
狀態機/叠代器/LINQ/協程
狀態機
有限狀態機(Finite State Machine 或 Finite State Automata)是軟件領域中一種重要的工具。
狀態機允許一個對象在其內部狀態改變時改變它的行為。對象內部狀態決定行為方式,對象狀態改變行為方式改變,這裏強調內部狀態。
Command 模式是將命令請求封裝成一個為對象,將不同的請求對象參數化以達到同樣的調用執行不同的命令;
State 模式是將對象的狀態封裝成一個對象,是在不同的狀態下同樣的調用執行不同的操作。
叠代器是一個典型的狀態機例子,後續會講解。
狀態機的幾種實現方式
- switch
class Object StateMachine{
int state;
void work(data){
switch(state){
case 0:
do state 0;// may change state or not
break;
case 1:
do state 1;// may change state or not
break;
default;
throw;
}
}
} 優點:簡單直觀,比較常用
缺點:如果狀態較多難以維護
- 通過容器
class Object StateMachine{
int state;
static readonly method[] methods={StateMachine:workOnState0,workOnState1};//下標代表狀態,值代表處理函數
workOnState0(data){
//do
}
workOnState1(date){
//do
}
void work(data){
//check state
method = methods[state];
method.call(data);
}
} 優點:代碼簡單了些,只需要維護狀態容器和處理函數
缺點:需要容器,占用內存,狀態必須為整型。
- 還有其他實現方式,最常用的應該是 swich 方式了。
狀態機應用:叠代器
現在多數開發語言都支持叠代器。
可以直接用 foreach 遍歷的對象都是可叠代對象 Iterable,叠代開始時會自動生成叠代器 Iterator。
在 java 中叠代器有 reset() 接口,但大部分都不支持此接口,通用起見,以下討論都假設叠代器不支持此接口。
- Java
for(Item item:Iterable){
//do something
}在編譯時編輯器自動轉換為以下代碼。
Iterator iter = Iterable.Iterator();
while(iter.hasNext()){
Item item=iter.next();
//do something.
}- C#
在 C# 中可叠代對象為 IEnumerable 叠代器為 IEnumerator(比 Java 多實現了 IDisposable 等同於 Java 的 Closeable 或 AutoCloseable)
foreach(Item item in IEnumerator){
//do something
}在編譯時編輯器自動轉換為以下代碼。
using(IEnumerator enumerator = IEnumerable.GetEnumerator())
{
while(enumerator.MoveNext()){
Item item=iter.Current;
//do something.
}
}//釋放資源 using 等同於 java 的 try use resource。- python
python 的叠代器實現方式比較特別。 只有一個 next() 沒有判斷是否結束的函數。當結束時拋出 StopIteration 異常。
for i in iterable:
//do something.等同於
iterator = iter(iterable)
try:
item = iterator.next()
