
HashMap之擾動函數
阿新 • • 發佈:2017-08-11
修改 代碼 pan div 進制 img 還要 key 做了
JDK8對擾動函數的修改,只進行了一次移位(又移16bit),再和key.hashCode()做異或,如圖
1 //JDK8中的散列值優化函數 2 static final int hash(Object key){ 3 int h; 4 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 5 }
HashMap擴容之前的數組初始大小才16,所以這個散列值是不能直接拿來用的。用之前還要先做對數組的長度取模運算,得到的余數才能用來訪問數組下標。源碼中模運算是在這個indexFor( )函數裏完成的。
bucketIndex = indexFor(int h, table.length);
其中IndexFor代碼
1 static int indexFor(int h, int length){ 2 return h & (length - 1); 3 }
這也正好解釋了為什麽HashMap的數組長度要取2的整次冪。因為這樣(數組長度-1)正好相當於一個“低位掩碼”。“與”操作的結果就是散列值的高位全部歸零,只保留低位值,用來做數組下標訪問。以初始長度16為例,16-1=15。2進制表示是00000000 00000000 00001111。和某散列值做“與”操作如下,結果就是截取了最低的四位值。

但這時候問題就來了,這樣就算我的散列值分布再松散,要是只取最後幾位的話,碰撞也會很嚴重。更要命的是如果散列本身做得不好,分布上成等差數列的漏洞,恰好使最後幾個低位呈現規律性重復,就無比蛋疼。
這時候“擾動函數”的價值就體現出來了,說到這裏大家應該猜出來了。看下面這個圖,
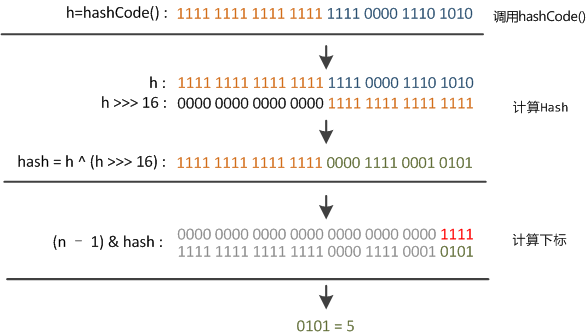
右位移16位,正好是32bit的一半,自己的高半區和低半區做異或,就是為了混合原始哈希碼的高位和低位,以此來加大低位的隨機性。而且混合後的低位摻雜了高位的部分特征,這樣高位的信息也被變相保留下來。
JDK 7做了4次右移,估計是邊際效應的原因,JDK8就只做了一次右移。
HashMap之擾動函數