
走入計算機的第四十一天(數據庫2表記錄的操作)
一 插入表記錄
1 插入一條數據 insert
insert [ info] table_name (字段名稱,。。。) values(值。。)
2 插入多條數據
insert [ info] table_name (字段名稱,。。。) values(值。。)
(字段名稱,。。。) values(值。。)
(字段名稱,。。。) values(值。。)
。。。。。。
(字段名稱,。。。) values(值。。)


二 修改表記錄
update table_name set 字段=值,字段=值。。。where 字句;

三 刪除表記錄
delete from table_name where 字句;

truncate table table_name; #將表全部刪除,然後在創建一個新表,字段還是一樣的。
四 查看表的記錄
查看語法:
select * |field1,filed2 。。。 from tab_name

where 條件
group by field
having by field
limit 限制條數
where 子句中可以使用:
比較運算符:
> < >= <= <> !=
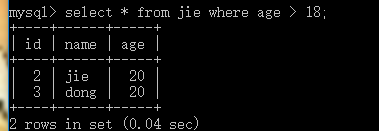
between n1 and n2 值在n1 到n2 之間
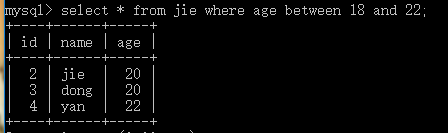
in(n1,n2,n3) 值是n1或n2或n3
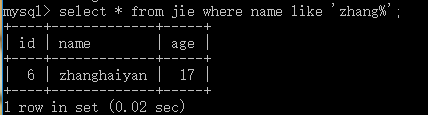
like ‘ %’ 以什麽什麽開頭
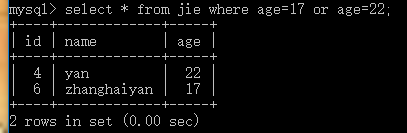
or and not 或與非
order by子句:
selest * | field1,field2.。。。 from tab_name order by filed [Asc |Desc]
——Asc 升序 , Desc 降序, 其中asc為默認值 order by子句應位於
select 組字段名,sum(字段名[int]) from order_menu group by 組字段名
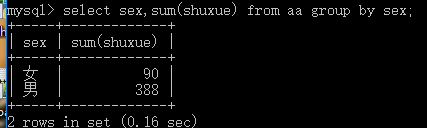
select 組字段名,sum(數字[int]) from order_menu group by 組字段名 having 條件;

/* having 和 where兩者都可以對查詢結果進行進一步的過濾,差別有: <1>where語句只能用在分組之前的篩選,having可以用在分組之後的篩 選; <2>使用where語句的地方都可以用having進行替換 <3>having中 可以用聚合函數,where中就不行。 */
聚合函數:
統計個數count:
select count(字段名) from ExamResult;
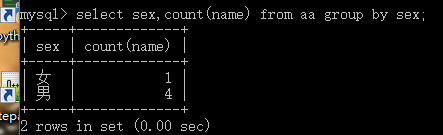
select count(字段名) from ExamResult where 條件;
滿足條件的行進行內容和 sum(字段名):
select sum(字段名【要求數字類型】)from ExamResult;
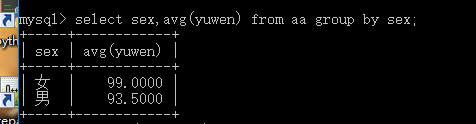
求取平均值avg(字段名):
select avg(字段名【要求數字類型】)from ExamResult;
最大,最小 max, min:
select max(字段名【要求數字類型】) from ExamRe;
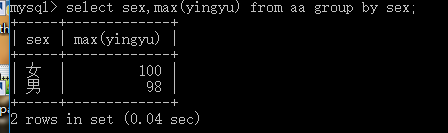
select min(字段名【要求數字類型】) from ExamRe;
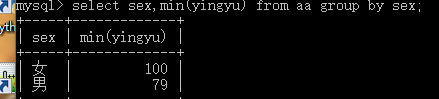
select語句的結尾。
limit 子句:
select * from ExamResult limit 數字;
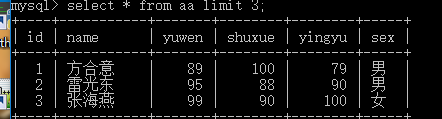
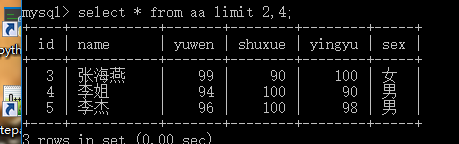
select * from ExamResult limit 數字,數字;
regexp使用:
select * from employee where emp_name regexp ‘^yu‘; 以什麽開頭

select * from employee where emp_name regexp ‘yuan$‘; 以什麽結尾
select * from employee where emp_name regexp ‘m{2}‘; 取幾個
從大到小:
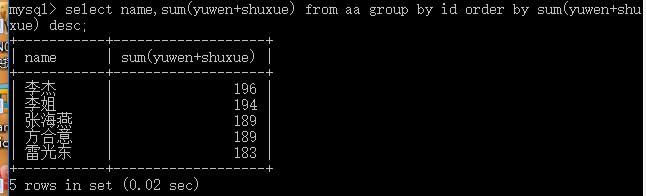
取最大
走入計算機的第四十一天(數據庫2表記錄的操作)