
day24:常用模塊
一、time模塊
1.時間表示形式
在Python中,通常有這三種方式來表示時間:時間戳、元組(struct_time)、格式化的時間字符串:
(1)時間戳(timestamp) :通常來說,時間戳表示的是從1970年1月1日00:00:00開始按秒計算的偏移量。我們運行“type(time.time())”,返回的是float類型。
(2)格式化的時間字符串(Format String): ‘1988-03-16’
(3)元組(struct_time) :struct_time元組共有9個元素共九個元素:(年,月,日,時,分,秒,一年中第幾周,一年中第幾天等)
ormat time結構化表示
| 格式 | 含義 |
| %a | 本地(locale)簡化星期名稱 |
| %A | 本地完整星期名稱 |
| %b | 本地簡化月份名稱 |
| %B | 本地完整月份名稱 |
| %c | 本地相應的日期和時間表示 |
| %d | 一個月中的第幾天(01 - 31) |
| %H | 一天中的第幾個小時(24小時制,00 - 23) |
| %I | 第幾個小時(12小時制,01 - 12) |
| %j | 一年中的第幾天(001 - 366) |
| %m | 月份(01 - 12) |
| %M | 分鐘數(00 - 59) |
| %p | 本地am或者pm的相應符 |
| %S | 秒(01 - 61) |
| %U | 一年中的星期數。(00 - 53星期天是一個星期的開始。)第一個星期天之前的所有天數都放在第0周。 |
| %w | 一個星期中的第幾天(0 - 6,0是星期天) |
| %W | 和%U基本相同,不同的是%W以星期一為一個星期的開始。 |
| %x | 本地相應日期 |
| %X | 本地相應時間 |
| %y | 去掉世紀的年份(00 - 99) |
| %Y | 完整的年份 |
| %Z | 時區的名字(如果不存在為空字符) |
| %% | ‘%’字符 |

# <1> 時間戳 >>> import time >>> time.time() #--------------返回當前時間的時間戳 1493136727.099066 # <2> 時間字符串
>>> time.strftime("%Y-%m-%d %X") ‘2017-04-26 00:32:18‘ # <3> 時間元組
>>> time.localtime() time.struct_time(tm_year=2017, tm_mon=4, tm_mday=26, tm_hour=0, tm_min=32, tm_sec=42, tm_wday=2, tm_yday=116, tm_isdst=0)
小結:時間戳是計算機能夠識別的時間;時間字符串是人能夠看懂的時間;元組則是用來操作時間的
2.幾種時間形式的轉換
(1)
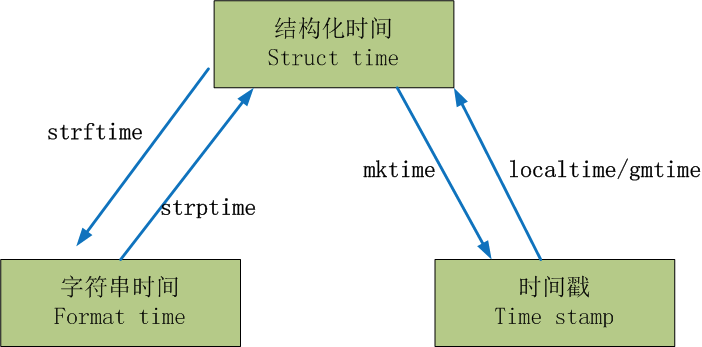
#一 時間戳<---->結構化時間: localtime/gmtime mktime
>>> time.localtime(3600*24)
>>> time.gmtime(3600*24)
>>> time.mktime(time.localtime())
#字符串時間<---->結構化時間: strftime/strptime
>>> time.strftime("%Y-%m-%d %X", time.localtime())
>>> time.strptime("2017-03-16","%Y-%m-%d")
(2)

>>> time.asctime(time.localtime(312343423)) ‘Sun Nov 25 10:03:43 1979‘ >>> time.ctime(312343423) ‘Sun Nov 25 10:03:43 1979‘
1 #--------------------------其他方法 2 # sleep(secs) 3 # 線程推遲指定的時間運行,單位為秒。
二、random模塊
>>> import random >>> random.random() # 大於0且小於1之間的小數 0.7664338663654585 >>> random.randint(1,5) # 大於等於1且小於等於5之間的整數 2 >>> random.randrange(1,3) # 大於等於1且小於3之間的整數 1 >>> random.choice([1,‘23‘,[4,5]]) # #1或者23或者[4,5] 1 >>> random.sample([1,‘23‘,[4,5]],2) # #列表元素任意2個組合 [[4, 5], ‘23‘] >>> random.uniform(1,3) #大於1小於3的小數 1.6270147180533838 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打亂次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
