
走進MongoDB(二)
本文從以下四個方面對mongodb進行介紹
一、聚合操作(aggregate operation)
二、文本搜索(text search)
三、數據模型 (DATA MODELS)
四、數據庫安全(security)
一、聚合操作
組合多個數據記錄,對分組數據記錄進行多種操作,最終返回一個單一的結果
實現方式:聚合管道、map-reduce、單用途聚合方法
1、聚合管道
聚合管道是基於數據處理管道模型上的。數據記錄經過 多個階段的管道 最終被轉換為聚合結果集。
最基本的過濾管道提供了改變數據集輸出形式的過濾功能。另外、還提供了對documents進行分組、排序的功能。
聚合管道可以使用index對聚合操作進行優化。
例如:
db.col.aggregate([ {$match:{status:‘A‘}} {$group:{_id:‘$title‘,total:{$sum:"$amount"}}} ])
此聚合管道函數、分為兩個階段:
1.match stage - 匹配階段 :找到所有status=A的documents
2.group stage - 分組段:以match階段的結果集為輸入,以title域分組並統計相應的amount
聚合管道優化
1.投影優化
即使用投影來獲取所有fields的一個自己,以減少進入管道的數據量,實現優化
2.管道序列優化
$sort 和 $match優化如下
{ $sort: { age : -1 } },
{ $match: { status: ‘A‘ } }
應修改為:
{ $match: { status: ‘A‘ } },
{ $sort: { age : -1 } }
先過濾、再排序,減少排序階段的數據量
$skip和$limit優化
{ $skip: 10 },
{ $limit: 5 }
修改為:
{ $limit: 15 },
{ $skip: 10 }
減少了進入skip階段的數據量
$project 和$skip或$limit優化
$skip和$limit應該放在$project階段之前
總結:序列優化的原則是,將能減少數據量的stage放在不能減少數據量的stage的前面,將減少數據量多的stage放在減少數據量少的stage。
3.管道合並優化
在可能的情況下,優化階段會將一個管道階段合並到它之前的管道階段。通常情況下,管道合並會發生在 序列重排序優化之後。
$sort 和 $limit
當$sort在$limit之前的時候,優化器可以將$limit合並到$sort階段。$sort階段僅僅會持有$limit指定的前n個ducuments,MongDB只需要在內存中持有n項documents。
註:$sort階段在有100M的內存限制,如果進入此階段的數據容量超過了100M,$sort會產生一個錯誤信息。當然,我們也可以修改相關配置項。
$limit和$limit
多個$limit會自動合並為一個。Limit為個stage中最小的那個值。
$skip和$skip
會合並為$kip指定值的總和
$match和$match
會使用$and操作符合並為一個管道階段
聚合管道限制
1.結果集大小限制
從mongodb2.6開始,aggregate命令會返回一個遊標或者在collection中存儲結果。返回結果中的每一個document(一條數據記錄)都服從 BSON Document Size 設置(目前是16M)。如果有document超過了限制,聚合命令就會出錯。這種限制只作用在最終返回中的結果集,對於管道操作的中間過程,documents可以超過這個限制。[ mongodb>2.6,aggregate默認返回一個遊標(指針)]
2.內存限制
從mongodb2.6開始,管道階段處理的數據集有100M的限制。可以使用allowDiskUse進行內存限制的設置,使聚合管道stage可以把數據寫到臨時文件。
聚合管道與分片集合
1.行為
2.優化
2、map-reduce
Map-Reduce是個將大批量數據壓縮為有用聚合結果集的數據處理範例。
mongodb也提供了map-reduce操作來實現對documents的聚合。
map-reduce大致分為兩個階段
map階段:處理所有文檔、為每個文檔映射出一個或多個對象
reduce階段:對映射操作的輸出結果進行組合
map-reduce 還有一個可選的最終階段、來對結果進行修改。如:指定查詢條件、對結果進排序和限制。
和聚合管道相比,使用定制型的avascript 的map-reduce具有更大的靈活性,但是更加的復雜和低效。
以下是Map-reduce執行過程圖(摘自mongo官網)
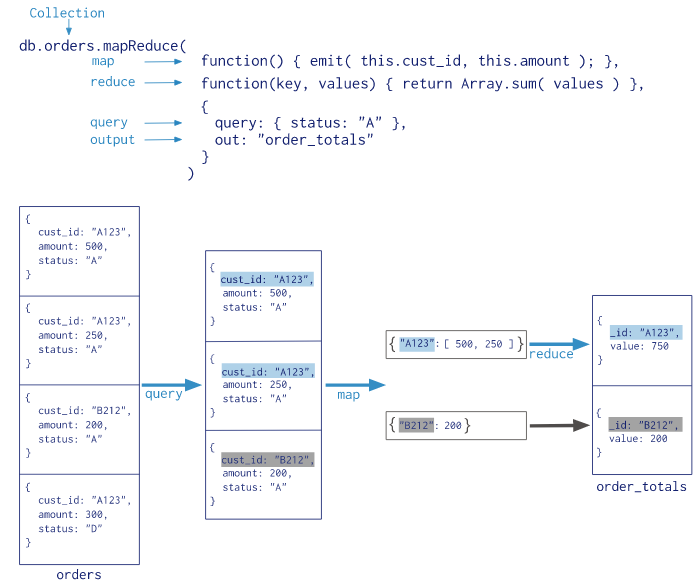
Map-Reduce JavaScript Funcitons
