
Nginx探索三
這次探索一下http 請求
request
這節我們講request,在nginx中我們指的是http請求,詳細到nginx中的數據結構是ngx_http_request_t。
ngx_http_request_t是對一個http請求的封裝。 我們知道,一個http請求。包括請求行、請求頭、請求體、響應行、響應頭、響應體。
http請求是典型的請求-響應類型的的網絡協議,而http是文件協議。所以我們在分析請求行與請求頭,以及輸出響應行與響應頭。往往是一行一行的進行處理。
假設我們自己來寫一個httpserver,通常在一個連接建立好後,client會發送請求過來。然後我們讀取一行數據,分析出請求行中包括的method、uri、http_versio
得到請求後。我們處理請求產生須要輸出的數據,然後再生成響應行,響應頭以及響應體。在將響應發送給client之後。一個完整的請求就處理完了。當然這是最簡單的webserver的處理方式。事實上nginx也是這樣做的,僅僅是有一些小小的差別,比方。當請求頭讀取完畢後。就開始進行請求的處理了。nginx通過ngx_http_request_t來保存解析請求與輸出響應相關的數據。
那接下來,簡要講講nginx是怎樣處理一個完整的請求的。
對於nginx來說,一個請求是從ngx_http_init_request
從ngx_http_process_request_line的函數名。我們能夠看到。這就是來處理請求行的,正好與之前講的,處理請求的第一件事就是處理請求行是一致的。
通過ngx_http_read_request_header來讀取請求數據。然後調用ngx_http_parse_request_line函數來解析請求行。
nginx為提高效率,採用
url=iGhe26dksspE3-DzSHxarYJuoclLKVoeqCnwqOgRbw0XRIc1SLhVQ2hbR5sdpArzqDFMsD5WQD-aALm2GInAUK">狀態機
非常多人可能非常清楚一個請求行包括請求的方法,uri,版本號。卻不知道事實上在請求行中。也是能夠包括有host的。比方一個請求GET http://www.taobao.com/uri HTTP/1.0這樣一個請求行也是合法的,並且host是www.taobao.com,這個時候,nginx會忽略請求頭中的host域,而以請求行中的這個為準來查找虛擬主機。
另外。對於對於http0.9版來說,是不支持請求頭的,所以這裏也是要特別的處理。所以。在後面解析請求頭時。協議版本號都是1.0或1.1。整個請求行解析到的參數,會保存到ngx_http_request_t結構其中。
在解析完請求行後。nginx會設置讀事件的handler為ngx_http_process_request_headers,然後興許的請求就在ngx_http_process_request_headers中進行讀取與解析。
ngx_http_process_request_headers函數用來讀取請求頭,跟請求行一樣,還是調用ngx_http_read_request_header來讀取請求頭,調用ngx_http_parse_header_line來解析一行請求頭。解析到的請求頭會保存到ngx_http_request_t的域headers_in中,headers_in是一個鏈表結構。保存全部的請求頭。
而HTTP中有些請求是須要特別處理的。這些請求頭與請求處理函數存放在一個映射表裏面,即ngx_http_headers_in,在初始化時,會生成一個hash表,當每解析到一個請求頭後,就會先在這個hash表中查找,假設有找到,則調用對應的處理函數來處理這個請求頭。
比方:Host頭的處理函數是ngx_http_process_host。
當nginx解析到兩個回車換行符時,就表示請求頭的結束。此時就會調用ngx_http_process_request來處理請求了。
ngx_http_process_request會設置當前的連接的讀寫事件處理函數為ngx_http_request_handler,然後再調用ngx_http_handler來真正開始處理一個完整的http請求。
