
SQL Server 執行計劃利用統計信息對數據行的預估原理二(為什麽復合索引列順序會影響到執行計劃對數據行的預估)
本文出處:http://www.cnblogs.com/wy123/p/6008477.html
關於統計信息對數據行數做預估,之前寫過對非相關列(單獨或者單獨的索引列)進行預估時候的算法,參考這裏。 今天來寫一下統計信息對於復合索引在預估時候的計算方法和潛在問題。 本文原形來自於是個實際業務問題,某SQL在利用一個符合索引做查詢的時候,發現始終會出現預估誤差較大的情況, 而改變復合索引的列順序,這個預估行數的誤差會發生變化, 也就是說,Create index idx_index1 ON TableName(col1,col2)與Create index idx_index2 on TableName(col2,col1) 用完全一樣的的查詢條件做查詢,兩個索引的執行計劃對其預估的行數是不一樣的 究其原因在哪裏呢?
先造一個測試環境:

CREATE TABLE TestStatistics
(
COL1 INT IDENTITY(1,1) ,
COL2 INT ,
COL3 DATETIME ,
COL4 VARCHAR(50)
)
GO
INSERT INTO TestStatistics VALUES (RAND()*10,CAST(GETDATE()-RAND()*300 AS date),NEWID())
GO 1000000
問題重現
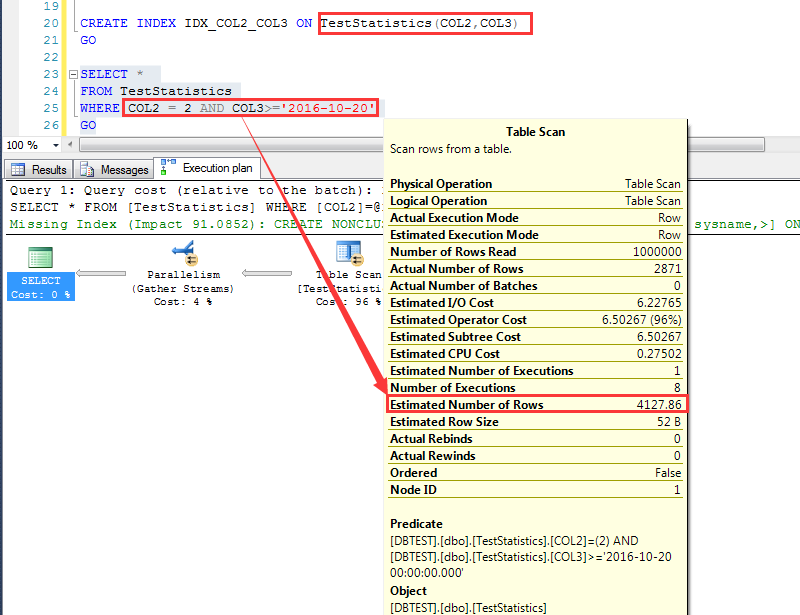
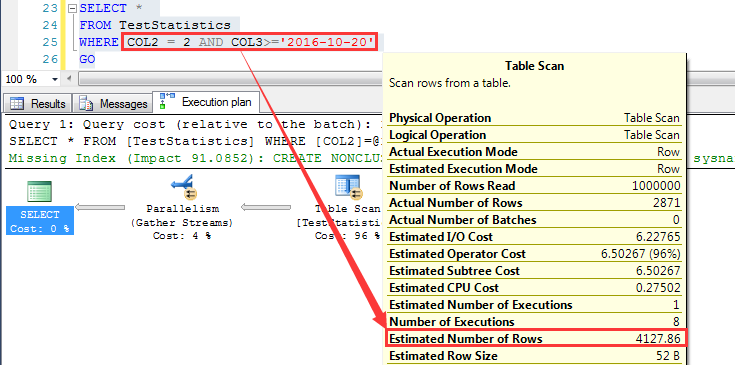
首先看一個非常有意思的問題, 在同一張表上, 先這麽建一個索引:CREATE INDEX IDX_COL2_COL3 ON TestStatistics(COL2,COL3) 執行一個查詢,預估為4127.86行 然後DROP掉上面的索引,繼續創建一個索引:CREATE INDEX IDX_COL3_COL2 ON TestStatistics(COL3,COL2) 註意COL2和COL3的順序不一致 繼續執行上面的查詢(查詢條件不變,數據不變,僅僅是索引列順序發生了變化),這一次預估為2414.91行
查詢條件一樣,數據也一樣,為什麽改變復合索引列順序會影響到執行計劃對數據行的預估呢?
