
第三百三十八節,Python分布式爬蟲打造搜索引擎Scrapy精講—深度優先與廣度優先原理
第三百三十八節,Python分布式爬蟲打造搜索引擎Scrapy精講—深度優先與廣度優先原理

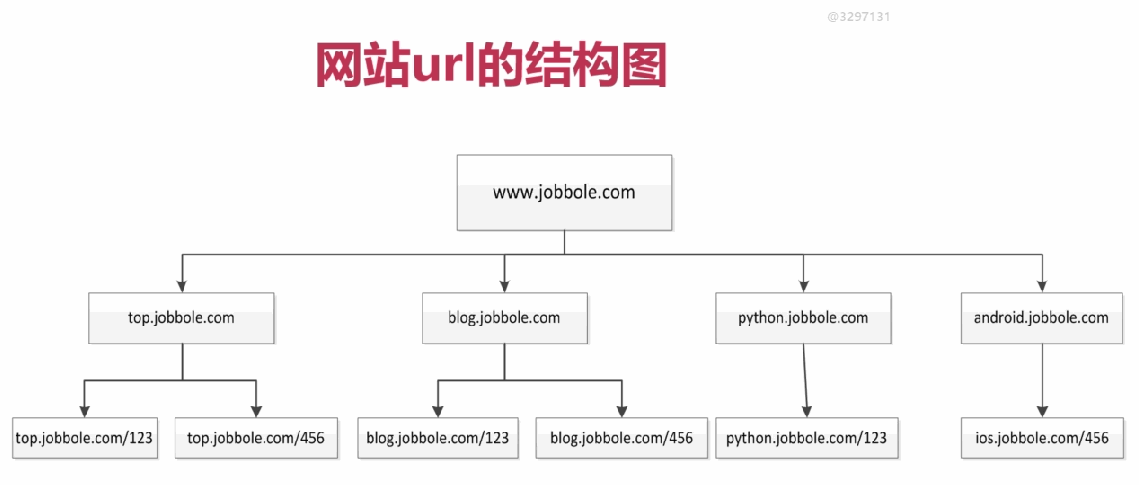
網站樹形結構
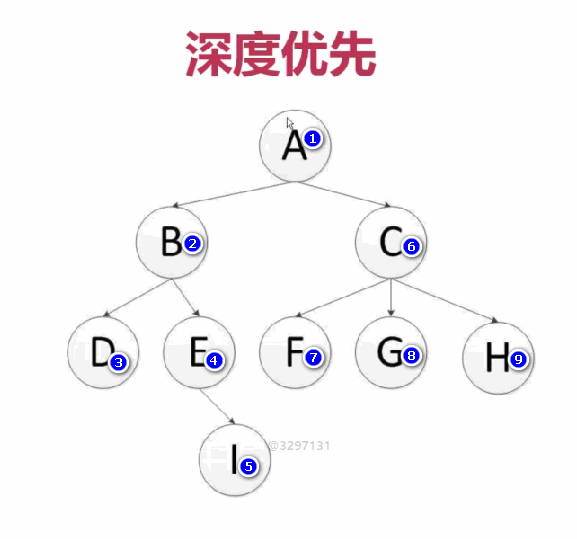
深度優先
是從左到右深度進行爬取的,以深度為準則從左到右的執行
第三百三十八節,Python分布式爬蟲打造搜索引擎Scrapy精講—深度優先與廣度優先原理
相關推薦
第三百五十八節,Python分布式爬蟲打造搜索引擎Scrapy精講—將bloomfilter(布隆過濾器)集成到scrapy-redis中
分布式爬蟲 times 操作 加載 ger 目錄 需要 ini space 第三百五十八節,Python分布式爬蟲打造搜索引擎Scrapy精講—將bloomfilter(布隆過濾器)集成到scrapy-redis中,判斷URL是否重復 布隆過濾器(Bloom Filte
第三百六十八節,Python分布式爬蟲打造搜索引擎Scrapy精講—elasticsearch(搜索引擎)用Django實現搜索的自動補全功能
技術 django 分布 全功能 -s col ron 搜索 創建 第三百六十八節,Python分布式爬蟲打造搜索引擎Scrapy精講—用Django實現搜索的自動補全功能 elasticsearch(搜索引擎)提供了自動補全接口 官方說明:https://www
第三百三十八節,Python分布式爬蟲打造搜索引擎Scrapy精講—深度優先與廣度優先原理
.com nbsp 網站 color -1 廣度 spa .cn png 第三百三十八節,Python分布式爬蟲打造搜索引擎Scrapy精講—深度優先與廣度優先原理 網站樹形結構 深度優先 是從左到右深度進行爬取的,以深度為準則從左到右的執行 第三百三十
第三百五十三節,Python分布式爬蟲打造搜索引擎Scrapy精講—scrapy的暫停與重啟
ctrl+ 裏的 dir 其中 重啟 requests 引擎 image .cn 第三百五十三節,Python分布式爬蟲打造搜索引擎Scrapy精講—scrapy的暫停與重啟 scrapy的每一個爬蟲,暫停時可以記錄暫停狀態以及爬取了哪些url,重啟時可以從暫停狀態開始
第三百五十四節,Python分布式爬蟲打造搜索引擎Scrapy精講—數據收集(Stats Collection)
ack 高效 所有 crawl resp spider 方法 啟動 定義 第三百五十四節,Python分布式爬蟲打造搜索引擎Scrapy精講—數據收集(Stats Collection) Scrapy提供了方便的收集數據的機制。數據以key/value方式存儲,值大多是
第三百五十五節,Python分布式爬蟲打造搜索引擎Scrapy精講—scrapy信號詳解
