
Kafka數據輔助和Failover
數據輔助與Failover
CAP理論(它具有一致性、可用性、分區容忍性)

CAP理論:分布式系統中,一致性、可用性、分區容忍性最多只可同時滿足兩個。一般分區容忍性都要求有保障,因此很多時候在可用性與一致性之間做權衡。
一致性方案
1.Master-slave
》RDBMS的讀寫分離即為典型的Master-slave方案
》同步復制可保證強一致性但會影響可用性(等master確保將數據復制給全部的slave,slave才返回結果)
》異步復制可提供高可用性但會降低一致性
2.WNR
》主要用於去中心化(P2P)的分布式系統,DynameDB與Cassandra即采用此方案
》
》當W+R>N時,可保證每次讀取的數據至少有一個副本具有最新的更新
》多個寫操作的順序難以保證,可能導致多副本間的寫操作順序不一致,Dynamo通過向量時鐘保證最終一致性
3.Paxos及其變種
》Google的Chubby,Zookeeper的Zab,RAFT等
Kafka是如何權衡CA的呢?
Replica

如:
當一個Patiton副本數超過Broker時,就會報錯
Data Replication要解決的問題
1.如何Propagate(擴散)消息
2.何時Commit
3.如何處理Replica恢復
4.如何處理Replica全部宕機
1.如何Propagate(擴散)消息
以寫入數據為例,Patiton分為leader和follower,follower周期性的向leader pull數據(和consumer相似)。
在讀取數據時,與數據庫讀寫分離不一樣,follower並不參與讀取操作,讀取只和leader有關。
為了提高性能,每個Follower在接收到數據後就立馬向Leader發送ACK,而非等到數據寫入Log中。因此,對於已經commit的消息,Kafka只能保證它被存於多個Replica的內存中,而不能保證它們被持久化到磁盤中,也就不能完全保證異常發生後該條消息一定能被Consumer消費。但考慮到這種場景非常少見,可以認為這種方式在性能和數據持久化上做了一個比較好的平衡。在將來的版本中,Kafka會考慮提供更高的持久性。
2.何時Commit

由上圖可知,leader數據發送給follower既不是同步通信也不是異步通信,而是在一致性和可用性做了動態的平衡
3.如何處理Replica恢復
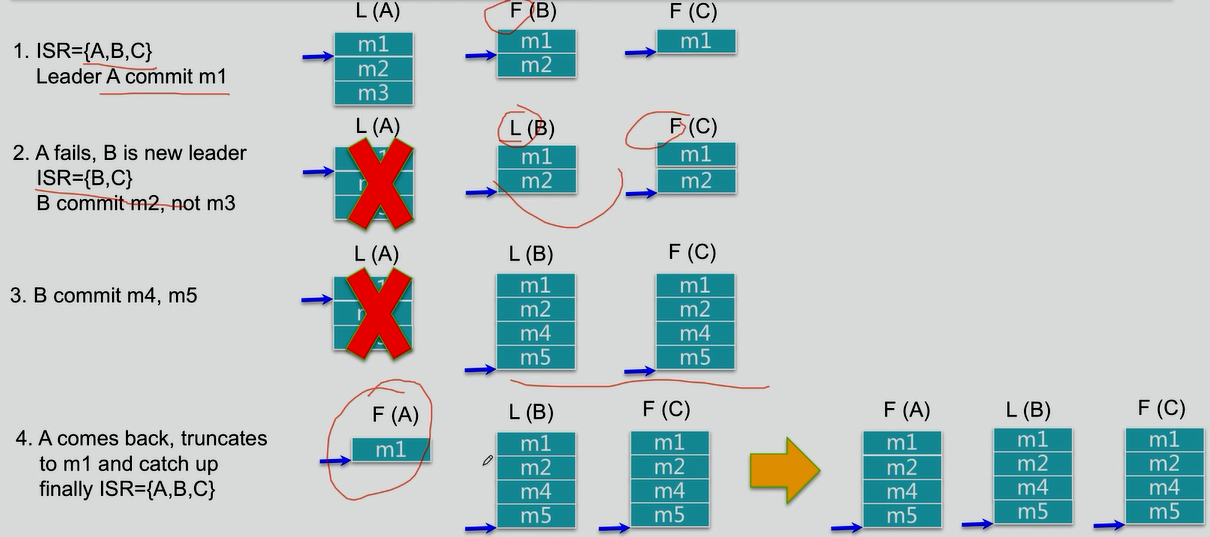
4.如何處理Replica全部宕機
等待ISR中任一Replica恢復,並選它為Leader
》等待時間較長,降低可用性
》或ISR中的所有Replica都無法恢復或者數據丟失,則該Patition將永不可用
選擇第一個恢復的Replica為新的Leader,無論它是否在ISR中
》可能會有數據丟失
》可用性較高
Kafka數據輔助和Failover