首先來看第一個索引時候的預估算法:
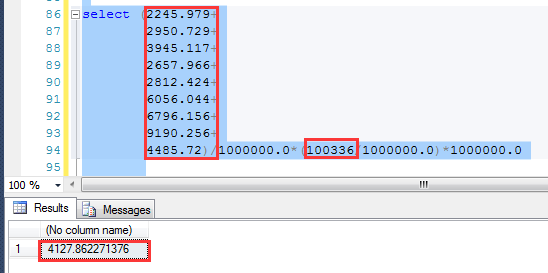
這個查詢他預估為4127.86行,如下圖
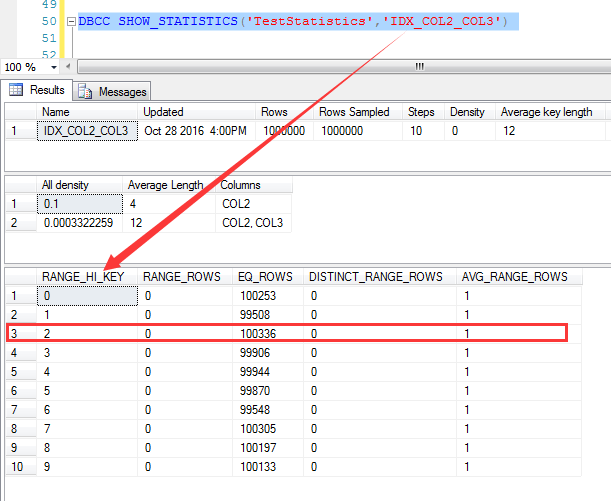
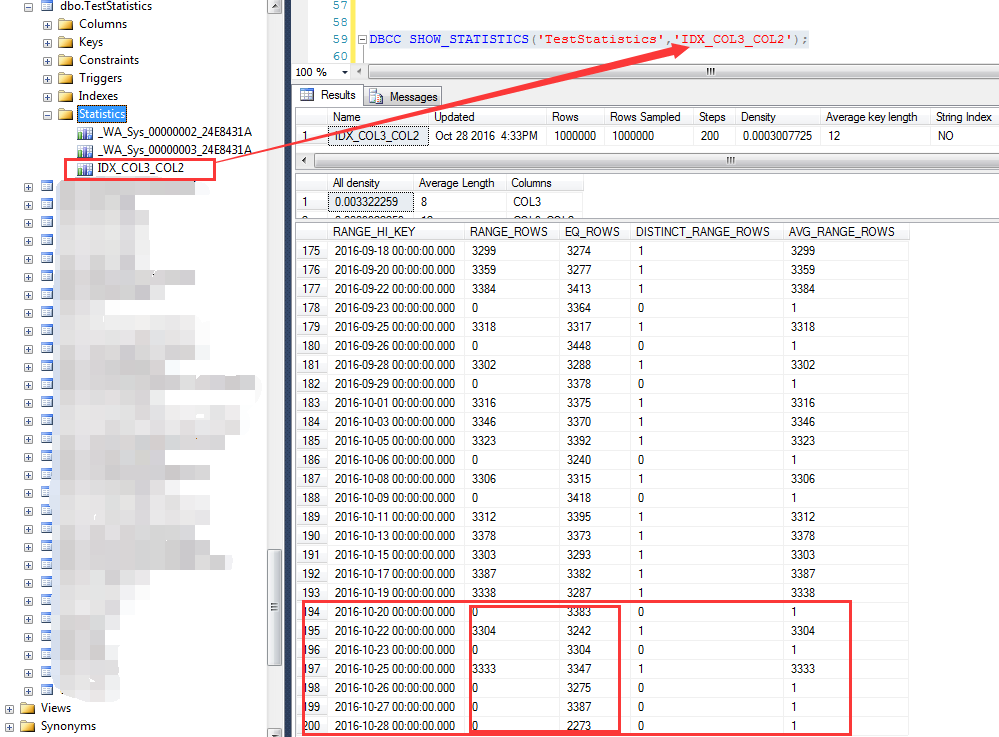
說起來預估,就離不開統計信息,首先來看IDX_COL2_COL3這個索引的統計信息, 我們知道,對於復合索引,統計信息中只有前導列的統計數據,也就是說IDX_COL3_COL2這個索引只有COL2這個列的統計信息,如下截圖 對於COL2=2的統計信息,統計為100336行,我們記住這個數字
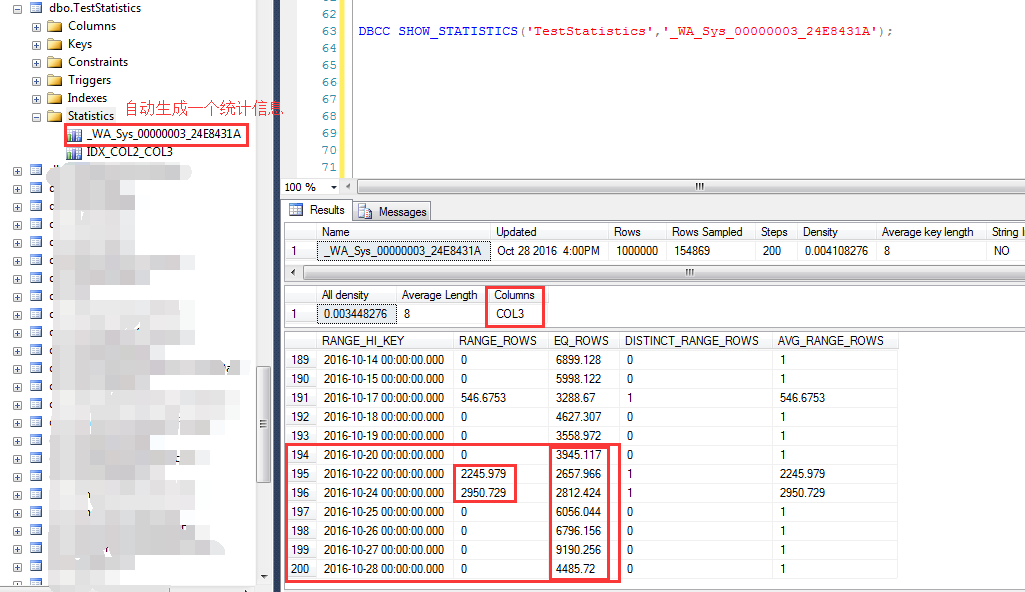
