
HDFS中高可用性HA的講解
HDFS中高可用性HA的講解
HDFS Using QJM
HA使用的是分布式的日誌管理方式
一:概述
1.背景
如果namenode出現問題,整個HDFS集群將不能使用。
是不是可以有兩個namenode呢
一個為對外服務->active
一個處於待機->standby
他們的之間共享的元數據交 nameservice
2.HDFS HA的幾大中重點
1)保證兩個namenode裏面的內存中存儲的文件的元數據同步
->namenode啟動時,會讀鏡像文件
2)變化的記錄信息同步
3)日誌文件的安全性
->分布式的存儲日誌文件
->2n+1個,使用副本數保證安全性
->使用zookeeper監控
->監控兩個namenode,當一個出現了問題,可以達到自動故障轉移。
->如果出現了問題,不會影響整個集群
->zookeeper對時間同步要求比較高。
4)客戶端如何知道訪問哪一個namenode
->使用proxy代理
->隔離機制
->使用的是sshfence
->兩個namenode之間無密碼登錄
5)namenode是哪一個是active
->zookeeper通過選舉選出zookeeper。
->然後zookeeper開始監控,如果出現文件,自動故障轉移。
二:準備
3.規劃集群
namenode namenode
journalnode journalnode journalnode -->日誌的分布,這是日誌節點,考慮的是日誌的安全性。
datanode datanode datanode
4.關閉所有的進程

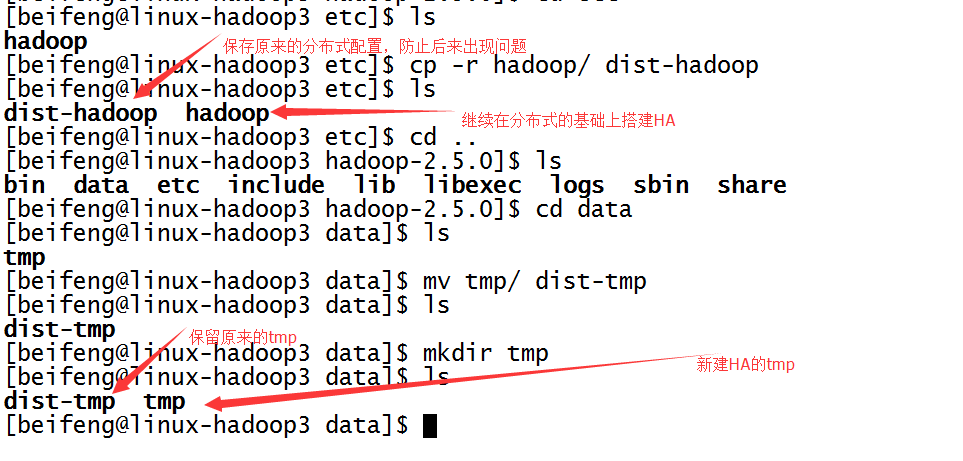
5.保存分布式的源數據,復制一份用來HDFS HA的檢測。
先是第一臺,先將分布式的etc/hadoop,保存為dist-hadoop,保存源數據。
同時,新建tmp。
至於第二臺以及第三臺,在分發之間再進行配置。
三:配置文件
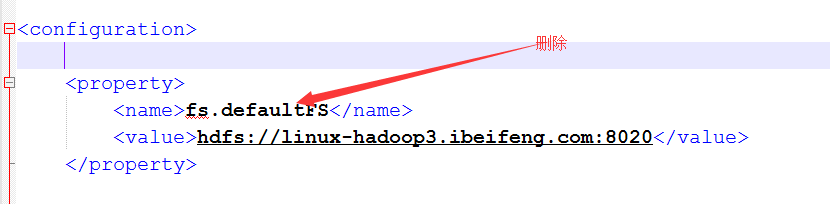
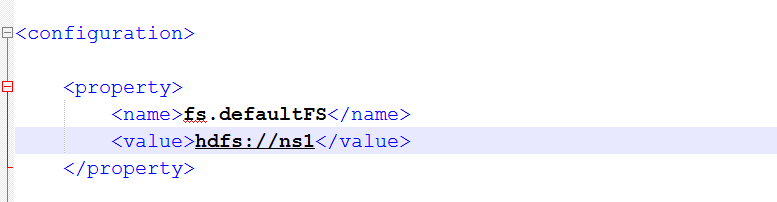
6.將core-site.xml中的文件系統刪除,並添加新的文件系統
以前的是使用是配置一臺,現在配置多態namenode,使用的方式是nameservices的名稱的方式。
添加配置
7.配置hdfs-site.xml

