
day 10 字符編碼和文件處理 細節整理
pycharm是文本編輯器。
1 .字符編碼:
字符====== (翻譯過程)=======》數字。
utf-8是unicode的變種,是萬國編碼。
2. 文本編輯器存取文件的原理(nodepad++,pycharm,word)
打開編輯器就打開了啟動了一個進程,是在內存中的,所以在編輯器編寫的內容也都是存放與內存中的,斷電後數據丟失
因而需要保存到硬盤上,點擊保存按鈕,就從內存中把數據刷到了硬盤上。
在這一點上,我們編寫一個py文件(沒有執行),跟編寫其他文件沒有任何區別,都只是在編寫一堆字符而已。
3
第一階段:python解釋器啟動,此時就相當於啟動了一個文本編輯器
第二階段:python解釋器相當於文本編輯器,去打開test.py文件,從硬盤上將test.py的文件內容讀入到內存中(小復習:pyhon的解釋性,決定了解釋器只關心文件內容,不關心文件後綴名)
第三階段:python解釋器解釋執行剛剛加載到內存中test.py的代碼( ps:在該階段,即執行時,才會識別python的語法,執行文件內代碼,執行到name="egon",會開辟內存空間存放字符串"egon")
總結:python解釋器於文件本編輯的異同
相同點:python解釋器是解釋執行文件內容的,因而python解釋器具備讀py文件的功能,這一點與文本編輯器一樣
不同點:文本編輯器將文件內容讀入內存後,是為了顯示/編輯,而python解釋器將文件內容讀入內存後,是為了執行(識別python語法)
1. 一個python文件中的內容是由一堆字符組成的(python文件未執行時)
2. python中的數據類型字符串是由一串字符組成的(python文件執行時)
強調!!!
強調!!!!
強調!!!
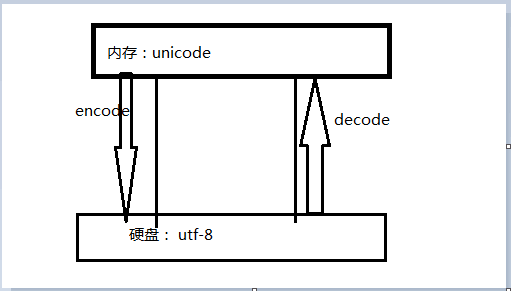
unicode:簡單粗暴,所有字符都是2Bytes,優點是字符->數字的轉換速度快,缺點是占用空間大
utf-8:精準,對不同的字符用不同的長度表示,優點是節省空間,缺點是:字符->數字的轉換速度慢,因為每次都需要計算出字符需要多長的Bytes才能夠準確表示
哪些場景涉及字符編碼?
- 內存中使用的編碼是unicode,用空間換時間(程序都需要加載到內存才能運行,因而內存應該是盡可能的保證快)
- 硬盤中或者網絡傳輸用utf-8,網絡I/O延遲或磁盤I/O延遲要遠大與utf-8的轉換延遲,而且I/O應該是盡可能地節省帶寬,保證數據傳輸的穩定性。
什麽是亂碼
文件從內存刷到硬盤的操作簡稱存文件
文件從硬盤讀到內存的操作簡稱讀文件
亂碼一:存文件時就已經亂碼
存文件時,由於文件內有各個國家的文字,我們單以shiftjis去存,
本質上其他國家的文字由於在shiftjis中沒有找到對應關系而導致存儲失敗,用open函數的write可以測試,f=open(‘a.txt‘,‘w‘,encodig=‘shift_jis‘)
f.write(‘你瞅啥\n何を見て\n‘) #‘你瞅啥‘因為在shiftjis中沒有找到對應關系而無法保存成功,只存‘何を見て\n‘可以成功
但當我們用文件編輯器去存的時候,編輯器會幫我們做轉換,保證中文也能用shiftjis存儲(硬存,必然亂碼),這就導致了,存文件階段就已經發生亂碼
此時當我們用shiftjis打開文件時,日文可以正常顯示,而中文則亂碼了
再或者,存文件時:
f=open(‘a.txt‘,‘wb‘) f.write(‘何を見て\n‘.encode(‘shift_jis‘)) f.write(‘你愁啥\n‘.encode(‘gbk‘)) f.write(‘你愁啥\n‘.encode(‘utf-8‘)) f.close()
以任何編碼打開文件a.txt都會出現其余兩個無法正常顯示的問題
亂碼二:存文件時不亂碼而讀文件時亂碼
存文件時用utf-8編碼,保證兼容萬國,不會亂碼,而讀文件時選擇了錯誤的解碼方式,比如gbk,則在讀階段發生亂碼,讀階段發生亂碼是可以解決的,選對正確的解碼方式就ok了,而存文件時亂碼,則是一種數據的損壞。
###程序的執行!!!