這裏可能比較奇怪,讀寫事件處理函數都是ngx_http_request_handler,事實上在這個函數中。會依據當前事件是讀事件還是寫事件。分別調用ngx_http_request_t中的read_event_handler或者是write_event_handler。因為此時。我們的請求頭已經讀取完畢了,之前有說過,nginx的做法是先不讀取請求body,所以這裏面我們設置read_event_handler為ngx_http_block_reading。即不讀取數據了。
剛才說到,真正開始處理數據,是在ngx_http_handler這個函數裏面,這個函數會設置write_event_handler為ngx_http_core_run_phases,並運行ngx_http_core_run_phases函數。
ngx_http_core_run_phases這個函數將運行多階段請求處理,nginx將一個http請求的處理分為多個階段,那麽這個函數就是運行這些階段來產生數據。由於ngx_http_core_run_phases最後會產生數據。所以我們就非常easy理解,為什麽設置寫事件的處理函數為ngx_http_core_run_phases了。
在這裏,我簡要說明了一下函數的調用邏輯。我們須要明確終於是調用ngx_http_core_run_phases來處理請求,產生的響應頭會放在ngx_http_request_t的headers_out中,這一部分內容,我會放在請求處理流程裏面去講。nginx的各種階段會對請求進行處理。最後會調用filter來過濾數據。對數據進行加工,如truncked傳輸、gzip壓縮等。
這裏的filter包含header filter與body filter。即對響應頭或響應體進行處理。filter是一個鏈表結構,分別有header filter與body filter,先運行header filter中的全部filter,然後再運行body filter中的全部filter。在header filter中的最後一個filter,即ngx_http_header_filter。這個filter將會遍歷全部的響應頭,最後須要輸出的響應頭在一個連續的內存。然後調用ngx_http_write_filter進行輸出。
ngx_http_write_filter是body filter中的最後一個。所以nginx首先的body信息,在經過一系列的body filter之後,最後也會調用ngx_http_write_filter來進行輸出(有圖來說明)。
這裏要註意的是,nginx會將整個請求頭都放在一個buffer裏面,這個buffer的大小通過配置項client_header_buffer_size來設置,假設用戶的請求頭太大,這個buffer裝不下。那nginx就會又一次分配一個新的更大的buffer來裝請求頭,這個大buffer能夠通過large_client_header_buffers來設置,這個large_buffer這一組buffer。比方配置4 8k,就是表示有四個8k大小的buffer能夠用。註意。為了保存請求行或請求頭的完整性,一個完整的請求行或請求頭,須要放在一個連續的內存裏面,所以。一個完整的請求行或請求頭。僅僅會保存在一個buffer裏面。
這樣,假設請求行大於一個buffer的大小。就會返回414錯誤。假設一個請求頭大小大於一個buffer大小。就會返回400錯誤。
在了解了這些參數的值。以及nginx實際的做法之後。在應用場景,我們就須要依據實際的需求來調整這些參數,來優化我們的程序了。
處理流程圖:
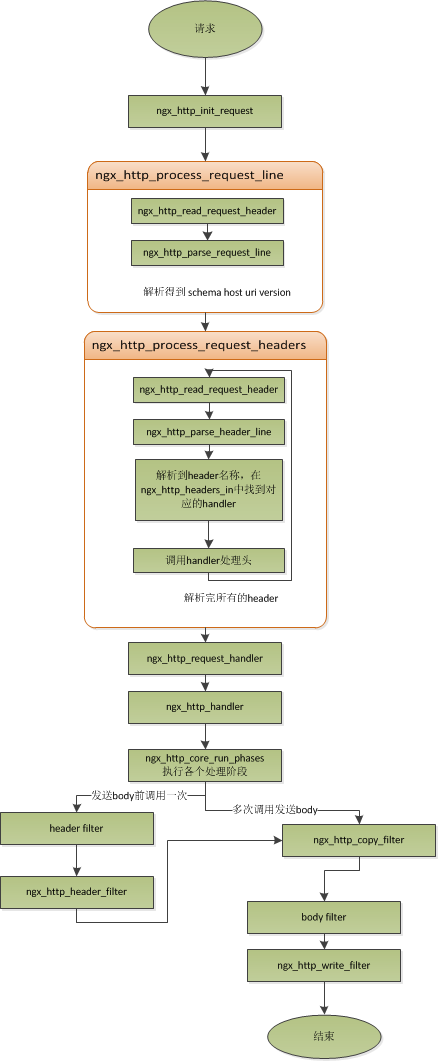
以上這些。就是nginx中一個http請求的生命周期了。我們再看看與請求相關的一些概念吧。
keepalive
當然,在nginx中,對於http1.0與http1.1也是支持長連接的。
什麽是長連接呢?我們知道。http請求是基於TCP協議之上的,那麽。當client在發起請求前,須要先與服務端建立TCP連接。而每一次的TCP連接是須要三次握手來確定的。假設client與服務端之間網絡差一點。這三次交互消費的時間會比較多。並且三次交互也會帶來網絡流量。當然。當連接斷開後。也會有四次的交互,當然對用戶體驗來說就不重要了。
而http請求是請求應答式的。假設我們能知道每一個請求頭與響應體的長度。那麽我們是可以在一個連接上面運行多個請求的,這就是所謂的長連接,但前提條件是我們先得確定請求頭與響應體的長度。對於請求來說。假設當前請求須要有body。如POST請求。那麽nginx就須要client在請求頭中指定content-length來表明body的大小。否則返回400錯誤。