8.繼續配置hdfs-site.xml
dfs.nameservices的配置

dfs.ha.namenodes.[nameservice ID]的配置
包括rpc,http的namenodde地址。

dfs.namenode.shared.edits.dir的配置
這是journalnode的地址

dfs.journalnode.edits.dir 的配置
這是journalnode的日誌存儲的目錄
先新建目錄:


dfs.client.failover.proxy.provider的配置

dfs.ha.fencing.methods的配置
使用的方式為ssh攔截

9.配置完成,在分發之前先進行的是目錄的規劃
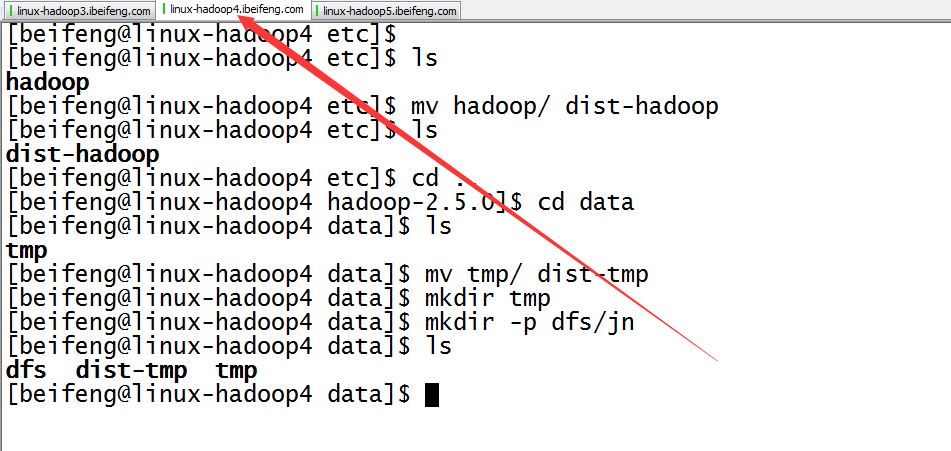
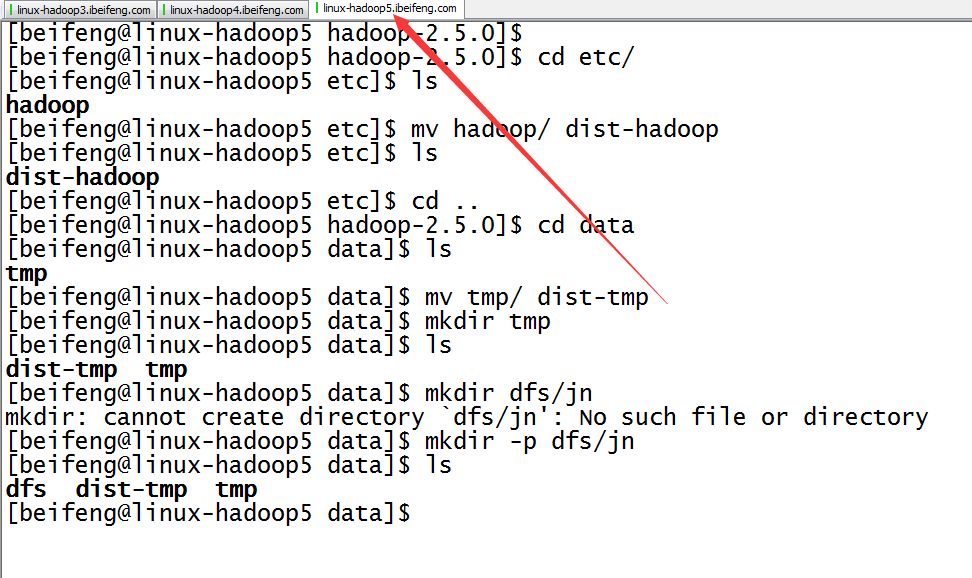
10.分發