練習:生成驗證碼


import random def v_code(): code = ‘‘ for i in range(5): num=random.randint(0,9) alf=chr(random.randint(65,90)) add=random.choice([num,alf]) code="".join([code,str(add)]) return code print(v_code())View Code
三、hashlib模塊
3.1 算法介紹
Python的hashlib提供了常見的摘要算法,如MD5,SHA1等等。
什麽是摘要算法呢?摘要算法又稱哈希算法、散列算法。它通過一個函數,把任意長度的數據轉換為一個長度固定的數據串(通常用16進制的字符串表示)。
摘要算法就是通過摘要函數f()對任意長度的數據data計算出固定長度的摘要digest,目的是為了發現原始數據是否被人篡改過。
摘要算法之所以能指出數據是否被篡改過,就是因為摘要函數是一個單向函數,計算f(data)很容易,但通過digest反推data卻非常困難。而且,對原始數據做一個bit的修改,都會導致計算出的摘要完全不同。
我們以常見的摘要算法MD5為例,計算出一個字符串的MD5值:
import hashlib md5 = hashlib.md5() md5.update(‘how to use md5 in python hashlib?‘) print md5.hexdigest() 計算結果如下: d26a53750bc40b38b65a520292f69306
如果數據量很大,可以分塊多次調用update(),最後計算的結果是一樣的:
md5 = hashlib.md5() md5.update(‘how to use md5 in ‘) md5.update(‘python hashlib?‘) print md5.hexdigest()
MD5是最常見的摘要算法,速度很快,生成結果是固定的128 bit字節,通常用一個32位的16進制字符串表示。另一種常見的摘要算法是SHA1,調用SHA1和調用MD5完全類似:
import hashlib sha1 = hashlib.sha1() sha1.update(‘how to use sha1 in ‘) sha1.update(‘python hashlib?‘) print sha1.hexdigest()
SHA1的結果是160 bit字節,通常用一個40位的16進制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不過越安全的算法越慢,而且摘要長度更長。
3.2 摘要算法應用
任何允許用戶登錄的網站都會存儲用戶登錄的用戶名和口令。如何存儲用戶名和口令呢?方法是存到數據庫表中:
name | password --------+---------- michael | 123456 bob | abc999 alice | alice2008
如果以明文保存用戶口令,如果數據庫泄露,所有用戶的口令就落入黑客的手裏。此外,網站運維人員是可以訪問數據庫的,也就是能獲取到所有用戶的口令。正確的保存口令的方式是不存儲用戶的明文口令,而是存儲用戶口令的摘要,比如MD5:
username | password ---------+--------------------------------- michael | e10adc3949ba59abbe56e057f20f883e bob | 878ef96e86145580c38c87f0410ad153 alice | 99b1c2188db85afee403b1536010c2c9
考慮這麽個情況,很多用戶喜歡用123456,888888,password這些簡單的口令,於是,黑客可以事先計算出這些常用口令的MD5值,得到一個反推表:
‘e10adc3949ba59abbe56e057f20f883e‘: ‘123456‘ ‘21218cca77804d2ba1922c33e0151105‘: ‘888888‘ ‘5f4dcc3b5aa765d61d8327deb882cf99‘: ‘password‘
這樣,無需破解,只需要對比數據庫的MD5,黑客就獲得了使用常用口令的用戶賬號。
對於用戶來講,當然不要使用過於簡單的口令。但是,我們能否在程序設計上對簡單口令加強保護呢?
由於常用口令的MD5值很容易被計算出來,所以,要確保存儲的用戶口令不是那些已經被計算出來的常用口令的MD5,這一方法通過對原始口令加一個復雜字符串來實現,俗稱“加鹽”:
hashlib.md5("salt".encode("utf8"))
經過Salt處理的MD5口令,只要Salt不被黑客知道,即使用戶輸入簡單口令,也很難通過MD5反推明文口令。
但是如果有兩個用戶都使用了相同的簡單口令比如123456,在數據庫中,將存儲兩條相同的MD5值,這說明這兩個用戶的口令是一樣的。有沒有辦法讓使用相同口令的用戶存儲不同的MD5呢?