第一個 如果 -c stopped lin 支持 idle 資源 spider 第三百五十五節,Python分布式爬蟲打造搜索引擎Scrapy精講—scrapy信號詳解 信號一般使用信號分發器dispatcher.connect(),來設置信號,和信號觸發函數,當捕獲到信號
第三百六十一節,Python分布式爬蟲打造搜索引擎Scrapy精講—倒排索引
索引原理 文章 根據 file 索引 -i span 需要 style 第三百六十一節,Python分布式爬蟲打造搜索引擎Scrapy精講—倒排索引 倒排索引 倒排索引源於實際應用中需要根據屬性的值來查找記錄。這種索引表中的每一項都包括一個屬性值和具有該屬性值的各記錄的
第三百六十五節,Python分布式爬蟲打造搜索引擎Scrapy精講—elasticsearch(搜索引擎)的查詢
搜索引擎 ack 復合 分布式 內置 分布 在一起 一起 分類 第三百六十五節,Python分布式爬蟲打造搜索引擎Scrapy精講—elasticsearch(搜索引擎)的查詢 elasticsearch(搜索引擎)的查詢 elasticsearch是功能非常強大的搜索
Python分布式爬蟲打造搜索引擎網站(價值388元)
價值 基礎知識 也會 net line view 發的 職位 for 未來是什麽時代?是數據時代!數據分析服務、互聯網金融,數據建模、自然語言處理、醫療病例分析……越來越多的工作會基於數據來做,而爬蟲正是快速獲取數據最重要的方式,相比其它語言,Python爬蟲更簡單、高效
第三百九十八節,Django+Xadmin打造上線標準的在線教育平臺—生產環境部署Linux安裝nginx
兩個 騰訊 連接 自己 可執行 註意 help 需要 imap 第三百九十八節,Django+Xadmin打造上線標準的在線教育平臺—生產環境部署Linux安裝nginx Nginx簡介 Nginx是一款輕量級的Web 服務器/反向代理服務器及電子郵件(IMAP/POP
python分布式爬蟲搭建開發環境(二)
back col 性能 16px 動態網頁 網頁 ebs {} 常見類 scrapy 優勢: resquests和Beautifulsoup都是庫,scrapy是框架 scrapy框架可以加入前兩項 scrapy基於twisted,性能是最大的優勢 scrapy方便擴展,
21天搞定Python分布式爬蟲-知了課堂
保存 css 單元素 mongod mysql數據庫 god 圖片 騰訊 beautiful 01 【爬蟲前奏】什麽是網絡爬蟲 【錄播】【爬蟲前奏】什麽是網絡爬蟲(24分鐘) 免費試學 02 【爬蟲前奏】HTTP協議介紹 【錄播】【爬蟲前奏】HTTP協議介紹
聚焦Python分布式爬蟲必學框架Scrapy 打造搜索引擎
表結構 如何 extract requests 知識 utf 高級特性 cookie pan 第1章 課程介紹介紹課程目標、通過課程能學習到的內容、和系統開發前需要具備的知識 第2章 windows下搭建開發環境介紹項目開發需要安裝的開發軟件、 python虛擬virtua
