
我自己的爬蟲框架(一)
最近都在研究爬蟲的相關東西,感觸良多。先把我自己的單線程的爬蟲架構和大家分享一下,請大家指教。
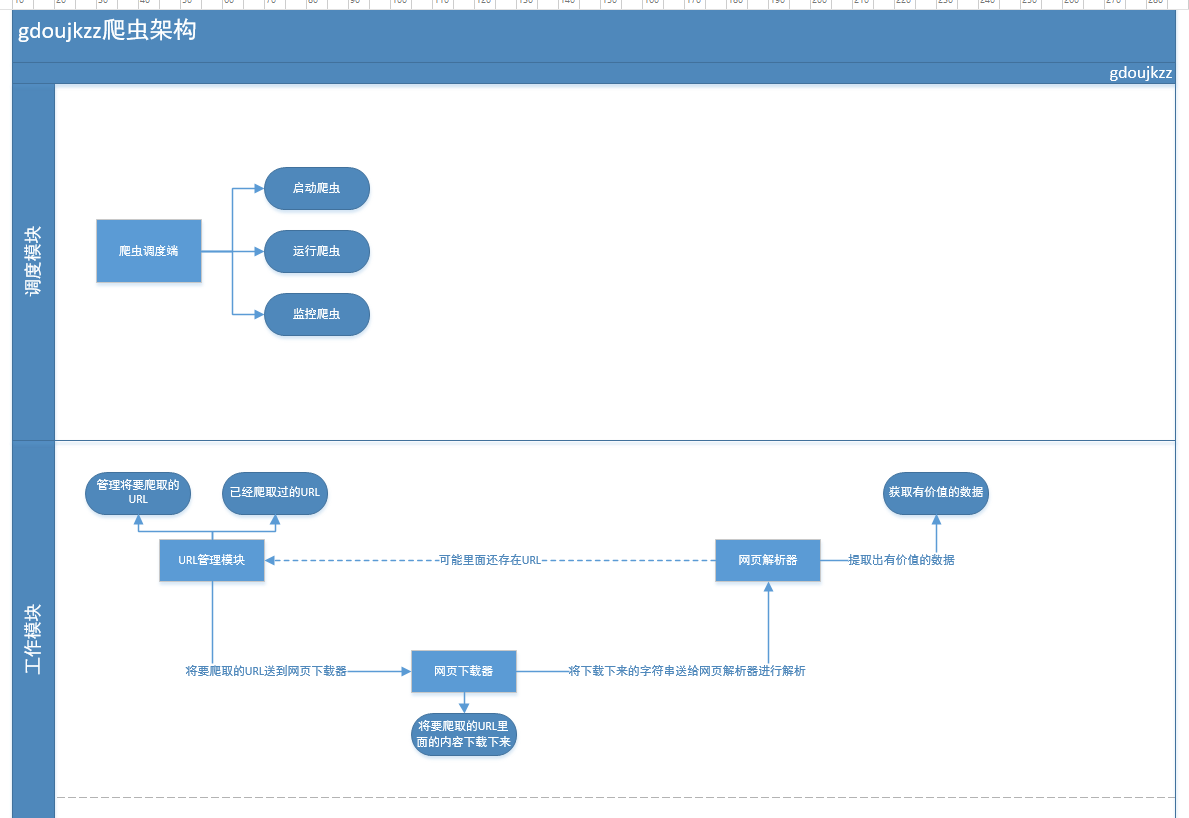
按照上面的這個流程圖,可以寫出一個比較簡單,並且代碼思路也比較清晰的爬蟲程序。
請大家多多指教。
我自己的爬蟲框架(一)
相關推薦
我自己的爬蟲框架(一)
com 程序 logs bsp png 技術 9.png 技術分享 分享 最近都在研究爬蟲的相關東西,感觸良多。先把我自己的單線程的爬蟲架構和大家分享一下,請大家指教。 按照上面的這個流程圖,可以寫出一個比較簡單,並且代碼思路也比較清晰
鑑於網上很多關於 shiro做集群后 session共享的回答 但是都有問題 我自己實踐寫一遍記錄
第一個是繼承 AbstractSessionDAO 這個類 這個類是shiro去儲存session的 import com.newcoin.manager.web.utils.ShiroSessionRedisManager; import org.apache.sh
akka分散式爬蟲框架(一)——設計思路與demo
最近在學習akka,在讀了一下解析actor model的文章以及熟悉了一下官方文件的例子的後 我覺得需要一個專案來幫我進一步熟悉akka與scala程式設計,進過一番思索,我覺得akka可以用來 實現一個分散式爬蟲框架。 設計思路 1. 依賴的庫, http
我自己整理的一份reset.less 以作記錄
一般在做一些專案的時候,都需要一份reset.css和style.css兩個檔案。因此,我自己的reset.css會把一些共用的css全部放在裡面,而不僅僅是reset。 我是用less寫的。為的是方便調整。雖然現在開始學習sass了,但是一時還沒有轉換過來。 程式碼如下:
Asp.net MVC 搭建屬於自己的框架(一)
C4D pagedlist del tran 6.0 ext 才有 應該 frame 網址:https://www.cnblogs.com/sggx/p/4555255.html 為什麽要自己搭框架? 大家夥別急,讓我慢慢地告訴你!大家有沒有這種感覺,從一家跳槽到另一家
爬蟲很簡單麽?直到我抓取了一千億個網頁後我懂!爬蟲真不簡單!