# do something.
except StopIteration:
pass通過以上幾個叠代器的例子我們可以推斷出:
-
可叠代對象之所以能被 foreach 遍歷,都是叠代器的功勞。 foreach 叠代一個元素就是狀態機往前步進一次,如此循環,直到符合停止條件。
-
可叠代對象可以獲取叠代器,每次遍歷需要 new 一個叠代器。
-
叠代器可以執行叠代,每個實例只能被單向遍歷一遍,不能重復使用。
Java 和 .net 的叠代器在實現方式上有所不同。
Java 的 叠代移動在 next() 函數中,.net 的 在 MoveNext() 中。 比較兩種方式,Java 的需要在 hasNext() 和 next() 分別處理邏輯。而 .net 的 只要在 MoveNext() 處理兩種邏輯,而 Current 屬性只是返回已經取到的元素。對於叠代操作而言 這種在一個函數中取出元素又返回是否存在的方法能減少很多代碼量。對於實現 linq 而言 hasNext() next() 的方式就回略顯復雜。
兩種方式能夠互相轉換
hastNext() next() 轉為 moveNext() current() close()
// 叠代器
class IEnumerator {
int state;
Object current;
Iterator iterator;
boolean moveNext() {
switch (this.state) {
case 0:
if (this.iterator.hasNext()) {
this.current = this.iterator.next();
return true;
}
this.close();
return false;
default:
return false;
}
}
Object current(){
return this.current;
}
void close(){
this.current = null;
this.state = -1;
}
}moveNext() current() 轉為 hastNext() next()
// 叠代器
class Iterator {
boolean checkedNext;
boolean hasNext;
IEnumerator enumerator;
public boolean hasNext() {
if (!this.checkedNext) {
this.hasNext = this.enumerator.moveNext();
this.checkedNext = true;
}
return this.hasNext;
}
public TSource next() {
if (this.hasNext()) {
this.checkedNext = false;
return this.enumerator.current();
}
throw Errors.noSuchElement();
}
}通過代碼可以看出,.net 的叠代器是個標準的狀態機,而 java 的應該算不上是狀態機了。但這點並不影響我們對叠代器的使用。
為何要用叠代器,叠代器有什麽好處
- 懶加載 例如 給定一些文件名,需要將這些文件批量上傳到服務器,要求上傳過程中能報告進度,並封裝成一個方法。
普通方式
public static int batchUpload(String[] fileNames){
for(String fileName : fileNames){
upload(fileName);
}
return fileNames.length;
}
//調用
void main(){
String[] fileNames = {"a.txt","b.txt"};
int count = batchUpload(fileNames);
System.out.println("uploaded "+ count + "files.");
}
-- out
uploaded 2 files.叠代器
public class Uploader implements IEnumerator<Integer> {
private String[] fileNames;
private int index;
public Uploader(String[] fileNames){
this.fileNames = fileNames;
}
@Override
public boolean moveNext(){
switch (this.state){
case 0:
this.index = -1;
this.state = 1;
case 1:
this.index++;
if(this.index >= this.fileNames.length){
this.close();
return false;
}
upload(this.fileNames[this.index]);
this.current = this.index + 1;
return true;
default:
return false;
}
}
}
//調用
void main(){
String[] fileNames = {"a.txt","b.txt"};
Uploader uploader = new Uploader(fileNames);
for(int i : uploader){
System.out.println("uploaded "+ count + "files.");
}
}
-- out
uploaded 1 files.
uploaded 2 files.結論: 對比發現,普通的方式只有全部執行後才返回。而叠代器,每叠代一次就返回一個元素,這種特性叫延遲執行(只有在遍歷的時候才執行)。 以後的所有擴展將充分根據此特性展開。
叠代器應用:linq
項目地址:https://github.com/timandy/linq
簡介
-
LINQ,語言集成查詢(Language Integrated Query)最早由微軟提出並在 .net 平臺實現。
-
它允許編寫程序代碼以查詢數據庫相同的方式操作內存數據。
-
操作內存數據的只能算是 Linq to Objects。同時微軟提出了 Linq to Anything 的概念。只要編寫響應的驅動可以用 Linq 查詢任何類型的數據。例如:Linq to Xml 可以用 Linq 查詢 Xml 文檔。Linq to Sql 可以查詢 SqlServer 數據庫。開源庫中也有人開發了響應的其他數據庫的驅動。以及現在的 EntityFramework 都是 Linq to Anything 的實現。
-
此處我們只討論簡單的 Linq to Objects 中的同步實現,這已經足夠大大提高我們操作集合的效率。
另外完整的 Linq 應包含更多的內容。比如:
- 表達式樹(數據庫查詢就是應用的表達式樹將 linq 翻譯為 sql)。
- 並行 Linq。
- 匿名類型。
- 等等
時代在發展科技在進步,於是 Oracle 終於在 Java8 中引入了 Lambda 和 stream api。
其實 stream api 就是 linq,其實現了同步和並行 linq。
雖然 stream 很優秀,但還是有一些不足。
- stream api 沒有基於 iterable 實現,而是另起爐竈基於 Stream 接口。
- 最大的缺陷就是不能 foreach 遍歷,而通過forEach 函數 又不能隨時終止遍歷。而先轉換為 List 再 foreach 仍然需要遍歷一遍才能轉換為 List。
- 並且有些 api 並沒有實現,例如 join,union,intersect等。
- 而有的又設計的比較難用,例如 排序不提供默認比較器,toList 需要傳入 Collector 等。
發現了痛點就要去解決。
我們的目標