Map-reduce使用自定義javascript函數,將值映射、關聯到鍵上。如果一個鍵對應過個值,reduces操作會將多個鍵值對合並為一個對象。
可以對map、reduce的操作結果,使用自定義函數來執行額外的計算等功能。
Map-Reduce Behavior
Map-reduce操作可以將其操作結果寫入一個collection,也可以返回一個聯機的結果。
如果寫到collection,你可以對之前map-reduce的結果集,執行進一步的map-reduce操作。
如果以聯機的形式返回結果,要求每個document<BSON Documetn Size(16M)。
Map-reduce操作也是支持sharded collction。
Map-reduce分片集合
Map-reduce並發
Map-reduce由多個任務組成,包括、讀取輸入集合、執行map、執行reduce、把集合寫入臨時集合、把結果寫入輸出集合。
在操作執行期間,map-reduce持有一下鎖:
--讀階段,持有讀鎖。每100個documents會生成一個讀鎖。
--寫入臨時集合操作持有一個寫鎖。
--如果輸出集合不存在,那麽輸入集合的操作會持有一個寫鎖。
--如果輸出集合存在,輸出操作(合並、替換、縮減)會持有一個寫鎖。這個寫鎖是全局鎖,會鎖定mongod的所有操作。
增量式Map-reduce
在map-reduce數據集不斷增長的時候,我們可能想執行增量式的map-reduce,而不是每次都執行所有的數據集。
首先,要把map-reduce結果寫入一個單獨的collection
其次,當有更多的數據需要處理的時候,執行subsequent map-reduce任務:
查詢條件僅僅指定新增的documents
Out參數中的aciton指定為:reduce,這樣後來執行的map-reduce結果會和已經存在的collection共同執行reduce函數、並進行結果集的合並。
Troubleshoot the Map Function
Troubleshoot the Reduce Function
3、單用途聚合操作
mongodb還提供了 db.collection.count() db.collection.distinct() 實現對聚合過程的簡單訪問。
二、文本搜索
1.Text indexes
文本索引(t-i)可以包含任何值為String、或者元素為String的數組的域。
一個collection只能擁有一個text index,但是一個t-i可以包含幾個域。如:
db.stores.createIndex( { name: "text", description: "text" } )
2.Text search operateors
使用$text操作符,對擁有t-i的collection執行文本搜索。
$text會將大部分的空格和標點符號作為定界符。如:
db.stores.find( { $text: { $search: "java coffee shop" } } )會搜索包含 java 、coffee、shop的條目。
使用$meta 查詢操作符來獲取text search與每條document的匹配分數:
db.stores.find(
{ $text: { $search: "coffee shop cake" } },
{ score: { $meta: "textScore" } }
).sort( { score: { $meta: "textScore" } } )
3.Text search in the aggeregation pipeline
Mongodb2.6開始,可以在聚合管道的$match階段使用$text查詢操作符進行文本搜索。
使用限制:
1.$match stage必須是管道的第一個階段。
2.Text操作符只能出現一次
3.Text操作符不能出現在$or 、$not 表達式中
4.在$sort階段使用$meta聚合表達式
文本匹配分數:
$text操作符給document指定了一個score。Score代表了document和text search的匹配程度。
$meta操作符只可以出現在包含$text的$match階段之後。
db.articles.createIndex( { subject: "text" } )
計算包含cake的subject的views總量:
db.articles.aggregate(
[
{ $match: { $text: { $search: "cake" } } },
{ $group: { _id: null, views: { $sum: "$views" } } }
]
)
使用score排序:
db.articles.aggregate(
[
