
SQL Server 並行操作優化,避免並行操作被抑制而影響SQL的執行效率
為什麽我也要說SQL Server的並行:
這幾天園子裏寫關於SQL Server並行的文章很多,不管怎麽樣,都讓人對並行操作有了更深刻的認識。 我想說的是:盡管並行操作可能(並不是一定)存在這樣或者那樣的問題,但是我們不能否認並行,仍然要利用好並行。 但是,實際開發中,某些SQL語句的寫法會導致用不到並行,從而影響到SQL的執行效率 所以,本文要表達的是:我們要利用好並行,不要讓一些SQL的寫法問題“抑制”了並行,讓我們享受不了並行帶來的快感
關於SQL Server的並行:
所謂的並行,指SQL Server對於那些執行代價相對較大(這個相對跟你的設置有關)的SQL時,如果數據庫服務器存在多顆CPU, SQL Server查詢引擎會采用並行的方式,也即采用多顆CPU參與整個運算過程,每顆CPU“分擔”一部分計算任務,最後匯總合並各個CPU的計算的一種行為 有時候,不當的並行查詢不但不會加快查詢的速度,想反會拖慢查詢的效率,如果采用不當的並行操作,甚至會影響到整個服務器的穩定性。 所以SQL Server 究竟在多大代價下啟用並行,是由配置的,這個配置可根據具體的情況做修改,有人說這個值的單位是“秒”,貌似沒見過權威的資料說過到底單位是什麽,這裏暫不追究 有清楚這個閾值單位的園友情不惜賜教,謝了