- 由於無法修改 iterable 源代碼,並且有些常規的序列(數組,集合,列表,可叠代對象 我們統稱為序列)並且有些序列也沒有實現 iterable。所以我們需要一類函數,將序列轉換為擁有 linq api 的叠代對象(IEnumerable)。
- 對 IEnumerable 擴展實現 linq api。
實現方法
擴展叠代器
public interface IEnumerator<T> extends Iterator<T>, AutoCloseable {
boolean moveNext();//更容易一次處理是否有下一個和獲取下一個元素的邏輯
T current();//從字段取下一個元素,可重復調用
boolean hasNext();
T next();
void reset();//不支持該方法
void close();//釋放資源方法
}擴展可叠代對象
public interface IEnumerable<TSource> extends Iterable<TSource> {
IEnumerator<TSource> enumerator();
default Iterator<TSource> iterator() {
return this.enumerator();
}
}實現 IEnumerable 接口
//可叠代對象
public final class IterableEnumerable<TElement> implements IEnumerable<TElement> {
private final Iterable<TElement> source;
public IterableEnumerable(Iterable<TElement> source) {
this.source = source;
}
@Override
public IEnumerator<TElement> enumerator() {
return new IterableEnumerator<>(this.source);
}
}
//配套的叠代器
public abstract class IterableEnumerator<TSource> implements IEnumerator<TSource> {
protected int state;
protected TSource current;
private boolean checkedNext;
private boolean hasNext;
//
private final Iterable<TSource> source;
private Iterator<TSource> iterator;
public IterableEnumerator(Iterable<TSource> source) {
this.source = source;
}
@Override
public boolean moveNext() {
switch (this.state) {
case 0:
this.iterator = this.source.iterator();
this.state = 1;
case 1:
if (this.iterator.hasNext()) {
this.current = this.iterator.next();
return true;
}
this.close();
return false;
default:
return false;
}
}
@Override
public void close() {
this.iterator = null;
super.close();
}
@Override
public boolean hasNext() {
return this.iterator.hasNext();
}
@Override
public TSource next() {
return this.iterator.next();
}
<[email protected]>
<!--public boolean hasNext() {-->
<!-- if (!this.checkedNext) {-->
<!-- this.hasNext = this.moveNext();-->
<!-- this.checkedNext = true;-->
<!-- }-->
<!-- return this.hasNext;-->
<!--}-->
<[email protected]>
<!--public TSource next() {-->
<!-- if (this.hasNext()) {-->
<!-- this.checkedNext = false;-->
<!-- return this.current();-->
<!-- }-->
<!-- throw Errors.noSuchElement();-->
<!--}-->
@Override
public void reset() {
throw Errors.notSupported();
}
@Override
public void close() {
this.current = null;
this.state = -1;
}
}實現序列轉 IEnumerable 方法
public interface IEnumerable<TSource> extends Iterable<TSource> {
IEnumerator<TSource> enumerator();
default Iterator<TSource> iterator() {
return this.enumerator();
}
public static <TSource> IEnumerable<TSource> asEnumerable(Iterable<TSource> source) {
if (source == null) throw Errors.argumentNull("source");
return new IterableEnumerable<>(source);
}
}擴展 IEnumerable 添加一個默認方法
default IEnumerable<TSource> where(Func1<TSource, Boolean> predicate) {
if (source == null) throw Errors.argumentNull("source");
if (predicate == null) throw Errors.argumentNull("predicate");
return new WhereEnumerable<>(source, predicate);
}
//Func 1 是一個 函數式接口
@FunctionalInterface
public interface Func1<T, TResult> {
TResult apply(T arg);
}實現 WhereEnumerable
class WhereEnumerable<TSource> implements IEnumerable<TSource> {
private final IEnumerable<TSource> source;
private final Func1<TSource, Boolean> predicate;
private IEnumerator<TSource> enumerator;
public WhereEnumerableIterator(IEnumerable<TSource> source, Func1<TSource, Boolean> predicate) {
this.source = source;
this.predicate = predicate;
}
public IEnumerator<TSource> enumerator(){
return new WhereEnumerator(this.source, this.predicate);
}
...