四:啟動
11.啟動三臺的日誌節點

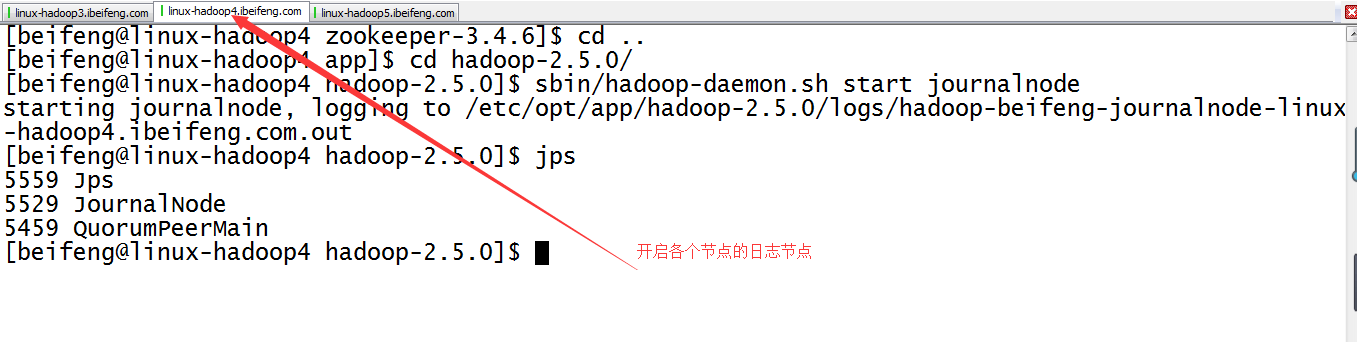
12.格式化第一臺虛擬機
因為是共享數據,所以格式化一臺虛擬機即可。

13.緊接著,同步元數據(在第二臺上寫命令)
最好是bin/hdfs namenode -help查看

14.啟動namenode(兩臺虛擬機)