如果假定用戶無法修改登錄名,就可以通過把登錄名作為Salt的一部分來計算MD5,從而實現相同口令的用戶也存儲不同的MD5。
摘要算法在很多地方都有廣泛的應用。要註意摘要算法不是加密算法,不能用於加密(因為無法通過摘要反推明文),只能用於防篡改,但是它的單向計算特性決定了可以在不存儲明文口令的情況下驗證用戶口令。
四、os模塊
os模塊是與操作系統交互的一個接口
‘‘‘
os.getcwd() 獲取當前工作目錄,即當前python腳本工作的目錄路徑
os.chdir("dirname") 改變當前腳本工作目錄;相當於shell下cd
os.curdir 返回當前目錄: (‘.‘)
os.pardir 獲取當前目錄的父目錄字符串名:(‘..‘)
os.makedirs(‘dirname1/dirname2‘) 可生成多層遞歸目錄
os.removedirs(‘dirname1‘) 若目錄為空,則刪除,並遞歸到上一級目錄,如若也為空,則刪除,依此類推
os.mkdir(‘dirname‘) 生成單級目錄;相當於shell中mkdir dirname
os.rmdir(‘dirname‘) 刪除單級空目錄,若目錄不為空則無法刪除,報錯;相當於shell中rmdir dirname
os.listdir(‘dirname‘) 列出指定目錄下的所有文件和子目錄,包括隱藏文件,並以列表方式打印
os.remove() 刪除一個文件
os.rename("oldname","newname") 重命名文件/目錄
os.stat(‘path/filename‘) 獲取文件/目錄信息
os.sep 輸出操作系統特定的路徑分隔符,win下為"\\",Linux下為"/"
os.linesep 輸出當前平臺使用的行終止符,win下為"\t\n",Linux下為"\n"
os.pathsep 輸出用於分割文件路徑的字符串 win下為;,Linux下為:
os.name 輸出字符串指示當前使用平臺。win->‘nt‘; Linux->‘posix‘
os.system("bash command") 運行shell命令,直接顯示
os.environ 獲取系統環境變量
os.path.abspath(path) 返回path規範化的絕對路徑
os.path.split(path) 將path分割成目錄和文件名二元組返回
os.path.dirname(path) 返回path的目錄。其實就是os.path.split(path)的第一個元素
os.path.basename(path) 返回path最後的文件名。如何path以/或\結尾,那麽就會返回空值。即os.path.split(path)的第二個元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是絕對路徑,返回True
os.path.isfile(path) 如果path是一個存在的文件,返回True。否則返回False
os.path.isdir(path) 如果path是一個存在的目錄,則返回True。否則返回False
os.path.join(path1[, path2[, ...]]) 將多個路徑組合後返回,第一個絕對路徑之前的參數將被忽略
os.path.getatime(path) 返回path所指向的文件或者目錄的最後存取時間
os.path.getmtime(path) 返回path所指向的文件或者目錄的最後修改時間
os.path.getsize(path) 返回path的大小
‘‘‘
五、sys模塊
sys.argv 命令行參數List,第一個元素是程序本身路徑 sys.exit(n) 退出程序,正常退出時exit(0) sys.version 獲取Python解釋程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模塊的搜索路徑,初始化時使用PYTHONPATH環境變量的值 sys.platform 返回操作系統平臺名稱
六、logging模塊
6.1 函數式簡單配置
import logging logging.debug(‘debug message‘) logging.info(‘info message‘) logging.warning(‘warning message‘) logging.error(‘error message‘) logging.critical(‘critical message‘)
默認情況下Python的logging模塊將日誌打印到了標準輸出中,且只顯示了大於等於WARNING級別的日誌,這說明默認的日誌級別設置為WARNING(日誌級別等級CRITICAL > ERROR > WARNING > INFO > DEBUG),默認的日誌格式為日誌級別:Logger名稱:用戶輸出消息。
靈活配置日誌級別,日誌格式,輸出位置:
import logging
logging.basicConfig(level=logging.DEBUG,