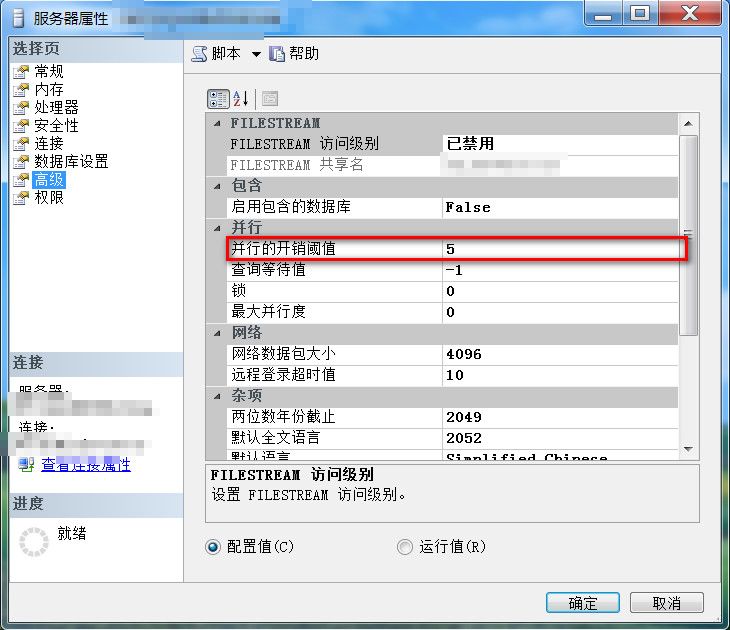
盡管並行操作可能存在這樣活著那樣的問題,但是我們不能因噎廢食,利用好並行,往往總是利大於弊。 但是並不是所有的執行代價較大SQL都能用到並行操作,實際開發中,有一些SQL的寫法會抑制到並行操作,結果,導致整個SQL語句(存儲過程)的效率上不去。 下面來舉例說明。
並行查詢是如何變成了串行的:
如下是一個非常簡單的查詢操作,這些寫法下,默認情況下開啟了並行,可以看到,一共開啟了8個線程來對SQL語句做計算。
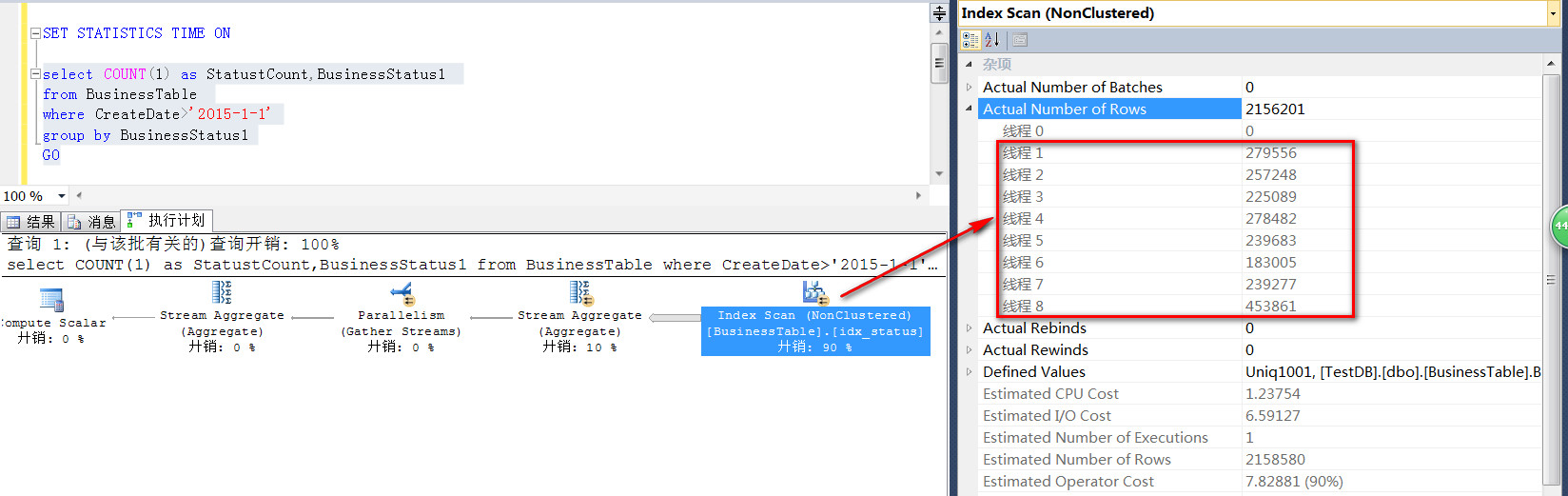
當然這SQL的執行效率還算不錯,CPU時間是622毫秒,執行總時間是130毫秒, 這裏不要弄混淆了,CPU時間的633毫秒,是8個CPU一共消耗的CPU時間,大於總的執行130毫秒很正常的
下面創建一個非常簡單的函數,
CREATE function [dbo].[fn_justFunction](@p_date date)
returns date
as
begin
return @p_date
end
這個函數並沒有什麽實際意義,執行也非常簡單,傳入一個時間,返回這個時間,
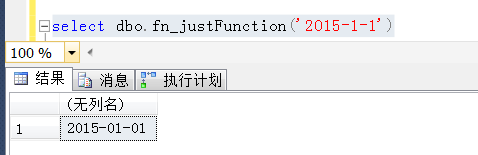
當然這裏只是為了下面的操作演示,你完全可以說我蛋疼,我只是為了演示並行被抑制的現象 翻翻你的SQL代碼,有沒有類似這種寫法?