15.啟動三臺了datanode

16.觀看兩臺的啟動狀態
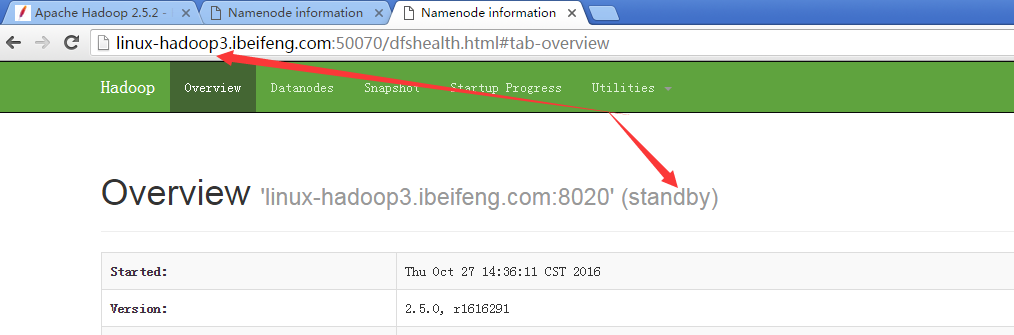
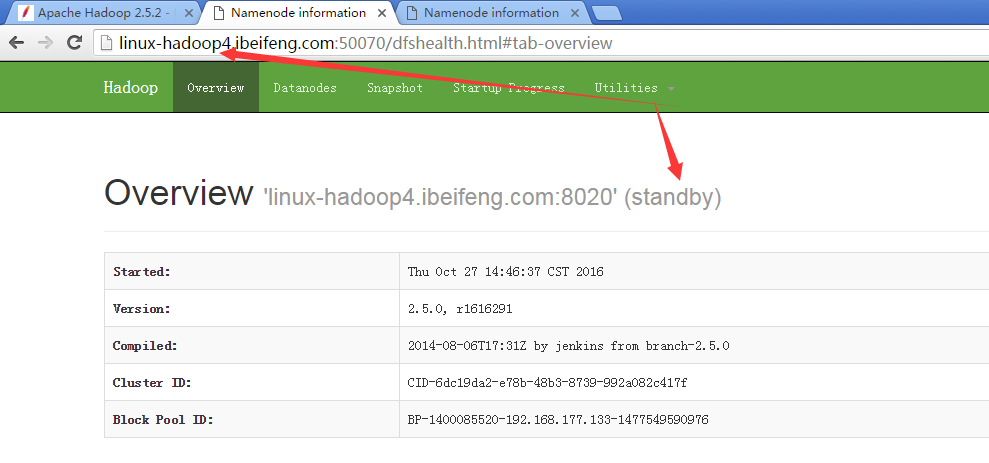
17.強制切換狀態
1)、查找幫助命令,屬於bin/hdfs haadmin
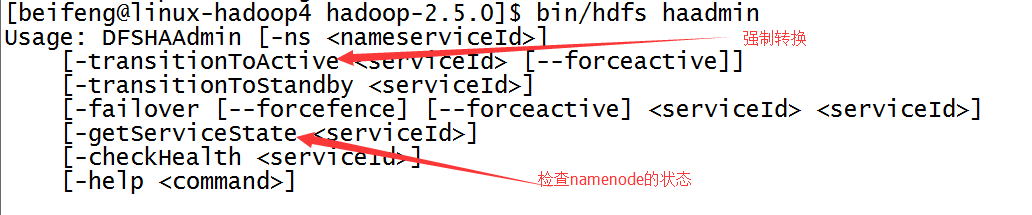
2)、具體命令

18.結果
1)、

2)、
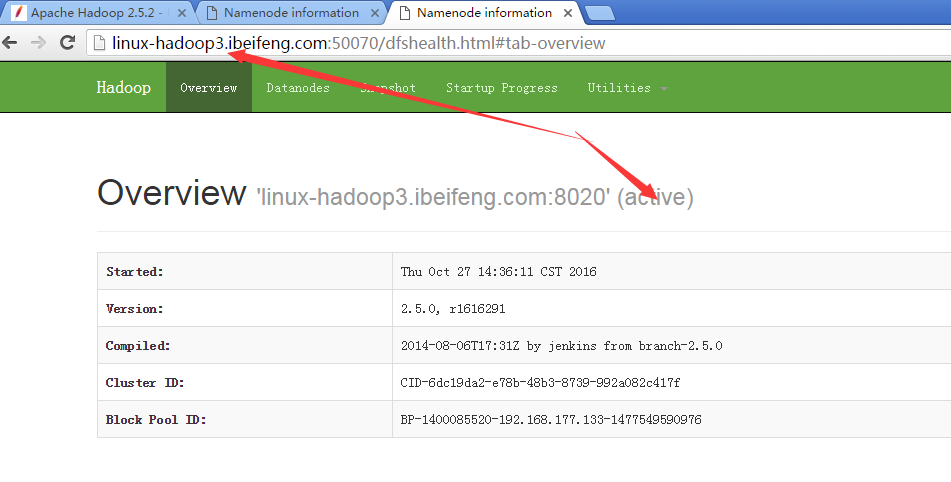
五:再次測試
19.在HDFS上新建目錄並上傳文件

20.殺死第一臺的namenode,進行測試

21.將avtove的狀態切換到第二臺

22.看第一臺是否可以觀看hdfs中的文件
如果可以,說明,HA發揮作用了。
因為這時proxy提供的接口變成nn2.
六:自動故障轉移
前提:關閉所有的進程。
依賴:zookeeper的監控,組件為:ZKFC。
啟動以後都是standby,選舉一個active。
規劃:
namenode namenode
ZKFC ZKFC
journalnode journalnode journalnode
datanode datanode datanode
23.配置core-site.xml
添加zookeeper的服務,包括主機名和端口號。