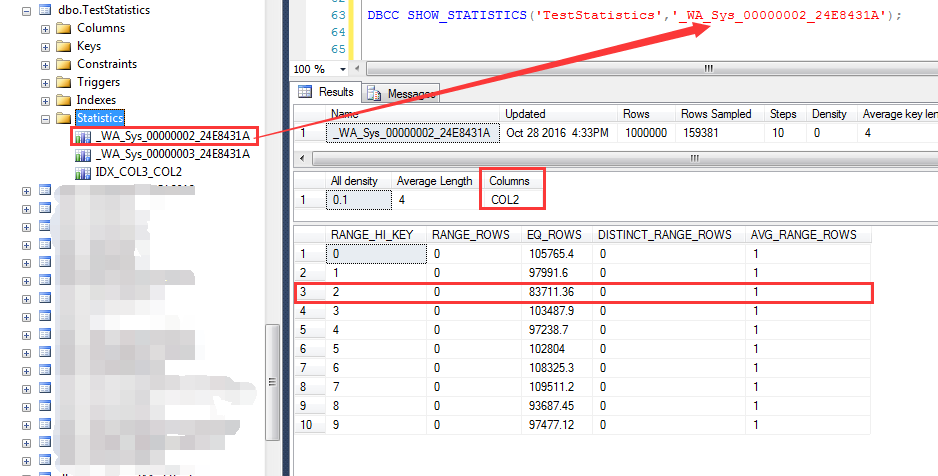
統計信息的另外一個特點就是在會在查詢列(非索引列)上自動創建統計信息,如下截圖 查詢執行過程中,自動創建了一個名字為:_WA_Sys_00000003_24E8431A的統計信息 這個統計信息就是對COL3列的統計,可以發現在大於等於2012-10-20之後的統計行數
在SQL Server 2012中,對數據行的預估計算方式是各個字段的選擇性的乘積, 假如Pn代表不同字段的密度,那麽預估行數的計算方法就是: 預估行數=p0*p1*p2*p3……*RowCount 可以利用這個算法,計算目前數據下,預估出來的結果:4217.86,跟執行計劃預估是一致的,非常完美!