python test.py (我再強調一遍,執行test.py的第一步,一定是先將文件內容讀入到內存中)
階段一: 啟動python解釋器
階段二: python解釋器此時就是一個文本編輯器,負責打開文件test.py,即從硬盤中讀取test.py的內容到內存中
階段三: 讀取已經加載到內存的代碼(unicode編碼的二進制),然後執行,執行過程中可能會開辟新的內存空間,比如x="ff"
打印到終端
對於print需要特別說明的是:
當程序執行時,比如
x=‘林‘
print(x) #這一步是將x指向的那塊新的內存空間(非代碼所在的內存空間)中的內存,打印到終端,而終端仍然是運行於內存中的,所以這打印可以理解為從內存打印到內存,即內存->內存,unicode->unicode
對於unicode格式的數據來說,無論怎麽打印,都不會亂碼
python3中的字符串與python2中的u‘字符串‘,都是unicode,所以無論如何打印都不會亂碼
字符編碼就到這差不多就要結束了, 下面我代表組織給大家傳達一下組織近期的精神。 我希望大家用心聽,用心學,時間是寶貴的,我們要在最短的時間內,盡可能的學到更多更好更棒棒的東西喲! 每天進步一點點,一個星期就是一大步,不要和別人比,因為你需要戰勝的只由你自己。加油 , 我們都是最棒的 !!!
總結!!!!
1 以什麽編碼存的就要以什麽編碼取出
ps:內存固定使用unicode編碼,
我們可以控制的編碼是往硬盤存放或者基於網絡傳輸選擇編碼
2 數據是最先產生於內存中,是unicode格式,要想傳輸需要轉成bytes格式
#unicode----->encode(utf-8)------>bytes
拿到bytes,就可以往文件內存放或者基於網絡傳輸
#bytes------>decode(gbk)------->unicode
3 python3中字符串被識別成unicode
python3中的字符串encode得到bytes
4 了解
python2中的字符串就bytes
python2中在字符串前加u,就是unicode
以上就是字符編碼的基礎知識
下面我們就進入文件處理
一:文件操作的基本流程:
f = open(‘i.txt‘) #打開文件 first_line = f.readline() print(‘first line:‘,first_line) #讀一行 print(‘我是分隔線‘.center(50,‘-‘)) data = f.read()# 讀取剩下的所有內容,文件大時不要用 print(data) #打印讀取內容 f.close() #關閉文件
#不指定打開編碼,默認使用操作系統的編碼,windows為gbk,linux為utf-8,與解釋器編碼無關
f=open(‘chenli.txt‘,encoding=‘gbk‘) #在windows中默認使用的也是gbk編碼,此時不指定編碼也行
f.read()
二: 文件的打開方式
文件句柄 = open(‘文件路徑‘, ‘模式‘) #f=open(‘1.py,encoding=‘utf-8‘)
打開文件時,需要指定文件路徑和以何等方式打開文件,打開後,即可獲取該文件句柄,日後通過此文件句柄對該文件操作。
打開文件的模式有:
- r ,只讀模式【默認模式,文件必須存在,不存在則拋出異常】
- w,只寫模式【不可讀;不存在則創建;存在則清空內容】
- x, 只寫模式【不可讀;不存在則創建,存在則報錯】
- a, 追加模式【可讀; 不存在則創建;存在則只追加內容】
"+" 表示可以同時讀寫某個文件
- r+, 讀寫【可讀,可寫】
- w+,寫讀【可讀,可寫】
- x+ ,寫讀【可讀,可寫】
- a+, 寫讀【可讀,可寫】
"b"表示以字節的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
註:以b方式打開時,讀取到的內容是字節類型,寫入時也需要提供字節類型,不能指定編碼
# f=open(r‘aaaa.py‘,encoding=‘utf-8‘) #x=1
# # print(‘+++++>1‘,f.read())
# # print(type(data))
# # print(‘+++++>2‘,f.read())
# # print(‘+++++>3‘,f.read())
# f.close()
# print(f)
# f.read()
# # del f
#open:
1: 會面向操作系統發起一個系統調用,操作會打開一個文件。
2:在python中會產生一個值 只想操作系統打開的那個文件,我們可以把該值賦給一個變量