{ $match: { $text: { $search: "cake tea" } } },
{ $sort: { score: { $meta: "textScore" } } },
{ $project: { title: 1, _id: 0 } }
]
)
對Text score做匹配和過濾:
db.articles.aggregate(
[
{ $match: { $text: { $search: "cake tea" } } },
{ $project: { title: 1, _id: 0, score: { $meta: "textScore" } } },
{ $match: { score: { $gt: 1.0 } } }
]
)
指定文本搜索語言:
db.articles.aggregate(
[
{ $match: { $text: { $search: "saber -claro", $language: "es" } } },
{ $group: { _id: null, views: { $sum: "$views" } } }
]
)
4.Text search with basis technology rosette linguistics platform
(mongodb企業版提供了額外的文本搜索語言:其中有簡體中文、繁體中文)詳細使用信息參考官網。
5.Text search languages
三、數據模型 DATA MODELS
在MongoDB中,collections不會強制document 的結構。這種靈活性,給了我們可以選擇的數據模型,以適應我們特定的應用程序與性能需求。
1.Data modeling introduction
Document structure
數據模型設計的關鍵是documents的結構和如何表示數據之間的關系。Mongodb中使用引用文檔和嵌入文檔來表示這些關系。
寫操作的原子性
MongDB中,在document級別,寫操作是原子性的。一個單獨的寫操作不會對多個documents或者collection產生原子性的影響。
非規範化的嵌入文檔數據將代表一個實體的相關數據組合成了一個實體,這有助於對實體進行原子性的插入、更新操作。然而,規範化的數據會將一個實體的數據分布在多個collection裏面,需要同時進行多項寫入、更新操作,這樣並不能保證對一個實體的原子性操作。
document growth
向數組增加元素或者新增域的操作都會增加document的大小。
對於MMAPv1存儲引擎來說,document的大小超過了設定的空間,mongodb會在硬盤上重新安置document。
數據的使用和性能
設計數據模型之前,首先要考慮應用程序會如何使用我們的數據庫。如,colleciton主要用於讀取查詢操作,那麽添加索引就可以提高數據訪問性能。
2.Document validation
可以通過validator選項來設置驗證規則.
文檔驗證設置形式如下:
db.runCommand( {
collMod: "contacts",
validator: { $or: [ { phone: { $exists: true } }, { email: { $exists: true } } ] },
validationLevel: "moderate"
} )
Behavior
驗證發生在更新、插入操作期間。當對collection增加驗證的時候,已經存在的documents不會執行驗證檢查,直到有數據被修改。
existing documents
可以通過validationLevel 選項,控制mongodb如何處理documents
默認,validationLevel 是 strict。Mongodb會對所有已經存在的documents,inserts and updates應用驗證規則。
validationLevel = moderate,只會對已經存在的documents中滿足驗證規則的documents進行驗證。不會檢查不符合驗證規則的documents。
不合法documents的接受和拒絕
validationAction選項,決定mongdoDB如何處理違反驗證的documetns。
默認,validationAction=error,MongoDB會阻止所有違反驗證的documents。
validationAction=warn,MongoDB只在日誌中記錄不合法的驗證,不會阻止documents的插入和更新操作。
日誌會記錄下失敗驗證操作的命名空間、colleciton、document,還有執行的時間如:
2015-10-15T11:20:44.260-0400 W STORAGE [conn3] Document would fail validation collection: example.contacts doc: { _id: ObjectId(‘561fc44c067a5d85b96274e4‘), name: "Amanda", status: "Updated" }
Restrictions
不能對admin、local、config數據庫使用validator。
不能對system.* collection使用validator。
繞開document驗證
使用bypassDocumentValidation選項,來繞開document驗證。
對於開啟安全驗證的數據庫,用戶必須要擁有bypassDocumetnValidation權限。內建的角色只有dbAdmin和restore提供了這個權限。
2.數據模型概念Data modeling concepts
模型設計(Data Model Design)
要考慮不同數據模型的優勢與劣勢,以根據事實需要選擇不同的策略。
有效的數據模型能更好的支撐應用的需求。Document結構的設計關鍵是,使用嵌入型(非規範化)、還是引用型documents(規範化)。
嵌入式數據模型

嵌入式數據模型允許程序把相關的一組信息存儲到一條數據庫記錄中。這樣,應用程序可以使用更少次數的查詢、更新語句來完成查詢。
使用情形:
1.實體間存在一對一關系的時候。
2.實體間存在一對多關系的時候。
嵌入型模型,通常具有更好的讀操作性能,並且可以通過一條語句 來請求和獲取相關聯的數據。以原子性的寫入方式來更新、寫入相關聯的數據。
存在問題:
一個document包含過多的域,導致document growth。對於MMAPv1存儲引擎,這會影響寫操作的性能、導致數據分段。
規範化(引用)數據模型
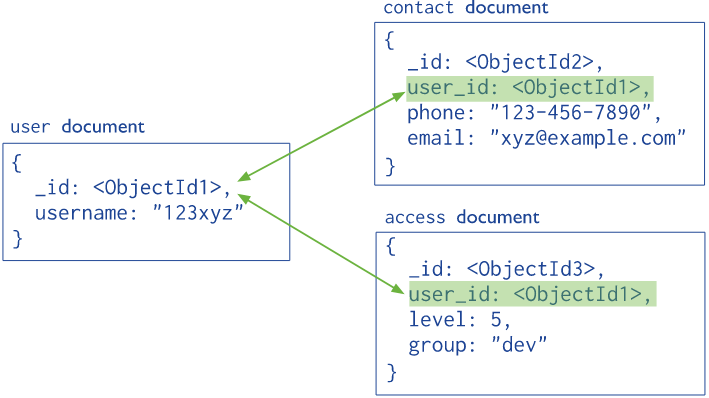
使用引用的方式表示document之間的關系。
使用情況:
--當嵌入式模型導致了大量數據重復,但是,數據重復使得讀取性能無法表現出其應有的優勢。
--表示復雜的多對多關系的時候。
--構造大的分層數據集。
引用模型擁有更多的靈活性。但是,客戶端應用程序必須執行多項操作來實現相關聯數據的同步更新。
2.Operational Factors and Data Models
四、MongoDB安全性
1.MongoDB認證管理
默認情況下,mongodb不使用訪問控制功能。要使用訪問控制需要自行開啟、配置相關更能。
開啟權限控制
方式一,啟動時使用命令選項:
mongod --auth
方式二,在mongod配置文件中加入security.authorization設置:
security:
authorization: enabled
創建賬戶管理員
在admin數據庫中,添加userAdmin/userAdminAnyDatabase角色類型的用戶。
use admin db.createUser( { user: "myUserAdmin", pwd: "abc123", roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )
註:此賬戶只能對賬戶、角色進行管理,沒有其他任何權限。
重啟mongod即開啟了權限認證功能,登錄命令如下:
mongo --port 27017 -u "myUserAdmin" -p "abc123" --authenticationDatabase "admin"
認證
use admin
db.auth("myUserAdmin", "abc123" )
返回1:認證成功,否則認證失敗
擁有用戶管理員賬戶之後,即可添加其他我們需要的賬戶。例如:為test數據庫添加一個具有讀寫權限的用戶:
use test db.createUser( { user: "myTester", pwd: "xyz123", roles: [ { role: "readWrite", db: "test" }] } )
使用myTester賬戶登錄:
mongo --port 27017 -u "myTester" -p "xyz123" --authenticationDatabase "test"
MongoDB提供了一系列的內置角色,我們可以使用它們來進行mongodb的管理。
我們也可以創建自定義的角色,定制我們需要的權限。
內置角色
2、加密設置
2.1傳輸加密
使用TLS/SSL (Transport Layer Security/Secure Sockets Layer) 對網絡傳輸進行加密。
在使用SSL之前,須使用有一個包含一對公鑰、私鑰證書的.pem文件。
MongoDB可以使用任何權威證書和自簽名證書發行的有效SSL證書。
為mongod和mongos配置TLS/SSL
2.2存儲加密
2.3應用程序級別加密
走進MongoDB(二)