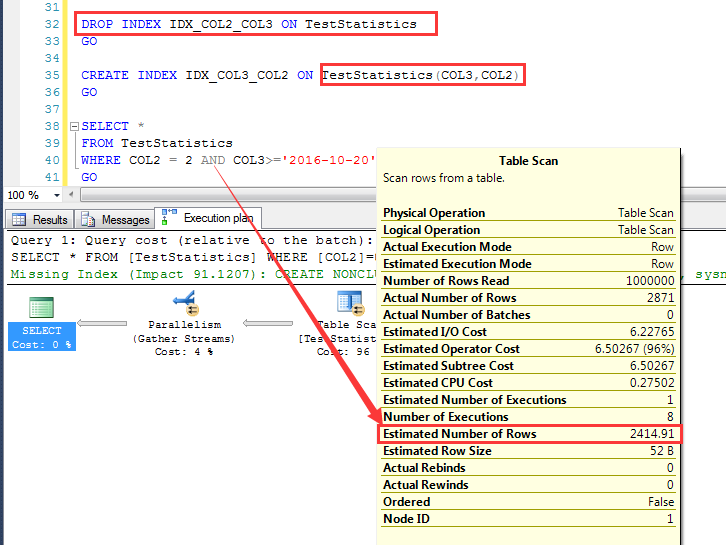
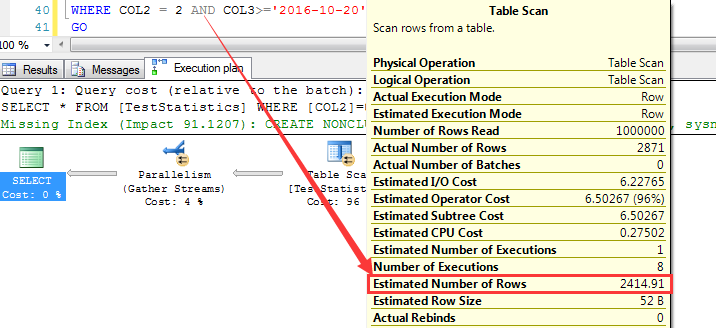
當刪除了IDX_COL2_COL3重建建立順序為COL3+COL2的索引的時候,預估如下
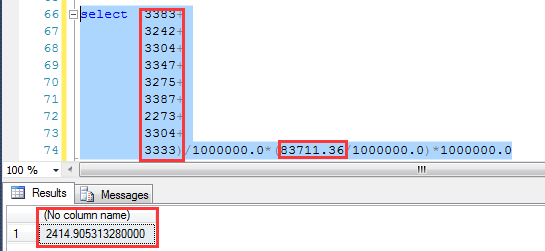
與上面同樣的查詢條件,預估為2414.91行
依據上面的分析步驟,首先來分析索引列上的統計信息,如下截圖為大於等於2016-10-20之後的預估行數
同理,本次查詢也會自動建立COL2列上的統計信息(IDX_COL2_COL3索引被刪除),觀察這個統計信息對COL2=2的預估為83711.36行
同樣我們利用上述公式,來計算預估的行數:2414.9035行,也非常完美地吻合和執行計劃預估的結果
至此,應該很清楚一開始的問題了,就是為什麽復合索引列順序不一致,在查詢的時候導致預估也不一致的原因。 最根本的原因有就是: 符合索引上只有前導列的統計信息,查詢引擎會根據需要自動創建非前導列的統計信息, 但是,非常關鍵一點,如果細心的話,你會發現查詢引擎自動創建的統計信息的取樣行數都不是100%取樣的,這一點非常關鍵 正是因為非前導列取樣有一定的誤差,導致在預估算法的時候,也即 預估行數=p0*p1*p2*p3……*RowCount的時候,密度值是不一樣的 也即在創建IDX_COL2_COL3的時候,統計出來的COL2密度為P1_1,COL3密度為P2_1, 創建IDX_COL3_COL2的時候,統計出來的COL2密度為P1_2,COL3密度為P2_2,因為P1_1<>P1_2,P2_1<>P2_2 因此,計算出的結果就是P1_1*P2_1<>P2_1*P2_2,原理很簡單,希望看官能明白。
照這麽計算,對於兩個順序不同的統計信息,如果P1_1=P2_1並且P2_1=P2_2,那麽乘積就是一樣的,預估行數也就是一樣的,那麽是不是呢?