服務 字體 每日 還需要 道理 但是 電子商務 發表 硬件 現在爬蟲技術似乎是很容易的事情,但這種看法是很有迷惑性的。開源的庫/框架、可視化的爬蟲工具以及數據析取工具有很多,從網站抓取數據似乎易如反掌。然而,當你成規模地在網站上抓東西時,事情很快就會變得非常
scrapy爬蟲框架(一):scrapy框架簡介
一、安裝scrapy框架 #開啟命令列輸入如下命令: pip install scrapy 二、建立一個scrapy專案 安裝完成後,python會自動將 scrapy命令新增到環境變數中去,這時我們就可以使用 scrapy命令來建立我們的第一個 scrapy專案了。
Python Scrapy 爬蟲框架例項(一)
之前有介紹 scrapy 的相關知識,但是沒有介紹相關例項,在這裡做個小例,供大家參考學習。 注:後續不強調python 版本,預設即為python3.x。 爬取目標 這裡簡單找一個圖片網站,獲取圖片的先關資訊。 該網站網址: http://www.58pic.com/c/ 建立專案 終端命令列執
python爬蟲Scrapy(一)-我爬了boss資料 MongoDB基本命令操作
一、概述 學習python有一段時間了,最近了解了下Python的入門爬蟲框架Scrapy,參考了文章Python爬蟲框架Scrapy入門。本篇文章屬於初學經驗記錄,比較簡單,適合剛學習爬蟲的小夥伴。 這次我選擇爬取的是boss直聘來資料,畢竟這個網站的
scrapy爬蟲框架簡單入門例項(一)
scrapy是一個用於爬取網站資料,提取結構性資料的python應用框架。爬取的資料一般用於資料分析,資料處理,儲存歷史資料等。scrapy的整體架構大致如下: 主要包括了以下元件: 引擎(Scrapy) 用來處理整個系統的資料流, 觸發事務(框架核心) 排程器(
警醒自己————爆炸的一天,編譯器我求求你了!!!
Visual Studio真的是我服了!!! 這段程式碼我發誓真的沒有問題,但是一執行就報錯 :( :( :( 結果我發現是因為 回去一看 中文輸入法的空格!!! 寫此文章以此告誡我
那些年,我爬過的北科(四)——爬蟲進階之極簡併行爬蟲框架開發
寫在前面 在看過目錄之後,讀者可能會問為什麼這個教程沒有講一個框架,比如說scrapy或者pyspider。在這裡,我認為理解爬蟲的原理更加重要,而不是學習一個框架。爬蟲說到底就是HTTP請求,與語言無關,與框架也無關。 在本節,我們將用26行程式碼開發一個簡單的併發的(甚至分散式的)爬蟲框架。 爬蟲的
記錄我的爬蟲之路1--爬蟲起步的urlib.request Python寫一個不用Scrapy框架的裸奔小幼兒爬爬
這幾天得知保研失敗了….剛好卡在保研名額外一名…雖然最近寫什麼東西都忍不住碎碎唸叨這一句話 =。=,但是好像也覺得能找到喜歡的東西了~比如現在打算認真學的爬蟲了~今天剛把小甲魚入門python的爬蟲部分學完,利用scrapy框架能順利地爬出dmoztools的
自定義實現SpringMvc框架,自定義@Controller、@RequestMapping註解,自己也是一步一步的對程式碼的理解出來的,只是比較簡單的例子
1.自定義的DispatcherServlet,就是SpringMvc執行載入類 /*** * 手寫SpringMvc框架<br> * 思路:<br> * 1.手動建立一個DispatcherServlet 攔截專案的所有請求 SpringMv
自己動手寫PHP-MVC框架(一)
自己動手模仿寫一個php的框架,首先是要明白原理,然後寫的話思路就比較清晰。 當前應用的基本組成是有一堆的資料夾和一個index的檔案組成 |-Conf &n
[原創]一款小巧、靈活的Java多執行緒爬蟲框架(AiPa)
1.作品簡介 AiPa 是一款小巧,靈活,擴充套件性高的多執行緒爬蟲框架。 AiPa 依賴當下最簡單的HTML解析器Jsoup。 AiPa 只需要使用者提供網址集合,即可在多執行緒下自動爬取,並對一些異常進行處理。 2.下載安裝 AiPa是一個小巧的、只有390KB的jar包。 下載該Jar包匯入到你的專案中
五、學習爬蟲框架WebMagic(一)---入門案例
一、WebMagic簡介 參見網上其他介紹。 二、新增依賴 <!-- webmagic 核心包 --> <dependency> <groupId>us.codecraft</groupId> <artif
開發一款開源爬蟲框架系列(二):設計爬蟲架構
既然是構建分散式爬蟲架構,分散式說明爬蟲能在多臺機器同時執行,所以一定是多客戶端的,客戶端主要用於下載網頁,內容會放入佇列,多客戶端就有可能執行在不同的作業系統不同的語言環境,所以我們讓它暫時支援java和scala兩種依賴jvm的語言,不用區分平臺。提到客戶端也一定意味著有服務端的存在,服務端主要用於解
2019年的第一天,我給自己定了一份價值50萬的學習計劃
1. 2018年已經永遠地消逝了,就好像一壺老酒,喝進肚子裡後就再也不可能吐出來了。 今天是2019年的第一天,趕緊花心思制定一份2019年的學習計劃吧!能有多詳細就有多詳細。 有些人覺得,學習計劃有什麼好制定的——今天是一天,明天是一天,後天還是一天,一天一天的就這樣過好了。 但我不這麼覺得。
一套簡單的java爬蟲框架VW-Crawler釋出啦!!!
VW-Crawler 背景 自己一直對爬蟲比較感興趣,大學的畢業論文也是一個爬蟲專案(爬教務處資訊,然後做了個Android版教務管理系統,還獲得了優秀畢業設計的稱號),自那以後遇到自己感興趣的網站就會去抓一下。前段時間工作上需要一些JD資訊,我就從網上