
html utf-8 中文亂碼
剛才用ajax從記事本中讀文檔的時候,發現在頁面上顯示是亂碼。
頁面編碼:<meta charset="utf-8">
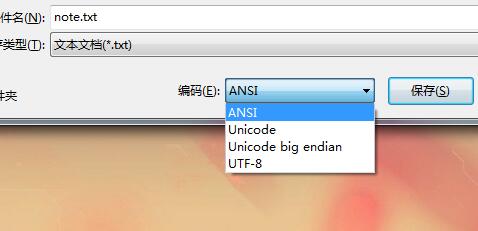
搞半天最後發現是記事本編碼格式的問題,記事本默認編碼格式為ANSI,我們在頁面用utf-8解碼當然成亂碼了...
保存的時候編碼格式選擇 utf-8 即可!
html utf-8 中文亂碼
相關推薦
html utf-8 中文亂碼
解碼 文檔 ima htm 我們 ... 中文 utf image 剛才用ajax從記事本中讀文檔的時候,發現在頁面上顯示是亂碼。 頁面編碼:<meta charset="utf-8"> 搞半天最後發現是記事本編碼格式的問題,記事本默認編碼格式為ANSI,我們在
HTML5 UTF-8 中文亂碼(轉)
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>HTML5的標題</title> </head> <body> <p>HTM
爬取網頁資料出現中文亂碼 UTF-8中文亂碼
在用python爬取網頁資料時,獲取的中文資料出現亂碼情況 第一種情況: 沒有宣告編碼格式,即沒有進行 encoding = 'utf-8' 編碼宣告 例如下圖,在獲取資料中<
thinkPHP讀取資料庫的utf-8中文亂碼解決
本文僅測試過後臺程式為 PHP 和資料庫為 mySql資料庫、Oracle資料庫及SQL Server 2005,不100%確定也能適合其他後臺程式語言和資料庫。 無論資料庫表內的欄位用gb2312、GBK、utf8_general_ci或是utf8_unicode
JS中文轉換(UTF-8),中文亂碼解決辦法,url傳遞中文亂碼解決
轉自:http://jun1986.iteye.com/blog/1056732 js合成url時,如果引數是中文,傳到struts2中會亂碼,解決辦法如下: 1.js檔案中使用encodeURI()方法(必須套兩層)。 login_name = encodeURI(e
解決HTML5 UTF-8 中文亂碼問題
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>HTML5的標題</title> </head> <body> <p>HTM
convmv 解決GBK 遷移到 UTF-8 ,中文 檔名亂碼
yum install convmv 命令: convmv -f GBK -t UTF-8 -r --nosmart --notest <目標目錄> -f from -t to --nosmart 如果已經是utf-8 忽略 -r 包含所有子目錄
linux shell下16進制 “uxxxx” unicode to UTF-8中文
city 使用 orm tac 字符 3.1 方法 查詢接口 var 問題出現背景: 項目中有個通過ip獲取歸屬地城市需求,我是直接通過新浪的ip歸屬查詢接口來獲取的。我使用的是shell腳本調用 RESULT=$(curl -s ‘http://int.dpool
jar 接收utf-8字元亂碼現象
1.今天用php去呼叫jar出現亂碼現象 需要對傳遞的中文字元進行編碼之後再傳遞這裡我用的是urlencode編碼,讓後java再解碼就正常了 這裡貼一下程式碼: <?phpexec("export LANG='en_US.UTF-8';");$cmd_str = urlencod
emWin - 俄語UTF-8編碼亂碼問題(已解決)
原文連結:emWin - 俄語UTF-8編碼亂碼問題(已解決) 目錄 第一步: 第二步: 後續故事: 使用的是STM32微控制器,用的是emWin的庫,編碼工具是U2C(UTF-8 To C檔案)。 最近在搞一個專案,液晶屏要顯示九種語言、種語言、語言、言言言!
python在gbk編碼轉換成utf-8時亂碼問題
例項網站:http://www.ip138.com/ips138.asp?ip=124.24.13.241&action=4 #專案爬蟲,環境python-下載匯入requests、lxml包 #url時是查ip位置的介面 url_1='http://www.ip1
lua 獲取UTF-8中文字串長度-string.byte
轉載:https://www.jianshu.com/p/be7fa619bb44 一. UTF-8編碼規則 1.1 UTF-8簡單描述 1.2 UTF-8的中文字元編碼如何生成 二、lua 獲取UTF-8字串長度(含中文) 2.1 lua判斷字元是不是中文 2.2 如何取得位元組ASCII碼
java html轉pdf 中文亂碼
網上關於 html生產pdf的java程式碼許多,我就不說了。主要是記錄一下亂碼問題的關鍵 1、html檔案必須是utf-8編碼格式的檔案。 2、程式碼中的獲取方式也是utf-8的格式。 3、其他的按照別人的教程編寫
python sublime3 [Decode error - output not utf-8] 中文顯示問題
encoding 分享 解決 今天 python 你好 如果 開頭 inf 一般來說,這個是編碼問題 祭出大殺器,就能解決問題 # coding: utf-8 import sys reload(sys) sys.setdefaultencoding("utf-8") p
lua匹配UTF-8中文漢字
lua5.3雖然支援utf-8,但是自帶的string庫不支援漢字的處理,而且lua的正則實現也比較雞肋,很難匹配中文。所以文章討論UTF-8字符集,中文漢字的表示方法,然後說明lua如何匹配UTF-8中文漢字。初識UTF-8UTF-8是Unicode的一種實現,是一種變長位
python獲取html編碼GB2312中文亂碼的問題
GB18030涵蓋了GB2312和GBK # coding:utf-8 import sys import urllib2 import re from BeautifulSoup import BeautifulSoup reload(sys) sys.setdefa
解決Linux和SecureCRT上UTF-8漢字亂碼問題
首先檢查SecureCRT, 設定 Options->Global options->General->Default session->Edit Default Settings->Terminal-> Appearance->Ch
html句末中文亂碼,且報:ERR_CONTENT_LENGTH_MISMATCH
現在的jeesite框架專案,在建立html檔案後,發現個別中文有亂碼(一般是句子末尾),而且瀏覽器報錯:net::ERR_CONTENT_LENGTH_MISMATCH,經過各種百度,發現是web.xml裡面沒有配置,增加下列配置即可: <jsp-conf
解決Linux中SecureCRT和PUTTY上UTF-8漢字亂碼問題
一,SecureCRT設定Options->Global options->General->Default session->Edit Default Settings->Terminal->Appearance->Characte
HTML頁面為什麽設置了UTF-8仍然中文亂碼
計算機 標簽 href 出現 odin set sin editplus title 如題,其實問題很簡單,在用EditPlus寫html頁面的時候,發現設置為UTF-8的時候仍然出現了亂碼,這是一個很奇怪的問題,而且我完全考慮了瀏覽器的解析問題,將title放在了了met