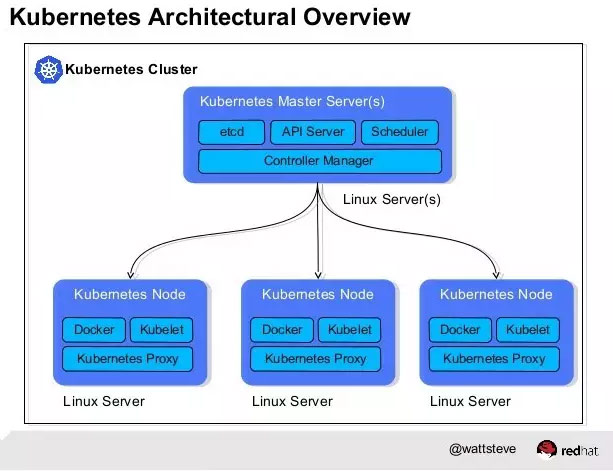
流程
通過Kubectl提交一個創建RC的請求,該請求通過API Server被寫入etcd中,此時Controller Manager通過API Server的監聽資源變化的接口監聽到這個RC事件,分析之後,發現當前集群中還沒有它所對應的Pod實例,於是根據RC裏的Pod模板定義生成一個Pod對象,通過API Server寫入etcd,接下來,此事件被Scheduler發現,它立即執行一個復雜的調度流程,為這個新Pod選定一個落戶的Node,然後通過API Server講這一結果寫入到etcd中,隨後,目標Node上運行的Kubelet進程通過API Server監測到這個“新生的”Pod,並按照它的定義,啟動該Pod並任勞任怨地負責它的下半生,直到Pod的生命結束。
隨後,我們通過Kubectl提交一個新的映射到該Pod的Service的創建請求,Controller Manager會通過Label標簽查詢到相關聯的Pod實例,然後生成Service的Endpoints信息,並通過API Server寫入到etcd中,接下來,所有Node上運行的Proxy進程通過API Server查詢並監聽Service對象與其對應的Endpoints信息,建立一個軟件方式的負載均衡器來實現Service訪問到後端Pod的流量轉發功能。
-
etcd
用於持久化存儲集群中所有的資源對象,如Node、Service、Pod、RC、Namespace等;API Server提供了操作etcd的封裝接口API,這些API基本上都是集群中資源對象的增刪改查及監聽資源變化的接口。 -
API Server
提供了資源對象的唯一操作入口,其他所有組件都必須通過它提供的API來操作資源數據,通過對相關的資源數據“全量查詢”+“變化監聽”,這些組件可以很“實時”地完成相關的業務功能。 -
Controller Manager
集群內部的管理控制中心,其主要目的是實現Kubernetes集群的故障檢測和恢復的自動化工作,比如根據RC的定義完成Pod的復制或移除,以確保Pod實例數符合RC副本的定義;根據Service與Pod的管理關系,完成服務的Endpoints對象的創建和更新;其他諸如Node的發現、管理和狀態監控、死亡容器所占磁盤空間及本地緩存的鏡像文件的清理等工作也是由Controller Manager完成的。 -
Scheduler
集群中的調度器,負責Pod在集群節點中的調度分配。 -
Kubelet
負責本Node節點上的Pod的創建、修改、監控、刪除等全生命周期管理,同時Kubelet定時“上報”本Node的狀態信息到API Server裏。 -
Proxy
實現了Service的代理與軟件模式的負載均衡器。
客戶端通過Kubectl命令行工具或Kubectl Proxy來訪問Kubernetes系統,在Kubernetes集群內部的客戶端可以直接使用Kuberctl命令管理集群。Kubectl Proxy是API Server的一個反向代理,在Kubernetes集群外部的客戶端可以通過Kubernetes Proxy來訪問API Server。
API Server內部有一套完備的安全機制,包括認證、授權和準入控制等相關模塊。
K8S基礎概念