
使用hadoop mapreduce分析mongodb數據
使用hadoop mapreduce分析mongodb數據
(現在很多互聯網爬蟲將數據存入mongdb中,所以研究了一下,寫此文檔)
版權聲明:本文為yunshuxueyuan原創文章。
如需轉載請標明出處: http://www.cnblogs.com/sxt-zkys/
QQ技術交流群:299142667
一、 mongdb的安裝和使用
1、 官網下載mongodb-linux-x86_64-rhel70-3.2.9.tgz

2、 解壓 (可以配置一下環境變量)
3、 啟動服務端
./mongod --dbpath=/opt/local/mongodb/data --logpath=/opt/local/mongodb/logs --logappend --fork(後臺啟動)
第一種:不帶auth認證的
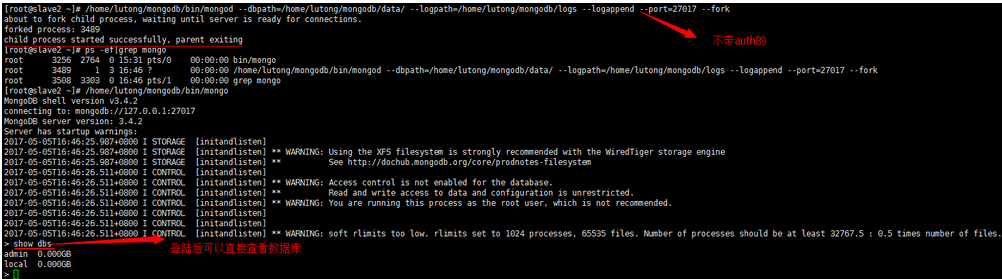
第二種:需要帶auth認證的(即需要用戶名和密碼的)
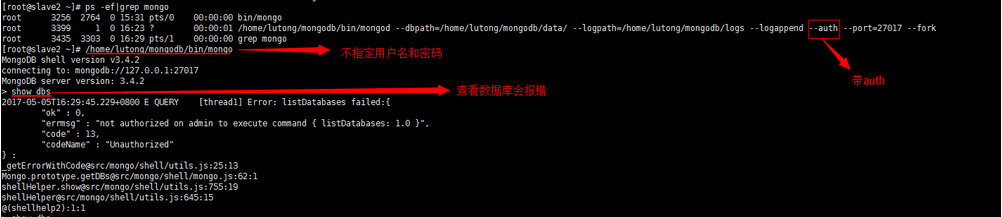
當指定用戶名和密碼在查看數據,發現就可以看得到了

4、 啟動客戶端
./mongo

5、客戶端shell命令
show dbs 顯示mongodb中有哪些數據庫
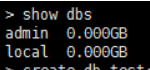
db 顯示當前正在用的數據庫
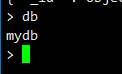
use db 你要使用的數據庫名
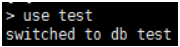
(註:若database不存在,則會創建一個,此時若不做任何操作直接退出,則MongoDB會刪除該數據庫)
db.auth(username,password) username為用戶名,password為密碼 登陸你要使用的數據庫
db.getCollectionNames() 查看當前數據庫有哪些表

db.[collectionName].insert({...}) 給指定數據庫添加文檔記錄

db.[collectionName].findOne() 查找文檔的第一條數據
db.[collectionName].find() 查找文檔的全部記錄

db.[collection].update({查詢條件},{$set:{更新內容}}) 更新一條文檔記錄

db.[collection].drop() 刪除數據庫中的集合

db.dropDatabase() 刪除數據庫
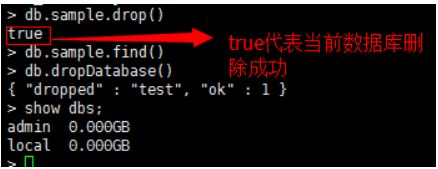
二、 Mapreduce 分析mongodb的數據實例
1、 編寫mapreduce的代碼前,需要另外添加兩個jar包,還有需(jdk1.7以上)


2、 需求介紹與實現
原數據:

結果數據:

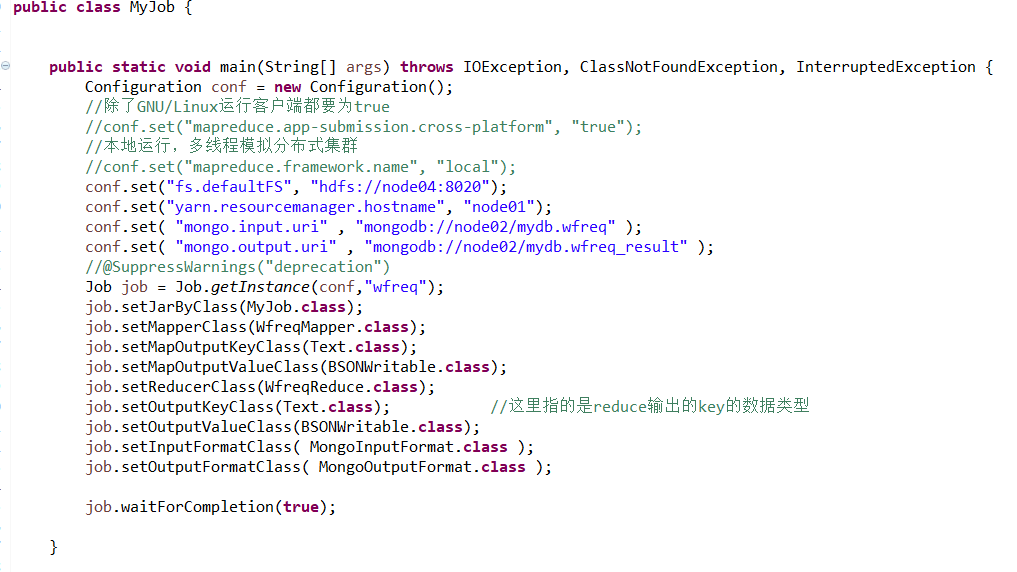
代碼編寫:
Job:
Mapper:

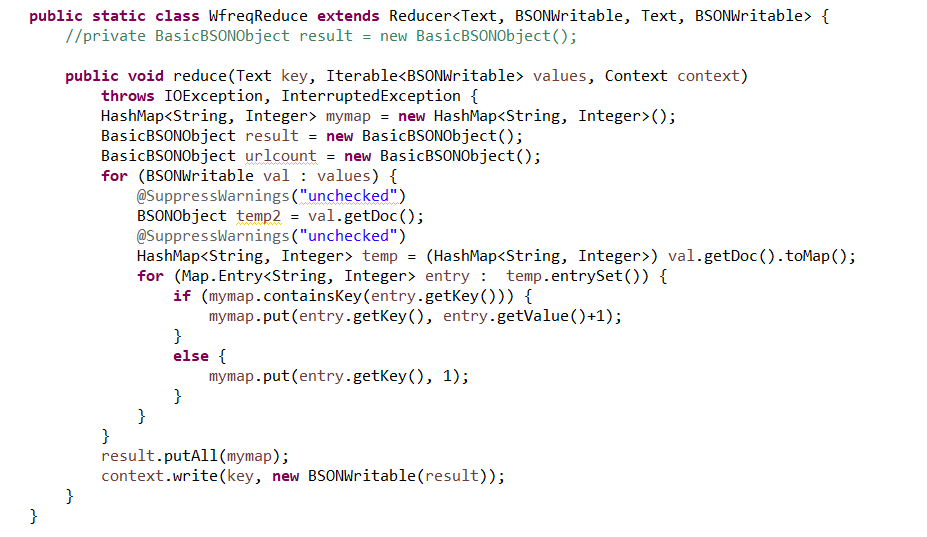
Reduce:
最終的結果數據:
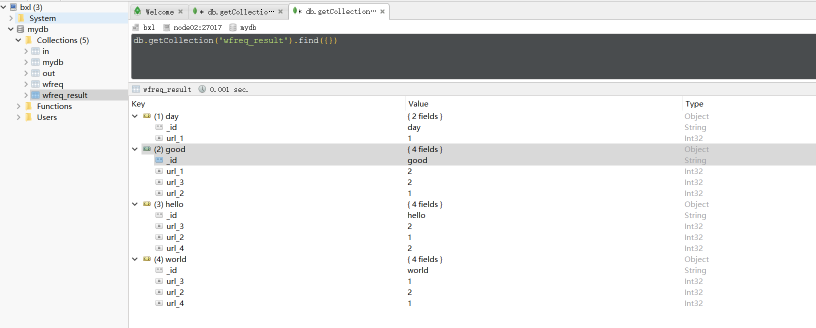
三、 最後給大家推薦一個mongodb數據庫的管理工具,挺好用的

版權聲明:本文為yunshuxueyuan原創文章。
如需轉載請標明出處: http://www.cnblogs.com/sxt-zkys/
QQ技術交流群:299142667
使用hadoop mapreduce分析mongodb數據