}實現 WhereEnumerator
class WhereEnumerator<TSource> implements IEnumerator<TSource> {
private final IEnumerable<TSource> source;
private final Func1<TSource, Boolean> predicate;
private IEnumerator<TSource> enumerator;
private int state;
private TSource current;
public WhereEnumerator(IEnumerable<TSource> source, Func1<TSource, Boolean> predicate) {
this.source = source;
this.predicate = predicate;
}
@Override
public boolean moveNext() {
switch (this.state) {
case 0:
this.enumerator = this.source.enumerator();
this.state = 1;
case 1:
while (this.enumerator.moveNext()) {
TSource item = this.enumerator.current();
if (this.predicate.apply(item)) {
this.current = item;
return true;
}
}
this.close();
return false;
default:
return false;
}
}
@Override
public void close() {
this.state=-1;
this.current=null;
if(this.enumerator!=null){
this.enumerator.close();
this.enumerator=null;
}
}
...
}調用
@Test
void call(){
List<String> stringList = Arrays.asList("a", "bc", "def");
IEnumerable<String> enumerable = IEnumerable.asEnumerable(stringList).where(str->str.length() > 1);
enumerable.forEach(System.out::println);
}
----
bc
def懶加載,延遲加載或叫延遲執行特性,得益於狀態機
註意上述例子中
IEnumerable<String> enumerable = IEnumerable.asEnumerable(stringList).where(str->str.length() > 1);asEnumerable() 方法返回了一個 new IterableEnumerable(), where() 方法返回了一個 new WhereEnumerable(); 其中並沒有執行循環.此時仍然可以對 enumerable 進行其他操作,仍然不會執行循環(有些特殊命令除外);
當執行 foreach 循環或執行 forEach() 方法時,Iterable 會創建 Iterator 導致 WhereEnumerable 創建 WhereEnumerator。 叠代第一個元素時會導致 IterableEnumerable 創建 IterableEnumerator,每叠代一個元素,會引起叠代器鏈式反應,執行叠代,此時才是真正的執行。
優點(為什麽使用懶加載):
- 執行串行 api 時,無需每調用一次 api 執行一遍循環,可以大大提高性能。
- foreach 時,可在一定的條件下終止循環。如果不使用延遲執行,則會浪費很多 cpu 時間。而該特性是 stream api 不具有的。
缺點(可以避免)
- 如果要對篩選結果進行多次隨機訪問 或 遍歷多次等操作,註意是多次,不要直接在 IEnumerable 上 重復執行。因為懶加載特性,每次執行都會導致所有的篩選操作重新執行一遍。
- 解決方式就是將 IEnumerable 強制執行。調用 toArray(),或 toList() 回立即執行叠代將結果存儲在容器中。然後再對容器進行隨機訪問。