#回收資源:
1:f.close()一定要做,關閉操作系統打開的文件,即回收操作系統的資源
2:del f: 沒必要做,因為在python程序運行完畢後,會自動清理與該程序有關的所有內存空間。
#只讀模式, 文件不存在報錯
f = open(‘res.py‘,encoding=‘utf-8‘)
print(f.read())
print(f.readline(),end=‘‘)
print(f.readlines())
print(f.readable())
print(f.writable()) #False
f.close()
#文本文件:只寫模式,文件不存在則創建空文件,文件存在則清空
# f=open(‘new.txt‘,‘w‘,encoding=‘utf-8‘)
# f.write(‘1111111\n‘)
# f.writelines([‘22222\n‘,‘3333\n‘,‘444444\n‘])
# # print(f.writable())
# f.close()
#文本文件:只追加寫模式,文件不存在則創建,文件存在
# f=open(‘new_2‘,‘a‘,encoding=‘utf-8‘)
# print(f.readable())
# print(f.writable())
# f.write(‘33333\n‘)
# f.write(‘44444\n‘)
# f.writelines([‘5555\n‘,‘6666\n‘])
# f.close()
#rb
# f=open(‘aaaa.py‘,‘rb‘)
# print(f.read().decode(‘utf-8‘))
# f=open(‘1.jpg‘,‘rb‘)
# data=f.read()
#wb
# f=open(‘2.jpg‘,‘wb‘)
# f.write(data)
# f=open(‘new_3.txt‘,‘wb‘)
# f.write(‘aaaaa\n‘.encode(‘utf-8‘))
#ab
f=open(‘new_3.txt‘,‘ab‘)
f.write(‘aaaaa\n‘.encode(‘utf-8‘))
#上下文管理
# with open(‘aaaa.py‘,‘r‘,encoding=‘utf-8‘) as read_f,\
# open(‘aaaa_new.py‘,‘w‘,encoding=‘utf-8‘) as write_f:
# data=read_f.read()
# write_f.write(data)
#循環取文件每一行內容
# with open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) as f:
# while True:
# line=f.readline()
# if not line:break
# print(line,end=‘‘)
# lines=f.readlines() #只適用於小文件
# print(lines)
# data=f.read()
# print(type(data))
# for line in f: #推薦使用
# print(line,end=‘‘)
#文件的修改
#方式一:只適用於小文件
# import os
# with open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) as read_f,\
# open(‘a.txt.swap‘,‘w‘,encoding=‘utf-8‘) as write_f:
# data=read_f.read()
# write_f.write(data.replace(‘alex_SB‘,‘alex_BSB‘))
#
# os.remove(‘a.txt‘)
# os.rename(‘a.txt.swap‘,‘a.txt‘)
#方式二:
import os
with open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) as read_f,\
open(‘a.txt.swap‘,‘w‘,encoding=‘utf-8‘) as write_f:
for line in read_f:
write_f.write(line.replace(‘alex_BSB‘,‘BB_alex_SB‘))
os.remove(‘a.txt‘)
os.rename(‘a.txt.swap‘,‘a.txt‘)
day 10 字符編碼和文件處理 細節整理