
vmware搭建hadoop集群完整過程筆記
搭建hadoop集群完整過程筆記
一、虛擬機和操作系統
環境:ubuntu14+hadoop2.6+jdk1.8
虛擬機:vmware12
二、安裝步驟:
先在一臺機器上配置好jdk和hadoop:
1.新建一個hadoop用戶
用命令:adduser hadoop
2.為了讓hadoop用戶有sudo的權限:
用root用戶打開sudors文件添加紅色框裏面的內容:
打開文件:
![]()
添加內容:
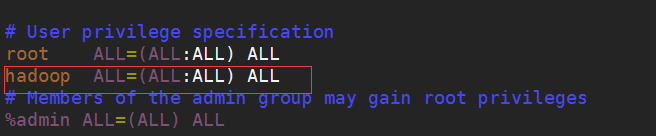
3.配置jdk,我把jdk的壓縮包放在了hadoop的用戶目錄下,然後也解壓在當前目錄下

修改配置文件(配置環境變量):在下面這個位置添加紅色框裏面的內容,其中紅色下劃線上面的內容根據個人jdk的安裝路徑而修改
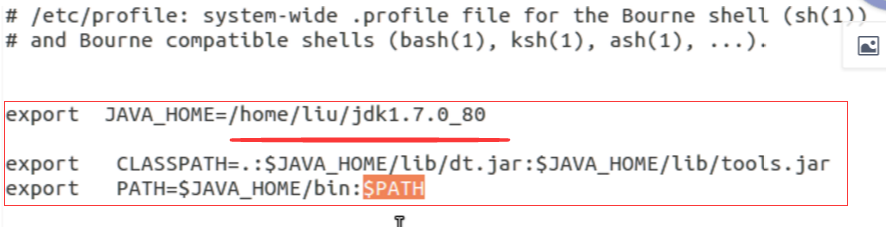
修改配置文件之後要讓配置文件起效,輸入以下命令:
![]()
輸入命令:java -version,如果出現jdk的版本則表示安裝成功,如下:

*****************到這裏,成功配置了jdk,接下來是配置hadoop*********************
4.同樣是把hadoop的壓縮包放到hadoop的用戶主目錄下(/home/hadoop),然後解壓在當前目錄下:

5.修改配置文件(配置hadoop環境變量),在剛剛配置的jdk環境變量上添加內容:
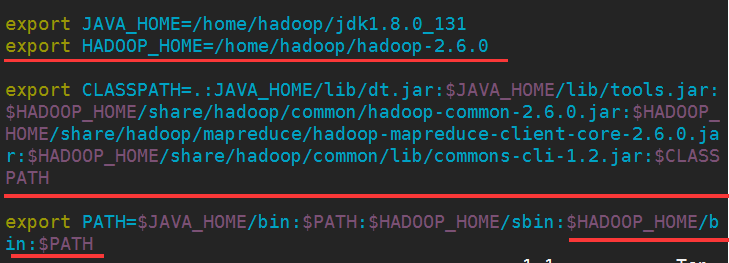
修改後,也要讓配置文件重新起效
![]()
然後進入hadoop的安裝目錄的bin目錄下

輸入以下命令查看hadoop的版本,如果能看到hadoop的版本信息,則證明配置成功:

************************以上以及配置好了單機版本的hadoop環境***********************************
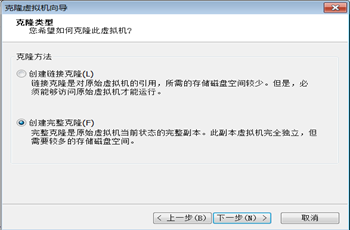
接下來克隆配置好的機器,克隆兩臺:打開vmvare: 虛擬機>管理>克隆。(建議新克隆出來的兩臺機器分別命令為slave1,slave2)
一直點擊 下一步 完成克隆。其中克隆類型選擇創建完整克隆。
1.分別修改各虛擬機的hostname,分別為master,slave1,slave2
![]()
2.修改三臺虛擬機的hosts文件,這樣接下來就不需要記住ip地址了,用主機名代替ip地址就可以了
(ip地址分別為三臺機器的Ip地址,可以分別在三臺機器上通過ifconfig命令查看)
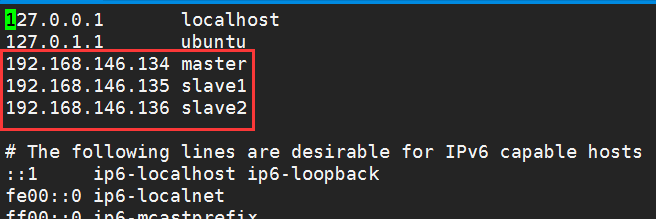
這一步完成後,最好重啟一次系統,以便生效。然後可以用ping master(或slave1、slave2)試下,正常的話,應該能ping通。
註:hostname不要命名為“xxx.01,xxx.02”之類以“.數字”結尾,否則到最後hadoop的NameNode服務將啟動失敗。
3.設置靜態ip
master主機設置靜態ip,在slave上也要參考設置修改成具體的ip
執行命令
sudo gedit /etc/network/interfaces
打開文件修改成已下內容
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet static
address 192.168.140.128 //這裏是本機器的Ip地址
netmask 255.255.255.0 //不用修改
network 192.168.140.0 //網段,根據Ip修改
boardcast 192.168.140.255 //根據Ip修改
gateway 192.168.140.2 //網關,把ip地址後面部門修改成2
4.配置ssh面密碼登錄
在ubuntu上在線安裝
執行命令
sudo apt-get install ssh
**********************************************
配置ssh的實現思路:
在每臺機子上都使用ssh-keygen生成public key,private key
所有機子的public key都拷到一臺機子如master上
在master上生成一個授權key文件authorized_keys
最後把authorized_keys拷給所有集群中的機子,就能保證無密碼登錄
***************************************************
實現步驟:
1 .先在master上,在當前用戶目錄下生成公鑰、私鑰對
執行命令
$cd /home/hadoop
$ssh-keygen -t rsa -P ‘‘
即:以rsa算法,生成公鑰、私鑰對,-P ‘‘表示空密碼。
該命令運行完後,會在個人主目錄下生成.ssh目錄,裏面會有二個文件id_rsa(私鑰) ,id_rsa.pub(公鑰)
2 .導入公鑰
執行命令
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
執行完以後,可以在本機上測試下,用ssh連接自己
執行命令
$ssh master
如果不幸還是提示要輸入密碼,說明還沒起作用,還有一個關鍵的操作
查看權限,如果是屬於其他用戶的,需要修改該文件給其他用戶權限
執行命令
chmod 644 .ssh/authorized_keys
修改文件權限,然後再測試下 ssh master,如果不需要輸入密碼,就連接成功,表示ok,一臺機器已經搞定了。
如出現問題試解決
請先檢查SSH服務是否啟動,如果沒啟動,請啟動!
如果沒有.ssh目錄則創建一個:
執行命令
$cd /home/hadoop
$mkdir .ssh
如無權限,使用命令修改要操作文件夾的owner為當前用戶:
執行命令
sudo chown -R hadoop /home/hadoop
3 .在其它機器上生成公鑰、密鑰,並將公鑰文件復制到master
以hadoop身份登錄其它二臺機器 slave1、slave2,執行 ssh-keygen -t rsa -P ‘‘ 生成公鑰、密鑰
然後用scp命令,把公鑰文件發放給master(即:剛才已經搞定的那臺機器)
執行命令
在slave1上:
scp .ssh/id_rsa.pub [email protected]:/home/hadoop/id_rsa_1.pub
在slave2上:
scp .ssh/id_rsa.pub [email protected]:/home/hadoop/id_rsa_2.pub
這二行執行完後,回到master中,查看下/home/hadoop目錄,應該有二個新文件id_rsa_1.pub、id_rsa_2.pub,
然後在master上,導入這二個公鑰
執行命令
$cat id_rsa_1.pub >> .ssh/authorized_keys
$cat id_rsa_2.pub >> .ssh/authorized_keys
這樣,master這臺機器上,就有所有3臺機器的公鑰了。
4 .將master上的“最全”公鑰,復制到其它機器
繼續保持在master上
執行命令
$scp .ssh/authorized_keys [email protected]:/home/hadoop/.ssh/authorized_keys
$scp .ssh/authorized_keys [email protected]:/home/hadoop/.ssh/authorized_keys
修改其它機器上authorized_keys文件的權限
slave1以及slave2機器上,均執行命令
chmod 600 .ssh/authorized_keys
5. 驗證
在每個虛擬機上,均用命令 ssh+其它機器的hostname 來驗證,如果能正常無密碼連接成功,表示ok
如在slave1
執行命令
ssh slave1
ssh master
ssh slave2
分別執行以上命令要保證所有命令都能無密碼登錄成功。
5.修改hadoop配置文件
先配置hdfs,所以先修改4個配置文件:core-site.xml , hdfs-site.xml , hadoop-env.sh , slaves
到hadoop的該目錄下:
![]()
1).修改core-site.xml
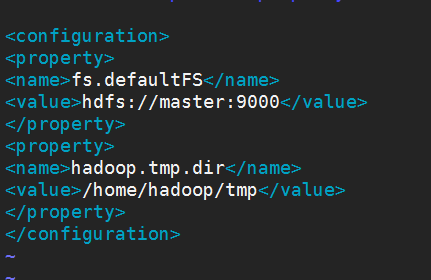
上面配置的路徑/home/hadoop/tmp,如果不存在tmp文件夾,則需要自己新建tmp文件夾
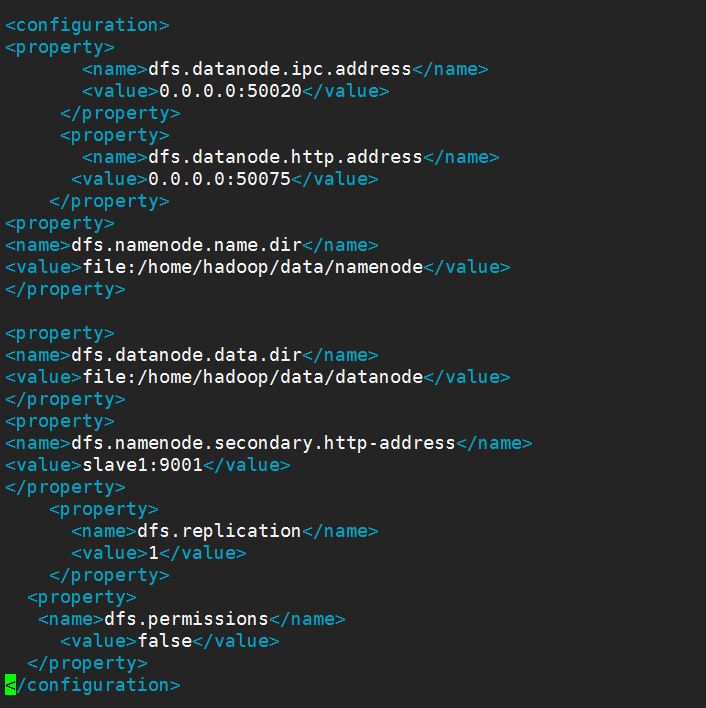
2.修改hdfs-site.xml
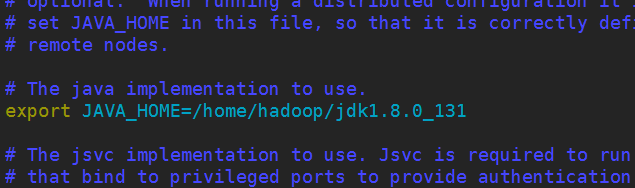
3.修改hadoop-env.sh,(有教程上面還需要配置HADOOP_HOME的環境變量,本人這裏沒有配置但是沒問題,因為在前面已經配置過了)
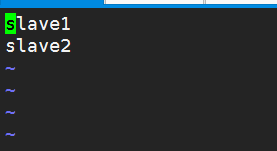
4.修改slaves,刪掉原來的內容,添加其他兩個節點的主機名
5.分發到集群的其它機器
把hadoop-2.6.0文件夾連同修改後的配置文件,通過scp拷貝到其它2臺機器上。
執行命令
$scp -r hadoop-2.6.0/ [email protected]: hadoop-2.6.0
修改這四個文件之後,hdfs服務就配置成功了。通過運行start-dfs.sh啟動hdfs服務,檢查是否配置成功。