- 與原始代碼比較性能會略有損失,但對比提升開發效率和降低編碼錯誤率而言,優點大於缺點。
編譯器代碼 yield。
部分語言支持 yield X 語法糖,可簡化 IEnumerable 創建,註意是語法糖,編譯時最終將會被編譯為狀態機。 例如
static <TSource> IEnumerable<TSource> where(IEnumerable<TSource> source, Func1<TSource, Boolean> predicate){
if (source == null) throw Errors.argumentNull("source");
if (predicate == null) throw Errors.argumentNull("predicate");
for(TSource item : source){
if(predicate.apply(item))
yield return item;
}
}上述方法編譯後,生成的代碼就跟 WhereEnumerable 的邏輯完全一樣。 當然,現階段 java 還不支持 yield 關鍵字。 如果 JCP 委員會不再固執己見的話將來可能會支持,否則將會遙遙無期。 不過 github 上有個 lombok-pg 實現了這個語法糖,但是需要插件與 IDE 結合,效果並不好,而且生成的代碼正確性得不到保證。
好在,我們用最原始的方法實現了 LINQ to Objects 庫,包含了多數常用的集合操作。
地址:https://github.com/timandy/linq
Linq 應用舉例
- 操作符分類
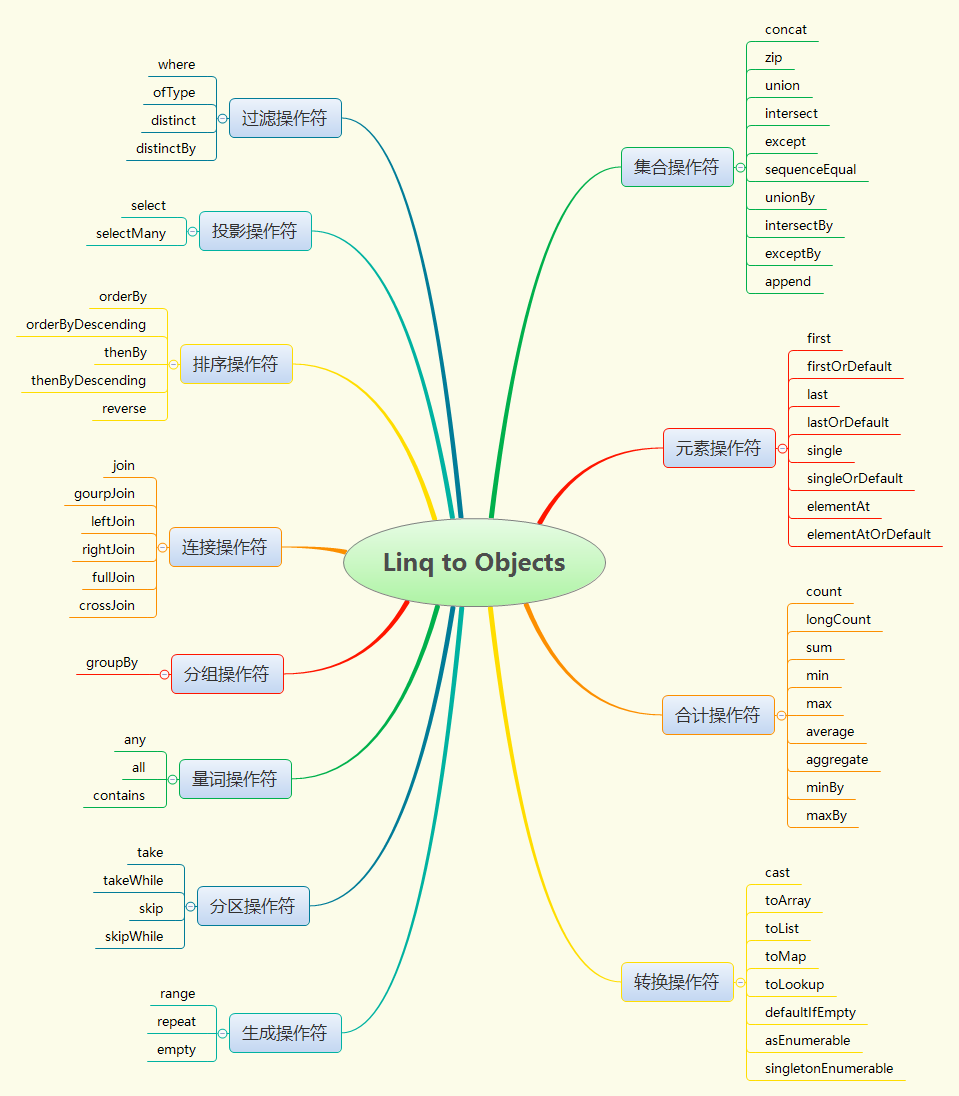
部門
public final class Department {
public final String name;
public final Integer deptno;
public final List<Employee> employees;
public Department(String name, Integer deptno, List<Employee> employees) {
this.name = name;
this.deptno = deptno;
this.employees = employees;
}
public String toString() {
return String.format("Department(name: %s, deptno:%d, employees: %s)", this.name, this.deptno, this.employees);
}
}人員
public final class Employee {
public final int empno;
public final String name;
public final Integer deptno;
public Employee(int empno, String name, Integer deptno) {
this.empno = empno;
this.name = name;
this.deptno = deptno;
}
public String toString() {
return String.format("Employee(name: %s, deptno:%d)", this.name, this.deptno);
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + (this.deptno == null ? 0 : this.deptno.hashCode());
result = prime * result + this.empno;
result = prime * result + ((this.name == null) ? 0 : this.name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (this.getClass() != obj.getClass()) {
return false;
}
