
學習Python基礎--------3
阿新 • • 發佈:2017-08-24
適合 set 一次 是否 lin 所有 author == 3.0
集合操作
集合是一個無序的,不重復的數據組合,它的主要作用如下:
去重,把一個列表變成集合,就自動去重
關系測試,測試兩組數據之前的交集,差集,並集等關系# Author:Zhiyu Su
list_1 = [1,4,5,7,3,6,7,9] list_1 = set(list_1) #轉換為集合 list_2 = set([2,6,0,66,22,8,4,]) print(list_1,list_2) ‘‘‘ #交集 intersection print(list_1.intersection(list_2)) #並集 union print(list_1.union(list_2)) #差集 differenceprint(list_1.difference(list_2)) print(list_2.difference(list_1)) #子集 list_3 = set([1,3,7]) print(list_3.issubset(list_1)) #判斷是否是子集 list3是否是list1的子集 print(list_1.issuperset(list_3)) #判斷是否是父集 list1是否是list3的父集 #對稱差集 print(list_1.symmetric_difference(list_2)) #把倆個集合裏面互相都沒有的取出來 print(‘---------------------‘) list_4 = set([5,6,7,8]) print(list_3.isdisjoint(list_4)) #判斷是否有交集 #交集 print(list_1 & list_2) #並集 print(list_2 | list_1) #差集 print(list_1 -list_2) #in list1 but not in list #對稱差集 print(list_1 ^ list_2) print(‘------------------‘) #增 list_1.add(999) list_1.update([888,777,555])
#使用remove()可以刪除一項
t.remove(‘h‘)
#set的長度
len(s)
print(list_1.pop())#s隨機刪
x in s 測試 x 是否是 s 的成員 x not in s 測試 x 是否不是 s 的成員 s.issubset(t) s <= t 測試是否 s 中的每一個元素都在 t 中 s.issuperset(t) s >= t 測試是否 t 中的每一個元素都在 s 中 s.union(t) s | t 返回一個新的 set 包含 s 和 t 中的每一個元素 s.intersection(t) s & t 返回一個新的 set 包含 s 和 t 中的公共元素 s.difference(t) s - t 返回一個新的 set 包含 s 中有但是 t 中沒有的元素 s.symmetric_difference(t) s ^ t 返回一個新的 set 包含 s 和 t 中不重復的元素 s.copy() 返回 set “s”的一個淺復制
文件操作
- 打開文件,得到文件句柄並賦值給一個變量
- 通過句柄對文件進行操作
- 關閉文件
打開文件
#data = open(‘yesterday‘,encoding=‘utf-8‘).read()
f = open(‘yesterday2‘,‘a‘,encoding=‘utf-8‘) #文件句柄:文件的內存對象 文件名 字符集硬盤上的起始位置 #a = append 追加 f.write(‘when i was young i listen to the radio\n‘)#寫入 data = f.read() #read的讀第二遍無法獲取內容因為第一次讀取之後光標到尾端 print(‘----read,‘,data) f.close() #關閉模式
文件打開模式
py3.0傳輸只能用二進制模式 (文件是以二進制編碼不是二進制)
f = open(‘yesterday2‘,‘r‘,encoding=‘utf-8‘) #文件句柄 讀