也就是說,請求體的長度是確定的。那麽響應體的長度呢?先來看看http協議中關於響應body長度的確定:
- 對於http1.0協議來說,假設響應頭中有content-length頭,則以content-length的長度就能夠知道body的長度了,client在接收body時,就能夠依照這個長度來接收數據。接收完後,就表示這個請求完畢了。而假設沒有content-length頭,則client會一直接收數據,直到服務端主動斷開連接。才表示body接收完了。
- 而對於http1.1協議來說,如果響應頭中的Transfer-encoding為chunked傳輸。則表示body是流式輸出,body會被分成多個塊,(類似於對於流式傳輸解決粘包問題的做法)每塊的開始會標識出當前塊的長度。此時,body不須要通過長度來指定。假設是非chunked傳輸,並且有content-length。則依照content-length來接收數據。
否則,假設是非chunked,並且沒有content-length。則client接收數據。直到服務端主動斷開連接。
從上面。我們能夠看到。除了http1.0不帶content-length以及http1.1非chunked不帶content-length外,body的長度是可知的。
此時,當服務端在輸出完body之後。會能夠考慮使用長連接。是否能使用長連接,也是有條件限制的。假設client的請求頭中的connection為close,則表示client須要關掉長連接。假設為keep-alive。則client須要打開長連接。
假設client的請求中沒有connection這個頭,那麽依據協議,假設是http1.0。則默覺得close。假設是http1.1,則默覺得keep-alive。
假設結果為keepalive,那麽,nginx在輸出完響應體後。會設置當前連接的keepalive屬性,然後等待client下一次請求。當然,nginx不可能一直等待下去。假設client一直不發數據過來,豈不是一直占用這個連接?所以當nginx設置了keepalive等待下一次的請求時,同一時候也會設置一個最大等待時間,這個時間是通過選項keepalive_timeout來配置的,假設配置為0,則表示關掉keepalive,此時,http版本號不管是1.1還是1.0。client的connection不管是close還是keepalive。都會強制為close。
假設服務端最後的決定是keepalive打開,那麽在響應的http頭裏面,也會包括有connection頭域。其值是”Keep-Alive”,否則就是”Close”。假設connection值為close,那麽在nginx響應完數據後,會主動關掉連接。所以。對於請求量比較大的nginx來說,關掉keepalive最後會產生比較多的time-wait狀態的socket。
一般來說,當client的一次訪問。須要多次訪問同一個server時,打開keepalive的優勢非常大。比方圖片服務器。通常一個網頁會包括非常多個圖片。打開keepalive也會大量降低time-wait的數量。
(服務端timee-wait數量過多會影響服務端性能。由於很多套接字不能馬上被使用要設置地址復用)
pipe
在http1.1中,引入了一種新的特性。即pipeline。
那麽什麽是pipeline呢?pipeline事實上就是流水線作業,它能夠看作為keepalive的一種升華,由於pipeline也是基於長連接的,目的就是利用一個連接做多次請求。假設client要提交多個請求。對於keepalive來說。那麽第二個請求,必需要等到第一個請求的響應接收全然後,才幹發起,這和TCP的停止等待協議是一樣的。得到兩個響應的時間至少為2*RTT。
而對pipeline來說。client不必等到第一個請求處理完後,就能夠立即發起第二個請求。得到兩個響應的時間可能能夠達到1*RTT。nginx是直接支持pipeline的。(client的請求是並行的提高用戶體驗)可是,nginx對pipeline中的多個請求的處理卻不是並行的。依舊是一個請求接一個請求的處理,僅僅是在處理第一個請求的時候,client就能夠發起第二個請求。這樣。nginx利用pipeline降低了處理完一個請求後。等待第二個請求的請求頭數據的時間。