Employee other = (Employee) obj;
if (!Objects.equals(this.deptno, other.deptno)) {
return false;
}
if (this.empno != other.empno) {
return false;
}
if (this.name == null) {
if (other.name != null) {
return false;
}
} else if (!this.name.equals(other.name)) {
return false;
}
return true;
}
}數據
private static final Employee[] badEmps = {
new Employee(140, "Cedric", 40),
new Employee(150, "Gates", null)};
private static final Department[] badDepts = {
new Department("Manager", null, Collections.emptyList())};
private static final Employee[] emps = {
new Employee(100, "Fred", 10),
new Employee(110, "Bill", 30),
new Employee(120, "Eric", 10),
new Employee(130, "Janet", 10)};
private static final Department[] depts = {
new Department("Sales", 10, Arrays.asList(emps[0], emps[2], emps[3])),
new Department("HR", 20, Collections.emptyList()),
new Department("Marketing", 30, Collections.singletonList(emps[1]))};過濾操作符
Linq.asEnumerable(emps).where(employee -> employee.deptno < 15);//等同於 stream api 的 filter投影操作符
Linq.asEnumerable(emps).select(emp -> emp.name);//等同於 stream api 的 map排序操作符
Linq.asEnumerable(emps)
.orderBy(emp -> emp.deptno)
.thenBy(emp -> emp.name);//先按部門號,再按姓名排序連接操作符
Linq.asEnumerable(emps)
.join(Linq.asEnumerable(depts),
emp -> emp.deptno,
dept -> dept.deptno,
(emp, dept) -> String.format("%s works in %s", emp.name, dept.name))分組操作符
Linq.asEnumerable(emps).groupBy(emp -> emp.deptno);//按指定鍵分組量詞操作符
Linq.asEnumerable(emps).contains(emps[0]);//序列是否包含指定元素分區操作符
Linq.asEnumerable(emps).skip(1).take(2);//跳過1個,取兩個元素.可用於分頁生成操作符
Linq.range(0, 100);//生成 [0, 99] 共100個數,延遲執行
Linq.repeat(0,100);//生成 100 個 0 的序列,延遲執行
Linq.empty();//生成有 0 個元素的序列,延遲執行轉換操作符
Linq.range(0, 100).toList();//立即執行合計操作符
Linq.range(0, 100).sum();//求和元素操作符
Linq.range(0,100).last();//最後一個集合操作符
Linq.asEnumerable(emps).concat(Linq.asEnumerable(badEmps));組合應用示例
//條件:給定員工和部門,員工和部門通過部門編號關聯.