f = open(‘yesterday2‘,‘w‘,encoding=‘utf-8‘) #文件句柄 寫
f = open(‘yesterday2‘,‘a‘,encoding=‘utf-8‘) #文件句柄 追加
f = open(‘yesterday2‘,‘r+‘,encoding=‘utf-8‘) #文件句柄 讀寫 讀取一個文件然後在追加 f = open(‘yesterday2‘,‘w+‘,encoding=‘utf-8‘) #文件句柄 寫讀 創建一個文件再寫入 f = open(‘yesterday2‘,‘w+‘,encoding=‘utf-8‘) #文件句柄 追加寫 f = open(‘yesterday2‘,‘wb‘) #文件句柄 二進制讀 f.write(‘hello binary\n‘.encode()) #二進制寫入 f.close()
讀取文件
print(f.readline()) #readline讀取一行 for i in range(5): #讀取五行
print(f.readline())
print(f.readlines()) #文件裏所有內容一列表形式打印出來
for line in f.readlines():#循環打印文件
print(line.strip())#打印時會出現空行 是讀取文件時把每行的換行符打印
#循環不打印文件第10行
for index,line in enumerate(f.readlines()): #文件全部獲取到內存裏 適合小文件讀取
if index== 9:
print(‘----------‘)
continue
print(line.strip())
#高效版及時讀寫 叠代器
count = 0
for line in f:
count += 1
if count == 9:
print(‘----------‘)
continue
print(line)
文件光標操作以及其他操作
f.seek(10) f.truncate(15) #如果不寫值就是清空,寫值就是截斷 print(f.tell()) #文件句柄指針 print(f.readline()) print(f.readline()) print(f.readline()) print(f.tell()) #讀取指針,按字節算 f.seek(0) #移動光標 print(f.readline()) print(f.encoding) #打印文件的編碼 print(f.flush()) #實時更新到硬盤裏
print(f.fileno())#返回文件句柄的編號 當前打開的io接口
有關於flush 實時刷新的進度條
# Author:Zhiyu Su import sys,time for i in range(50): sys.stdout.write(‘/‘) sys.stdout.flush() time.sleep(0.1)
with語句
為了避免打開文件後忘記關閉,可以通過管理上下文with在py2.7以後同時打開多個文件
with open(‘log‘,‘r‘)as f: print(f.readline())
with open(‘log1‘)as obj1,open(‘log2‘)as obj2:
.....
字符編碼和轉碼
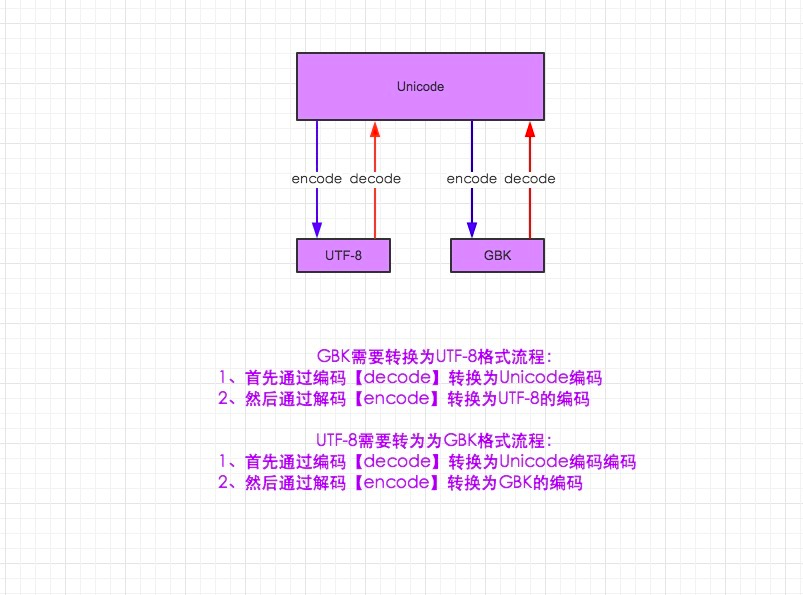
1.在python2默認編碼是ASCII, python3裏默認是unicode
2.unicode 分為 utf-32(占4個字節),utf-16(占兩個字節),utf-8(占1-4個字節), so utf-16就是現在最常用的unicode版本, 不過在文件裏存的還是utf-8,因為utf8省空間udf-8英文連個字節中文三個字節
3.在py3中encode,在轉碼的同時還會把string 變成bytes類型,decode在解碼的同時還會把bytes變回string
函數
函數是什麽
定義: 函數是指將一組語句的集合通過一個名字(函數名)封裝起來,要想執行這個函數,只需調用其函數名即可
特性:
- 減少重復代碼
- 使程序變的可擴展
- 使程序變得易維護
學習Python基礎--------3