事實上nginx的做法非常easy。前面說到,nginx在讀取數據時,會將讀取的數據放到一個buffer裏面,所以。假設nginx在處理完前一個請求後,假設發現buffer裏面還有數據,就覺得剩下的數據是下一個請求的開始,然後就接下來處理下一個請求。否則就設置keepalive。
lingering_close
lingering_close。字面意思就是延遲關閉,也就是說,當nginx要關閉連接時。並不是馬上關閉連接,而是先關閉tcp連接的寫。再等待一段時間後再關掉連接的讀。
為什麽要這樣呢?我們先來看看這樣一個場景。
nginx在接收client的請求時,可能因為client或服務端出錯了,要馬上響應錯誤信息給client,而nginx在響應錯誤信息後,大分部情況下是須要關閉當前連接。nginx運行完write()系統調用把錯誤信息發送給client。write()系統調用返回成功並不表示數據已經發送到client,有可能還在tcp連接的write buffer裏(內核緩沖區中)。接著假設直接運行close()系統調用關閉tcp連接。內核會首先檢查tcp的read buffer裏有沒有client發送過來的數據留在內核態沒有被用戶態進程讀取。假設有則發送給clientRST報文來關閉tcp連接丟棄write buffer裏的數據,假設沒有則等待write buffer裏的數據發送完成,然後再經過正常的4次分手報文斷開連接。
所以,當在某些場景下出現tcp write buffer裏的數據在write()系統調用之後到close()系統調用運行之前沒有發送完成,且tcp read buffer裏面還有數據沒有讀。close()系統調用會導致client收到RST報文且不會拿到服務端發送過來的錯誤信息數據(由於錯誤信息在內核緩沖區中並沒有發送完,或者由於發送了RST包導致client忽略了)。
那client肯定會想,這server好霸道,動不動就reset我的連接。連個錯誤信息都沒有。
在上面這個場景中,我們能夠看到,關鍵點是服務端給client發送了RST包。導致自己發送的數據在client忽略掉了。所以,解決這個問題的重點是,讓服務端別發RST包。
再想想,我們發送RST是由於我們關掉了連接。關掉連接是由於我們不想再處理此連接了,也不會有不論什麽數據產生了。對於全雙工的TCP連接來說,我們僅僅須要關掉寫即可了。讀能夠繼續進行。我們僅僅須要丟掉讀到的不論什麽數據即可了,這種話,當我們關掉連接後,client再發過來的數據,就不會再收到RST了。
當然終於我們還是須要關掉這個讀端的。所以我們會設置一個超時時間,在這個時間過後,就關掉讀,client再發送數據來就無論了。作為服務端我會覺得。都這麽長時間了。發給你的錯誤信息也應該讀到了。再慢就不關我事了。要怪就怪你RP不好了。當然,正常的client,在讀取到數據後。會關掉連接,此時服務端就會在超時時間內關掉讀端。
這些正是lingering_close所做的事情。
協議棧提供 SO_LINGER 這個選項,它的一種配置情況就是來處理lingering_close的情況的,只是nginx是自己實現的lingering_close。lingering_close存在的意義就是來讀取剩下的client發來的數據,所以nginx會有一個讀超時時間,通過lingering_timeout選項來設置。假設在lingering_timeout時間內還沒有收到數據,則直接關掉連接。nginx還支持設置一個總的讀取時間,通過lingering_time來設置,這個時間也就是nginx在關閉寫之後,保留socket的時間。client須要在這個時間內發送全然部的數據。否則nginx在這個時間過後,會直接關掉連接。當然,nginx是支持配置是否打開lingering_close選項的,通過lingering_close選項來配置。 那麽。我們在實際應用中。是否應該打開lingering_close呢?
這個就沒有固定的推薦值了,如Maxim Dounin所說。lingering_close的主要作用是保持更好的client兼容性,可是卻須要消耗很多其它的額外資源(比方連接會一直占著)。
這節,我們介紹了nginx中。連接與請求的基本概念,下節。我們講主要的數據結構。
Nginx探索三