第三百八十三節,Django+Xadmin打造上線標準的在線教育平臺—路由映射與靜態文件配置
是否 操作數 列表 errors ner rate 郵箱 scrip user 第三百八十四節,Django+Xadmin打造上線標準的在線教育平臺—路由映射與靜態文件配置以及會員註冊 基於類的路由映射 from django.conf.urls import url
《人在囧途》系列 - 都說“三百六十行,行行轉碼農”0基礎轉行程式設計師 路該怎麼走?
1. 緣起 《人在囧途》這個系列主要是為了給內外行業的人指點迷津,讓大家不再困惑,不再囧;在這個喧囂的世界想必大家總想尋覓一處寧靜的地方,憩息自己的心靈世界,讓疲於奔波的軀體暫時歸於靜止。或許是紅塵過於喧囂,還是生活太過緊張,魂靈總是在動盪不安中;因此這個系列也給各位提供一個心靈的港灣,由你講述發生在你身
第二百八十八節,MySQL數據庫-索引
創建 mysql數據庫 組合 logs pan 找到 根據 存放位置 全表掃描 MySQL數據庫-索引 索引,是數據庫中專門用於幫助用戶快速查詢數據的一種數據結構。類似於字典中的目錄,查找字典內容時可以根據目錄查找到數據的存放位置,然後直接獲取即可。 如果沒有創建索引查
集群搭建(三)Hadoop搭建HDFS(完全分布式)
意思 cati 臨時 等於 style www 比較 環境變量 AD Hadoop集群搭建(完全分布式) 前期準備(4臺linux服務器),具體搭建過程可以參考https://www.cnblogs.com/monco/p/9046614.html(克隆虛擬機比較方便)
螞蟻金服十年自研分布式中間件,成就世界級新金融科技平臺
承諾 images 金字塔 題解 形象 付出 7月 區分 統架構 中間件,是與操作系統和數據庫並列的傳統基礎軟件三駕馬車之一,也是難度極高的軟件工程。傳統中間件的概念,誕生於上一個“分布式”計算的年代,也就是小規模局域網中的服務器/客戶端計算模式,在操作系統之上、應用軟件之
python分布式進程
分配任務 pre rom turn odin time bsp process add 分布式進程可以布置在局域網之中,把安排的任務註冊到局域網內,不同主機之間就可以傳遞信息,從而分配任務和反饋,不過並不適合返回大量數據; 首先需要一個服務器server,用來存放數據,其他
36套精品Java高級課,架構課,java8新特性,P2P金融項目,程序設計,功能設計,數據庫設計,第三方支付,web安全,高並發,高性能,高可用,分布式,集群,電商,緩存,性能調優,設計模式,項目實戰,大型分布式電商項目實戰視頻教程
java cti 投資 調優 dubbo pac 性能 -s clas 36套精品Java高級課,架構課,java8新特性,P2P金融項目,程序設計,功能設計,數據庫設計,第三方支付,web安全,高並發,高性能,高可用,分布式,集群,電商,緩存,性能調優,設計模式,項