
讀書筆記--C陷阱與缺陷
要參與C語言項目,於是作者只好重拾C語言(之前都是C++,還是C++方便)。
看到大家都推薦看看 C陷阱與缺陷(C traps and pitfalls),於是好奇的開始了這本書的讀書之旅。
決定將書中重要的知識點和易錯點記錄下來方便自己復習和他人學習~~不多說了,下面開始。
第一章:詞法陷阱
- 在C語言中,符號(程序文字)之間的空白(包括空格符、制表符、換行符)將被忽略。書中舉了一例:
1 if (x > big) big = x; 2 可以寫成: 3 if 4 ( 5 x 6 > 7 big 8 ) 9 big10 = 11 x 12 ;
其實我們編碼的時候已經涉及到了,比如C標準規範就要求多用空格符來對齊;過長的判斷式也會分為兩行書寫等。
這些所謂的空白當然是被忽略了,不然編譯器沒法理解程序意圖了。。。
2. 在詞法分析中,作者指出:如果/是為判斷下一個符號而讀入的第一個字符,而/之後緊挨*,那麽無視上下文,這兩個字符都被當做一個符號/*,表示一段註釋的開始。
由此可能會出現以下問題:
y = x/*p;
語句想用x除以p說指向的值,結果賦給y。但是/*被解釋為註釋,於是語句直接將x賦給y。
其實這樣寫(*p)就可以很好避免。y = x/(*p);
這種錯誤是有可能出現的,好在現在的IDE註釋都會變色,應該容易察覺。
3. 字符和字符串:
學C語言都知道單引號表示字符,雙引號表示字符串。
其實單引號引起的單字符實際上代表一個整數,該整數值對應於該字符在編譯器采用的字符集的序列值。
一般采用ASCII字符集,即’a’與97(十進制)含義嚴格一致。
而雙引號引起的字符串,代表的是一個指向無名數組起始字符的指針,該數組被雙引號之間的字符串+一個額外的二進制值為0的字符’\0’(C中常用來表示結束)初始化。
書中舉例:
1 printf(“hello world\n ”); 2 與3 char hello[] = { ‘h’, ’e’, ‘l’, ‘l’, ‘o’, ‘ ’, ‘w’, ‘o’, ‘r’, ‘l’, ‘d’, ‘\n’, 0 }; 4 printf(hello); 是等效的
上面代碼跑了下確實是對的,但其實將hello[]寫成如下形式更有可讀性。
char hello[] = {‘h’, ’e’, ‘l’, ‘l’, ‘o’, ‘ ’, ‘w’, ‘o’, ‘r’, ‘l’, ‘d’, ‘\n’, ‘\0‘};
4. 書中還提到整型數(16/32位)的存儲空間可容納多個字符(8位),那麽有的編譯器允許一個字符串常量中包括
多個字符。如‘yes‘代替“yes”。
按照單字符的整數本質,作者做了個實驗:
1 int t1=‘a‘; 2 printf("%d\n", t1); 3 int t11=‘aa‘; 4 printf("%d\n", t11);
輸出結果:
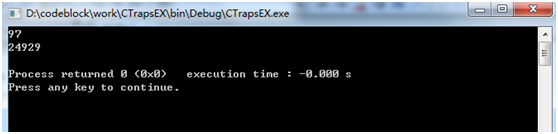
97就是‘a‘的asc碼值好理解,但是‘aa‘的值24929可能就是和編譯器與存儲方式有關系,作者暫時也沒懂,有大神可以評論講解下~~
第一章也就這些註意點了,期待第二章!
讀書筆記--C陷阱與缺陷