//要求:按部門分組,組按部門編號排序,組內員工按姓名排序.按順序打印部門編號、名稱和員工編號、姓名
IEnumerable<Employee> allEmps = Linq.asEnumerable(emps).concat(Linq.asEnumerable(badEmps));
IEnumerable<Department> allDepts = Linq.asEnumerable(depts).concat(Linq.asEnumerable(badDepts));
allEmps.join(allDepts, emp -> emp.deptno, dept -> dept.deptno, (emp, dept) -> Tuple.create(emp, dept))//Tuple::create
.groupBy(tup -> tup.getItem2())//按部門分組 Tuple2::getItem2
.orderBy(g -> g.getKey().deptno)//組 按部門編號排序
.forEach(g -> {
System.out.println(String.format("========deptno:%s deptname:%s========", g.getKey().deptno, g.getKey().name));
g.orderBy(tup -> tup.getItem1().name)
.forEach(tup -> System.out.println(String.format("empno:%s empname:%s", tup.getItem1().empno, tup.getItem1().name)));
});
//不打印,生成 List<Map<Department,List<Emplee>>>
List lst = allEmps.join(allDepts, emp -> emp.deptno, dept -> dept.deptno, (emp, dept) -> Tuple.create(emp, dept))//Tuple::create
.groupBy(tup -> tup.getItem2())//按部門分組 Tuple2::getItem2
.orderBy(g -> g.getKey().deptno)//組 按部門編號排序
.select(g -> {
Map<Department, List<Employee>> map = new HashMap<>();
map.put(g.getKey(), g.select(tup -> tup.getItem1()).orderBy(emp -> emp.name).toList());
return map;
})
.toList();- 延伸閱讀-LINQ 標準查詢操作概述
叠代器應用:協程
進程和線程的定義:
一、進程是具有一定獨立功能的程序關於某個數據集合上的一次運行活動,是系統進行資源分配和調度的一個獨立單位。
二、線程是進程的一個實體,是CPU調度和分派的基本單位,他是比進程更小的能獨立運行的基本單位,線程自己基本上不擁有系統資源,只擁有一點在運行中必不可少的資源(如程序計數器,一組寄存器和棧),一個線程可以創建和撤銷另一個線程;
進程和線程的關系:
(1)一個線程只能屬於一個進程,而一個進程可以有多個線程,但至少有一個線程。
(2)資源分配給進程,同一進程的所有線程共享該進程的所有資源。
(3)線程在執行過程中,需要協作同步。不同進程的線程間要利用消息通信的辦法實現同步。
(4)處理機分給線程,即真正在處理機上運行的是線程。
(5)線程是指進程內的一個執行單元,也是進程內的可調度實體。
線程與進程的區別:
(1)調度:線程作為調度和分配的基本單位,進程作為擁有資源的基本單位。
(2)並發性:不僅進程之間可以並發執行,同一個進程的多個線程之間也可以並發執行。
(3)擁有資源:進程是擁有資源的一個獨立單位,線程不擁有系統資源,但可以訪問隸屬於進程的資源。