24.配置hdfs-site.xml
添加自動故障轉移的使能。

25.分發

26.確定關閉所有的進程
這一步是開始的基礎。
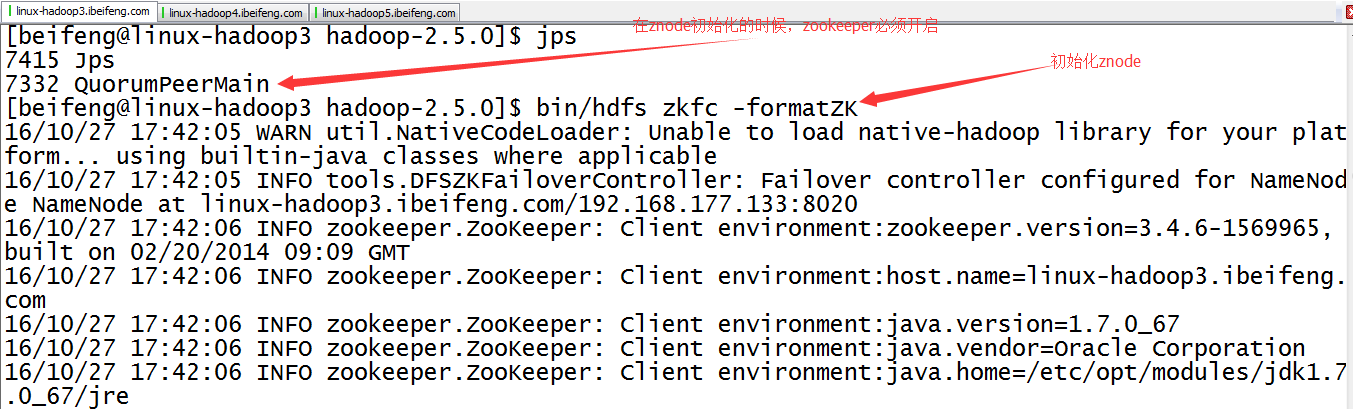
26.開啟三臺的zookeeper服務
先開啟監控。

27.初始化HA在zookeeper中的狀態bin/hdfs zkfc -formatZK
在zookepper上創建znode節點。
27.觀察成功與否
進入zookeeper目錄
命令:bin/zkCli.sh

