
將java開發的wordcount程序提交到spark集群上運行
今天來分享下將java開發的wordcount程序提交到spark集群上運行的步驟。
第一個步驟之前,先上傳文本文件,spark.txt,然用命令hadoop fs -put spark.txt /spark.txt,即可。
第一:看整個代碼視圖
打開WordCountCluster.java源文件,修改此處代碼:

第二步:
打好jar包,步驟是右擊項目文件----RunAs--Run Configurations
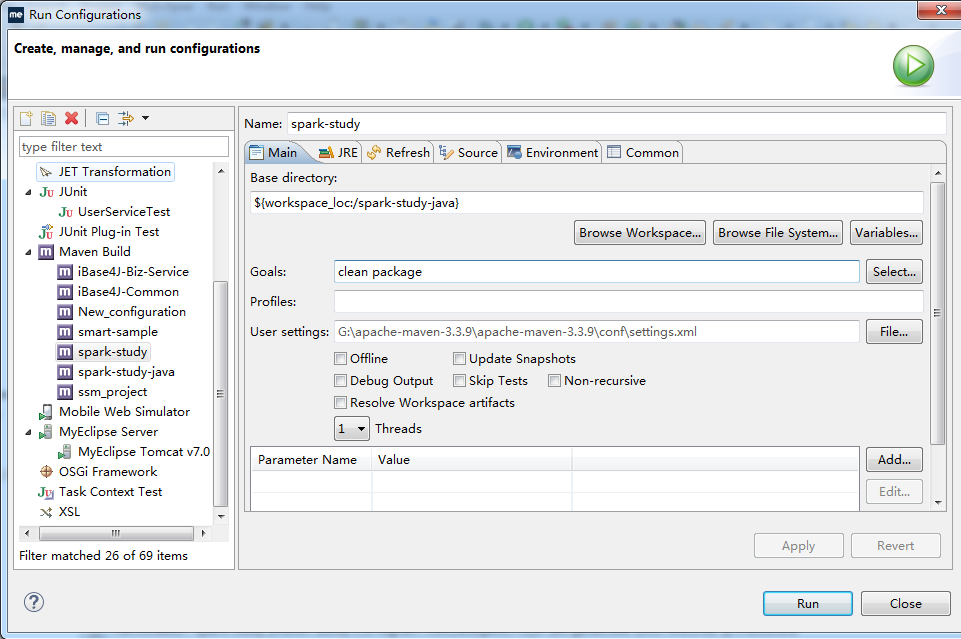
照圖填寫,然後開始拷貝工程下的jar包,如圖,註意是拷貝那個依賴jar包,不是第二個
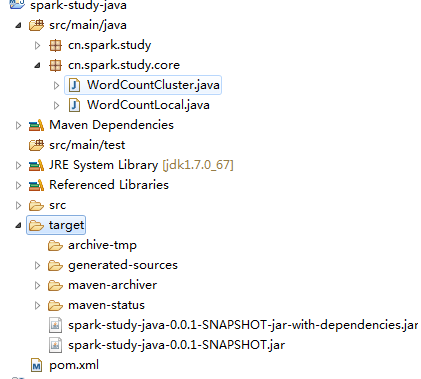
然後將復制到桌面的這個jar包和另外一個文件WordCount.sh上傳到平臺上,即拖拽到平臺上
開始使用上傳命令hadoop fs -put spark.txt /spark.txt。
第三步:要啟動hadoop集群,啟動方式見hadoop配置博文,註意,如果集群裏面的datanode或者是namenode之一沒有啟動,則找到這樣一個目錄,並刪除裏面的文件,重新啟動即可,如圖:即home目錄下的文件

打開home目錄下的hadoop----dfs-----把裏面的兩個目錄都刪除掉,即可
第四步:此時hadoop集群已經啟動,然後我們開始修改WordCount.sh配置文件
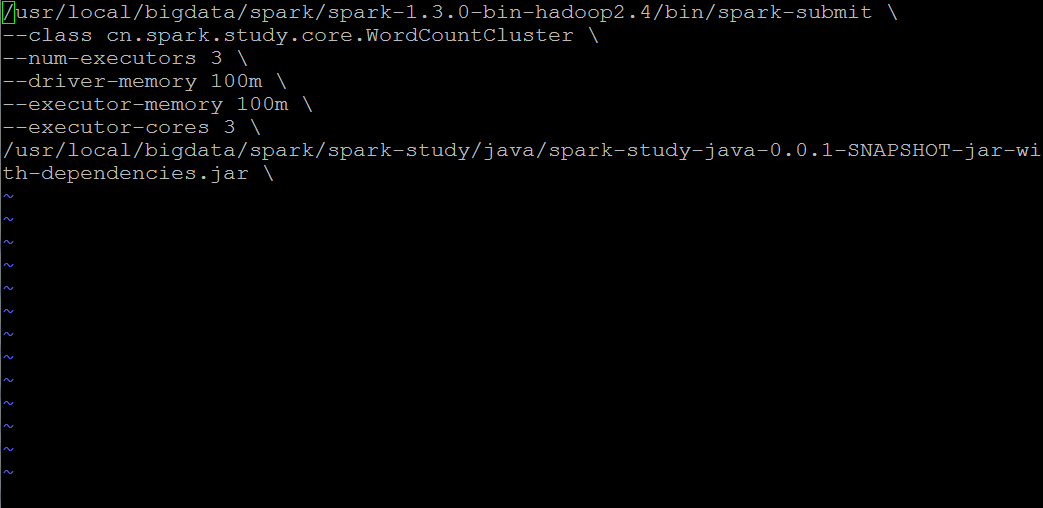
幾點註意:
1,class目錄必須對應你的eclipse工程下的項目目錄
2,關於spark-submit提交工具,路徑要和你的spark集群上面的路徑一致 ,這裏找的是spark集群下的bin目錄裏面的文件,不是spark-study下的文件,切記
3,最後一行路徑就是你的上傳程序jar包到平臺上後的路徑,註意一定是後綴為jar的文件包,不能上傳其它的後綴名,一律無效。
4,註意:修改過本地eclipse的程序文件,一定要生效的話,就要重新上傳打包,然後部署。
第五步,啟動程序文件,即如下圖,在wordcount.sh配置文件的目錄下,執行以下命令即可

將java開發的wordcount程序提交到spark集群上運行