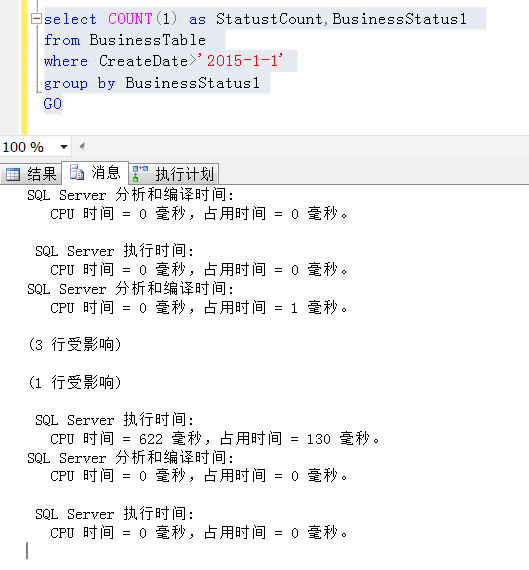
然後我們這麽寫這個查詢,就是在查詢條件上這麽處理CreateDate>dbo.fn_justFunction(‘2015-1-1‘)(註意不是表的列,而是函數作用在查詢條件上), 註意這個函數並不影響任何查詢結果,傳入的2015-1-1,返回位依舊是2015-1-1,但是這麽一變化,並行就變成串行的了, SQL執行期間只有一個CPU飈了起來,使用了到達80%左右,,與此同時其他CPU跟沒事人一樣,也不上來幫忙,還是很閑 還記得上面並行操作方式執行時間是多少麽?130毫秒,現在粗看起來是多少,這裏是4S,也就是4000毫秒
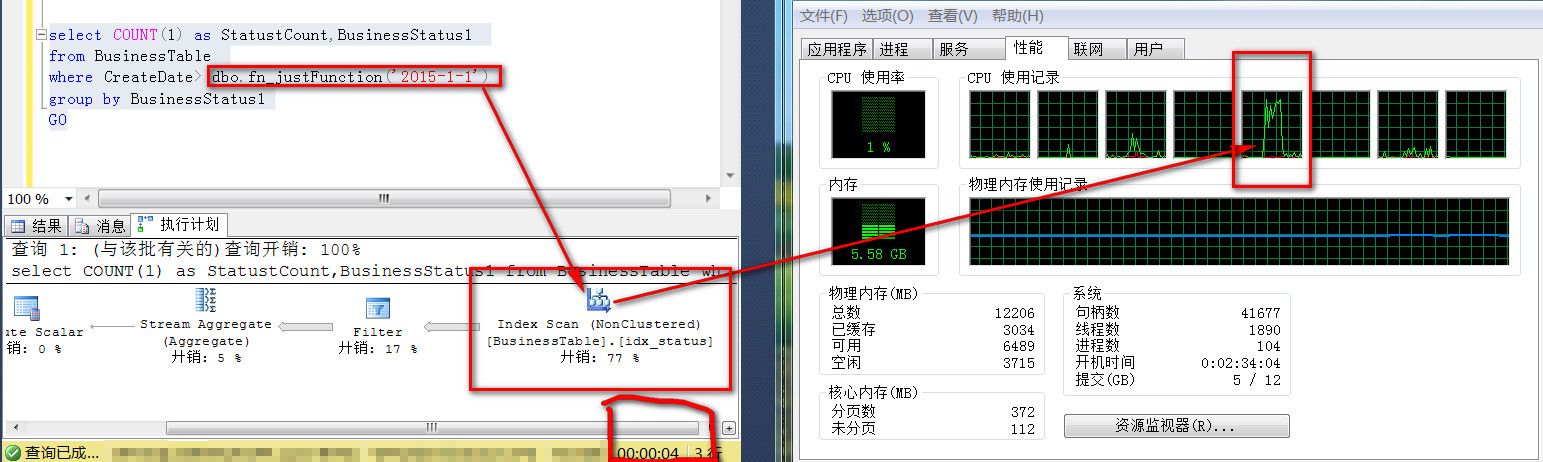
可以看到,並行操作和串行操作的效率差別還是很大的,對於CPU的利用也不充分(當然我不是強調一定要用滿所有的CPU才算合理) 再次強調一點,這裏並不是在表的字段上加函數抑制了索引什麽的,純粹的影響到的是並行操作。 當然,抑制並行的寫法不單單是在查詢條件在使用函數,實際開發中,影響會更大, 因為實際業務中數據有可能會更大,SQL也可能更加復雜,這種情況可能更加難以甄別。 比如連接條件上,如下,連接條件上使用函數導致無法使用並行的情況,也是實際開發中遇到的 select * from TableA a inner join TableB b on a.id=b.id and a.Column=dbo.function(@Variable) where *** 當然抑制到並行操作的不單單只有這兩種寫法,還有可能潛在其他類似的寫法也會影響到並行查詢。 這就要求我們在寫SQL的時候,不但要註意不能再字段上使用函數(無法使用該字段上的索引),同樣,查詢條件上也盡可能不要使用函數,有可能影響到並行操作。
總結起來有一下幾種情況會抑制到並行的使用(以後發現再更新):