format=‘%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s‘,
datefmt=‘%a, %d %b %Y %H:%M:%S‘,
filename=‘/tmp/test.log‘,
filemode=‘w‘)
logging.debug(‘debug message‘)
logging.info(‘info message‘)
logging.warning(‘warning message‘)
logging.error(‘error message‘)
logging.critical(‘critical message‘)
配置參數:
logging.basicConfig()函數中可通過具體參數來更改logging模塊默認行為,可用參數有: filename:用指定的文件名創建FiledHandler,這樣日誌會被存儲在指定的文件中。 filemode:文件打開方式,在指定了filename時使用這個參數,默認值為“a”還可指定為“w”。 format:指定handler使用的日誌顯示格式。 datefmt:指定日期時間格式。 level:設置rootlogger(後邊會講解具體概念)的日誌級別 stream:用指定的stream創建StreamHandler。可以指定輸出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默認為sys.stderr。若同時列出了filename和stream兩個參數,則stream參數會被忽略。 format參數中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 數字形式的日誌級別 %(levelname)s 文本形式的日誌級別 %(pathname)s 調用日誌輸出函數的模塊的完整路徑名,可能沒有 %(filename)s 調用日誌輸出函數的模塊的文件名 %(module)s 調用日誌輸出函數的模塊名 %(funcName)s 調用日誌輸出函數的函數名 %(lineno)d 調用日誌輸出函數的語句所在的代碼行 %(created)f 當前時間,用UNIX標準的表示時間的浮 點數表示 %(relativeCreated)d 輸出日誌信息時的,自Logger創建以 來的毫秒數 %(asctime)s 字符串形式的當前時間。默認格式是 “2003-07-08 16:49:45,896”。逗號後面的是毫秒 %(thread)d 線程ID。可能沒有 %(threadName)s 線程名。可能沒有 %(process)d 進程ID。可能沒有 %(message)s用戶輸出的消息View Code
6.2 logger對象配置
import logging logger = logging.getLogger() # 創建一個handler,用於寫入日誌文件 fh = logging.FileHandler(‘test.log‘) # 再創建一個handler,用於輸出到控制臺 ch = logging.StreamHandler() formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) #logger對象可以添加多個fh和ch對象 logger.addHandler(ch) logger.debug(‘logger debug message‘) logger.info(‘logger info message‘) logger.warning(‘logger warning message‘) logger.error(‘logger error message‘) logger.critical(‘logger critical message‘)
logging庫提供了多個組件:Logger、Handler、Filter、Formatter。Logger對象提供應用程序可直接使用的接口,Handler發送日誌到適當的目的地,Filter提供了過濾日誌信息的方法,Formatter指定日誌顯示格式。另外,可以通過:logger.setLevel(logging.Debug)設置級別。
七、序列化模塊
之前我們學習過用eval內置方法可以將一個字符串轉成python對象,不過,eval方法是有局限性的,對於普通的數據類型,json.loads和eval都能用,但遇到特殊類型的時候,eval就不管用了,所以eval的重點還是通常用來執行一個字符串表達式,並返回表達式的值。
#---轉換類型 d={"name":"yuan"} s=str(d) print(type(s)) d2=eval(s) print(d2[1]) with open("test") as f: for i in f : if type(eval(i.strip()))==dict: print(eval(i.strip())[1]) # 計算 print(eval("12*7+5-3"))View Code
什麽是序列化?