啟動完畢之後,輸入jps,如果顯示NameNode和Jps則表示配置成功。
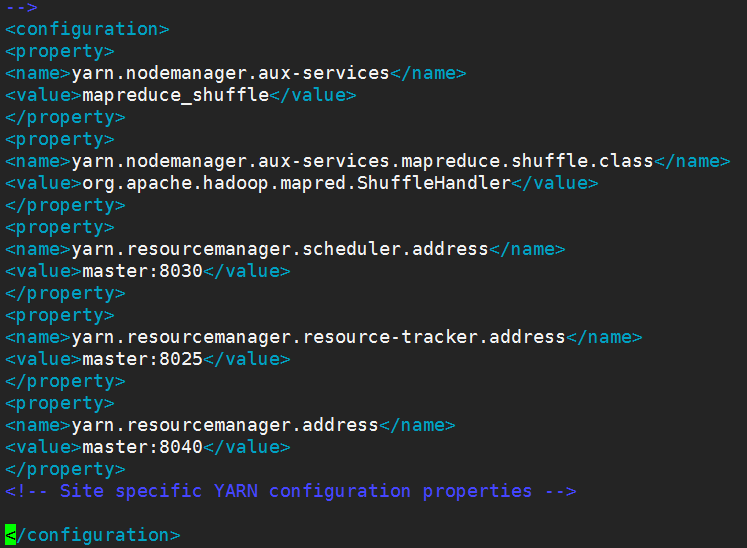
6.接下來配置mapreduce,要修改yarn-site.xml , mapred-site.xml文件
修改yarn-site.xml文件
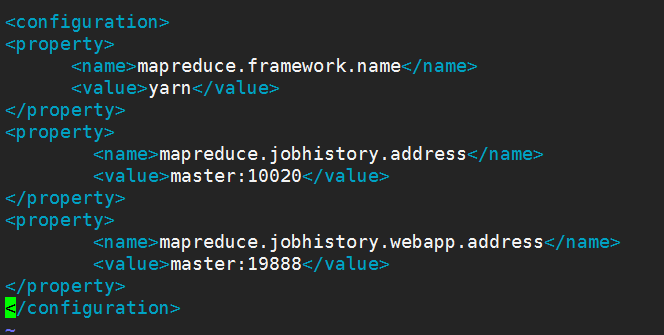
7.修改mapred-site.xml
8.分發到集群的其它機器
把hadoop-2.6.0文件夾連同修改後的配置文件,通過scp拷貝到其它2臺機器上。
執行命令
$scp -r hadoop-2.6.0/ [email protected]: hadoop-2.6.0
運行start-yarn.sh腳本,啟動mapreduce服務。顯示紅色框裏面的三個內容則表示配置成功。

vmware搭建hadoop集群完整過程筆記