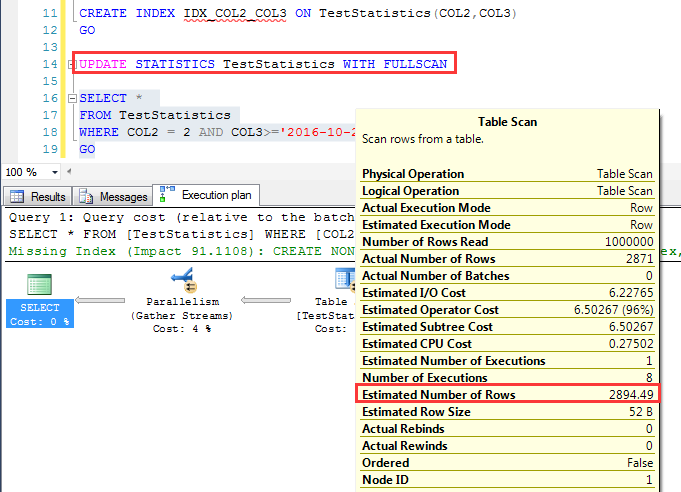
對於不同順序的兩個索引,先看COL2,COL3順序的索引 在查詢一次之後(建立了統計信息),執行一個百分之百取樣(WITH FULLSCAN)的統計信息更新 重新來看其預估行數,這一次預估為:2894.49
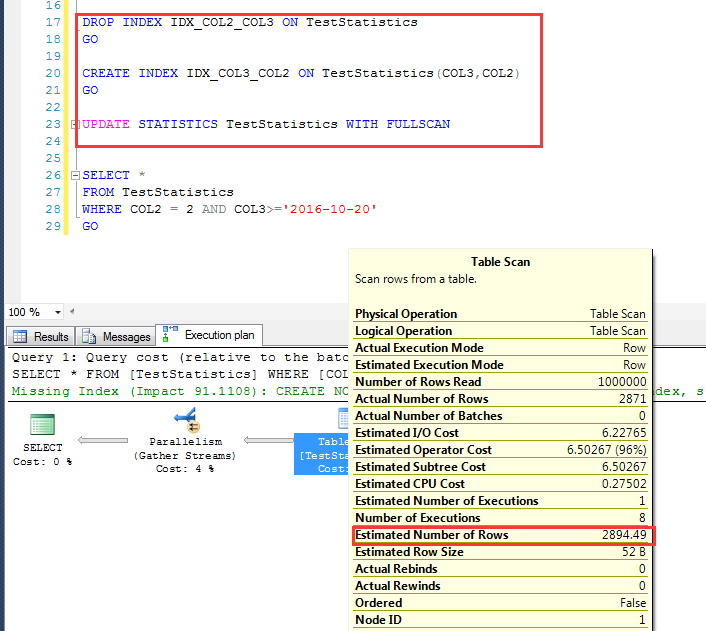
刪除COL2,COL3順序的索引,建立COL3,COL2為順序的索引 在查詢一次之後(建立了統計信息),執行一個百分之百取樣(WITH FULLSCAN)的統計信息更新 重新來看其預估行數,這一次預估為:同樣為2894.49,是吻合上述算法
總結:
文本簡單演示了執行計劃利用統計信息預估的算法和原理,以及在計算預估行數時候可能受到的幹擾因素, 這就要求我們在建立索引的時候,不僅僅是說我建一個復合索引就完事了,也要註意其索引列的順序對執行計劃預估的影響, 更重要的是,要註意查詢引擎自動生成的統計信息對預估的影響程度。
拋開統計信息談索引的,都是耍流氓。拋開統計信息取樣百分比談統計信息的,也是耍流氓。
引申出來另外一個問題:維護統計信息的時候,能只更新索引列的統計信息,忽略非索引列的統計信息嗎?
SQL Server 執行計劃利用統計信息對數據行的預估原理二(為什麽復合索引列順序會影響到執行計劃對數據行的預估)