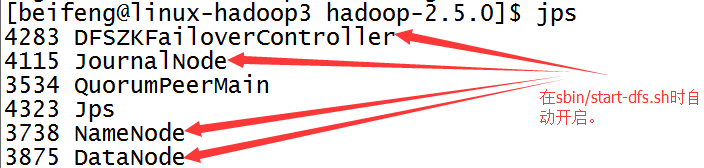
28.啟動sbin/start-dfs.sh
前兩臺虛擬機會出現DFZKFailoverController。
如果沒有開啟DFZKFailoverController,可以手動開啟,命令是sbin/hadoop-daemon.sh start zkfc。
七:簡單檢測
29.展示前兩臺的虛擬機狀態
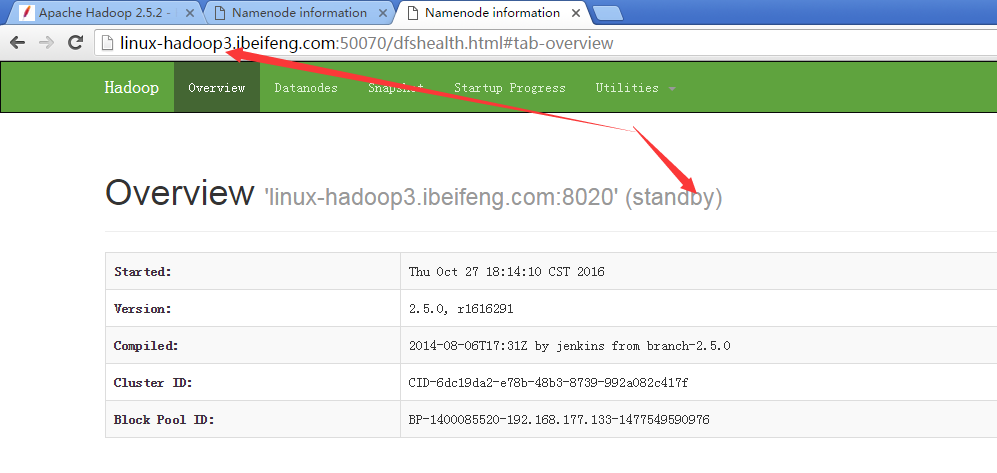
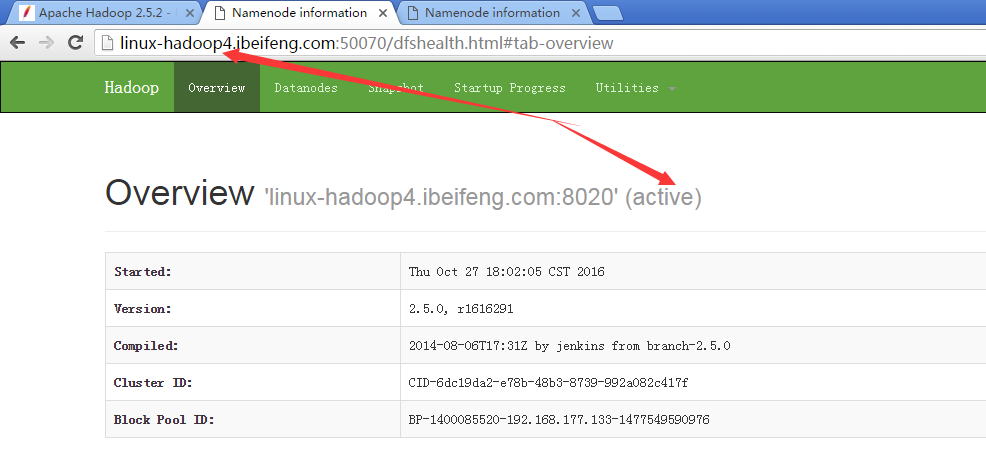
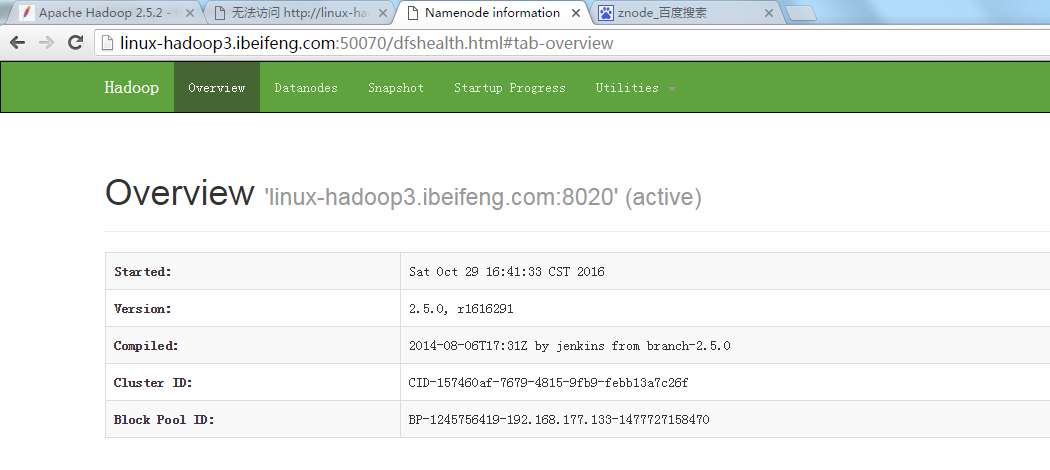
30.殺死第二臺的虛擬機

31.結果
這時,第一臺虛擬機變成active。
HDFS中高可用性HA的講解