
postgresql中遭遇ERRORDATA_STACK_SIZE exceeded錯誤
在postgresql9.2中遇到一個錯誤,就是在流復制模式下,如果用psql訪問備機,無論執行什麽SQL語句,都會報ERRORDATA_STACK_SIZE exceeded錯誤。
網上搜了下這個錯,說是因為保存錯誤信息的棧溢出了。在postgresql.conf中,這個值默認是2M,按理說2M足夠了,因為一次錯誤報告沒那麽大。
這個值不能隨便設,它與操作系統有關。在centos下,系統默認是10M。postgres裏面這個值最大可以設為9.5M。

我把這個值調大了,仍然會報相同的錯誤。看來錯誤不在這裏。
於是,編一個debug版的pg,然後gdb跟進去看一下。在備機啟動pg後,用ps命令獲取postgres進程的pid,用gdb的attach追蹤這個pid。
運行psql,執行SQL語句。但是gdb卻追蹤不到:
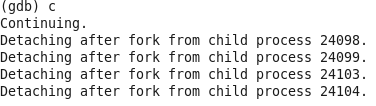
因為在備機狀態下,postgres會fork出子進程處理查詢請求:

其中24238是備機主進程,24289是它fork出來的子進程,用來處理查詢請求。
在調試的時候,你並不知道子進程的id,這個時候,gdb的一個參數就非常有用了,

這個follow-fork-mode可以設為兩個值,child和parent,設成child就可以追蹤調試進程所fork出來的子進程。
這可太方便了。
再次運行,一下子就跟到子進程中,找到了出錯的函數:
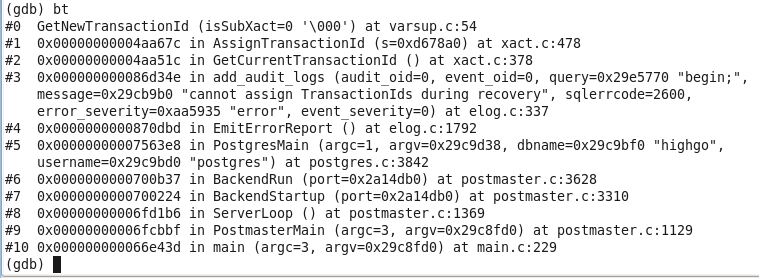
罪魁禍首就是add_audit_logs,這個函數是自己加進去的,目的是用來記錄一些審計信息。但是,在這個函數中會調用AssignTransactionId來得到一個新的事務id,但在備機模式下,是不允許創建事務id的:

RecoveryInProgress函數返回true,然後報錯。
接著,add_audit_logs會試圖記錄這條錯誤信息,然後又獲取新事務id,又引發上面這條錯誤。然後add_audit_logs又記錄這條錯誤。。。
死循環了,直到存放錯誤信息的棧被用光,報告棧溢出。
讓審計函數在備機模式下失效,就能避免此錯誤了。
postgresql中遭遇ERRORDATA_STACK_SIZE exceeded錯誤