(4)系統開銷:在創建或撤銷進程的時候,由於系統都要為之分配和回收資源,導致系統的明顯大於創建或撤銷線程時的開銷。但進程有獨立的地址空間,進程崩潰後,在保護模式下不會對其他的進程產生影響,而線程只是一個進程中的不同的執行路徑。線程有自己的堆棧和局部變量,但線程之間沒有單獨的地址空間,一個線程死掉就等於整個進程死掉,所以多進程的程序要比多線程的程序健壯,但是在進程切換時,耗費的資源較大,效率要差些。 線程的劃分尺度小於進程,使得多線程程序的並發性高。
另外,進程在執行過程中擁有獨立的內存單元,而多個線程共享內存,從而極大的提高了程序運行效率。 線程在執行過程中,每個獨立的線程有一個程序運行的入口,順序執行序列和程序的出口。但是線程不能夠獨立執行,必須依存在應用程序中,有應用程序提供多個線程執行控制。 從邏輯角度看,多線程的意義子啊與一個應用程序中,有多個執行部分可以同時執行。但操作系統並沒有將多個線程看做多個獨立的應用,來實現進程的調度和管理以及資源分配。這就是進程和線程的重要區別。
協程
定義
coroutine 協程全稱被稱作協同式多線程(collaborative multithreading)。每個coroutine有一個獨立的運行線路。然而和多線程不同的地方就是,coroutine只有在顯式調用yield函數後才被掛起,同一時間內只有一個協程正在運行。
演進
-
一開始大家想要同一時間執行那麽三五個程序,大家能一塊跑一跑。特別是UI什麽的,別一上計算量比較大的玩意就跟死機一樣。於是就有了並發,從程序員的角度可以看成是多個獨立的邏輯流。內部可以是多cpu並行,也可以是單cpu時間分片,能快速的切換邏輯流,看起來像是大家一塊跑的就行。
-
但是一塊跑就有問題了。我計算到一半,剛把多次方程解到最後一步,你突然插進來,我的中間狀態咋辦,我用來儲存的內存被你覆蓋了咋辦?所以跑在一個cpu裏面的並發都需要處理上下文切換的問題。進程就是這樣抽象出來個一個概念,搭配虛擬內存、進程表之類的東西,用來管理獨立的程序運行、切換。
-
後來一電腦上有了好幾個cpu,好咧,大家都別閑著,一人跑一進程。就是所謂的並行。
-
因為程序的使用涉及大量的計算機資源配置,把這活隨意的交給用戶程序,非常容易讓整個系統分分鐘被搞跪,資源分配也很難做到相對的公平。所以核心的操作需要陷入內核(kernel),切換到操作系統,讓老大幫你來做。
-
有的時候碰著I/O訪問,阻塞了後面所有的計算。空著也是空著,老大就直接把CPU切換到其他進程,讓人家先用著。當然除了I\O阻塞,還有時鐘阻塞等等。一開始大家都這樣弄,後來發現不成,太慢了。為啥呀,一切換進程得反復進入內核,置換掉一大堆狀態。進程數一高,大部分系統資源就被進程切換給吃掉了。後來搞出線程的概念,大致意思就是,這個地方阻塞了,但我還有其他地方的邏輯流可以計算,這些邏輯流是共享一個地址空間的,不用特別麻煩的切換頁表、刷新TLB,只要把寄存器刷新一遍就行,能比切換進程開銷少點。
-
如果連時鐘阻塞、 線程切換這些功能我們都不需要了,自己在進程裏面寫一個邏輯流調度的東西。那麽我們即可以利用到並發優勢,又可以避免反復系統調用,還有進程切換造成的開銷,分分鐘給你上幾千個邏輯流不費力。這就是用戶態線程。
-
從上面可以看到,實現一個用戶態線程有兩個必須要處理的問題:一是碰著阻塞式I\O會導致整個進程被掛起;二是由於缺乏時鐘阻塞,進程需要自己擁有調度線程的能力。如果一種實現使得每個線程需要自己通過調用某個方法,主動交出控制權。那麽我們就稱這種用戶態線程是協作式的,即是協程。
優點
通過應用環境看出協程的優點就是高並發.實際上這個高並發並非實際上的高並發.而是模擬出的高並發.實際意義上除了多核處理器上當前運行的線程為實際意義上的並發.其他的通過線程切換和進程切換實現的並發都是模擬並發.
應用
單核 cpu 的情況下要實現高並發(不包含 io),一般選擇協程. 多核 cpu 的情況下要實現高並發(不包含 io),一般選擇 多線程+協程 或者 多進程+協程.
- io的處理 在協程中如果遇到 i/o 一般將 當前運行的協程掛起,讓io 操作異步執行.程序自動切換到別的協程繼續運行.
實現
多數語言協程的實現都是通過yield 關鍵字掛起當前協程,程序自動切換到其他協程.而 yield 語法糖 基本都被翻譯成了狀態機.
示例
地址:https://github.com/timandy/coroutine
狀態機/叠代器/LINQ/協程