我們把對象(變量)從內存中變成可存儲或傳輸的過程稱之為序列化,在Python中叫pickling,在其他語言中也被稱之為serialization,marshalling,flattening等等,都是一個意思。序列化之後,就可以把序列化後的內容寫入磁盤,或者通過網絡傳輸到別的機器上。反過來,把變量內容從序列化的對象重新讀到內存裏稱之為反序列化,即unpickling。
json
如果我們要在不同的編程語言之間傳遞對象,就必須把對象序列化為標準格式,比如XML,但更好的方法是序列化為JSON,因為JSON表示出來就是一個字符串,可以被所有語言讀取,也可以方便地存儲到磁盤或者通過網絡傳輸。JSON不僅是標準格式,並且比XML更快,而且可以直接在Web頁面中讀取,非常方便。
JSON表示的對象就是標準的JavaScript語言的對象一個子集,JSON和Python內置的數據類型對應如下:
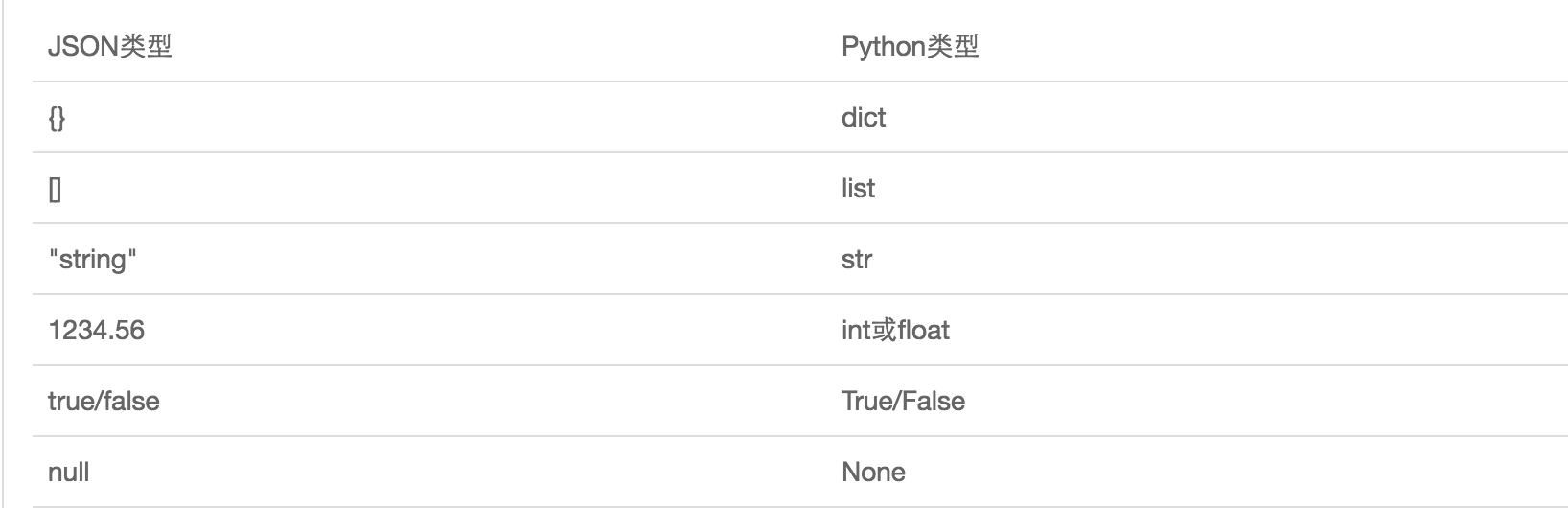
import json i=10 s=‘hello‘ t=(1,4,6) l=[3,5,7] d={‘name‘:"yuan"} json_str1=json.dumps(i) json_str2=json.dumps(s) json_str3=json.dumps(t) json_str4=json.dumps(l) json_str5=json.dumps(d) print(json_str1) #‘10‘ print(json_str2) #‘"hello"‘ print(json_str3) #‘[1, 4, 6]‘ print(json_str4) #‘[3, 5, 7]‘ print(json_str5) #‘{"name": "yuan"}‘View Code
python在文本中的使用:
#----------------------------序列化
import json
dic={‘name‘:‘alvin‘,‘age‘:23,‘sex‘:‘male‘}
print(type(dic))#<class ‘dict‘>
data=json.dumps(dic)
print("type",type(data))#<class ‘str‘>
print("data",data)
f=open(‘序列化對象‘,‘w‘)
f.write(data) #-------------------等價於json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open(‘序列化對象‘)
new_data=json.loads(f.read())# 等價於data=json.load(f)
print(type(new_data))
pickle
##----------------------------序列化
import pickle
dic={‘name‘:‘alvin‘,‘age‘:23,‘sex‘:‘male‘}
print(type(dic))#<class ‘dict‘>
j=pickle.dumps(dic)
print(type(j))#<class ‘bytes‘>
f=open(‘序列化對象_pickle‘,‘wb‘)#註意是w是寫入str,wb是寫入bytes,j是‘bytes‘
f.write(j) #-------------------等價於pickle.dump(dic,f)
f.close()
#-------------------------反序列化
import pickle
f=open(‘序列化對象_pickle‘,‘rb‘)
data=pickle.loads(f.read())# 等價於data=pickle.load(f)
print(data[‘age‘])
day24:常用模塊