1,將函數之類的操作作用在查詢條件上
比如:CreateDate>dbo.fn_justFunction(‘2015-1-1‘)
2,將函數之類的操作作用在連接條件上
比如:select * from TableA a inner join TableB b on a.id=b.id and a.Column=dbo.function(@Variable) where ***
3,強函數之類的操作作用在查詢列上
比如:FunctionName(ColumnName)>55,這種情況,如果查詢列上有索引,不僅僅是抑制索引,還會抑制並行
如何處理並行操作被抑制的情況:
如果要解決類似這些個問題,該怎麽辦? 其實也很簡單,建議查詢條件通過函數運算之後賦值給一個變量,用變量去作為查詢條件進行查詢。 再次開始了愉快的並行,享受並行帶來的快感。
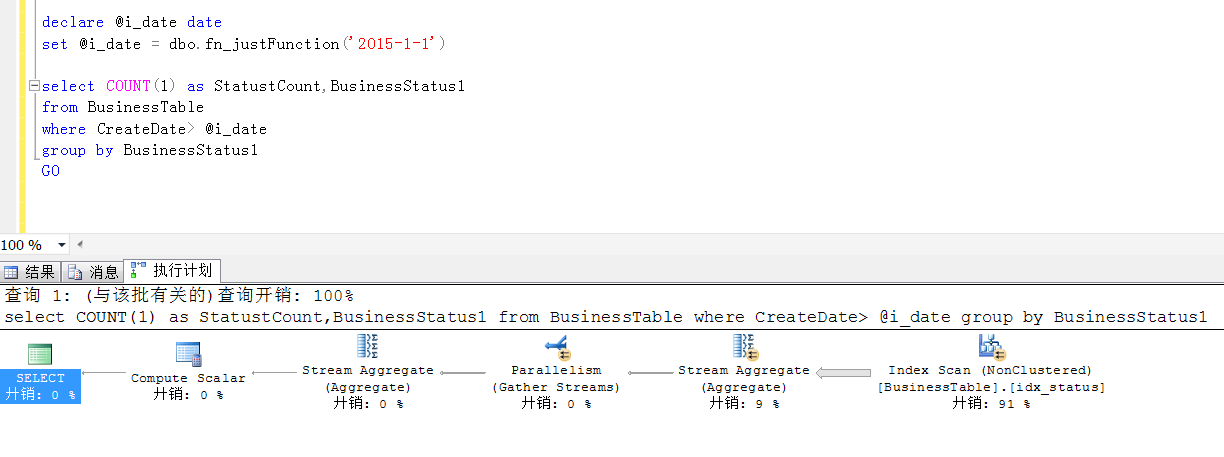
對於連接條件上的函數處理也類似,將結果計算出來之後,保存在一個變量中,把變量寫在連接條件中, 當然可能有其他辦法,我暫時還沒有想到。
總結:
本文通過一個簡單的例子演示了並行操作被抑制的現象,說明了並行和串行在執行一個代價較大的SQL上的性能的巨大的差別 其中提到的查詢方式是查詢條件上因為函數的原因抑制了並行,完全區別於在查詢列上使用函數抑制索引的情況。 並行查詢可以充分調動CPU資源,以高效的方式完成查詢,合理的利用並行會很大程度上提高SQL的執行效率。 為了利用好並行,在寫SQL的時候,一定要註意,防止並行操作遭到抑制,給性能帶來影響。
SQL優化是一個艱難而又反復的過程,即便如此,也樂在其中。 面對繁復SQL,不但要有過硬的技術,也要有足夠的耐心,才能看清事物的本質。 對並行的理解還不夠充分,有不對的地方希望各位看官指出,謝謝。
SQL Server 並行操作優化,避免並行操作被抑制而影響SQL的執行效率