
Python爬蟲之利用正則表達式爬取內涵吧
阿新 • • 發佈:2017-09-03
file res start cnblogs all save nts quest ide
首先,我們來看一下,爬蟲前基本的知識點概括
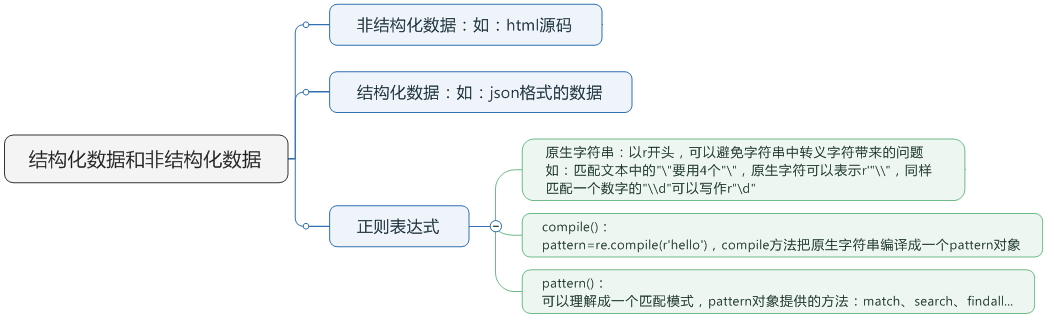
一. match()方法:
這個方法會從字符串的開頭去匹配(也可以指定開始的位置),如果在開始沒有找到,立即返回None,匹配到一個結果,就不再匹配。
我們可以指定開始的位置的索引是3,範圍是3-10,那麽python將從第4個字符‘1‘開始匹配,只匹配一個結果。
group()獲得一個或多個分組的字符串,指定多個字符串時將以元組的形式返回,group(0)代表整個匹配的字串,不填寫參數時,group()返回的是group(0)。
1 import re 2 3 pattern = re.compile(r‘\d+‘) #匹配數字一次以上4 m = pattern.match(‘one123two456‘) 5 print m 6 print m.group() 7 8 #None 9 #...AttributeError: ‘NoneType‘ object has no attribute ‘group‘ 10 11 12 pattern = re.compile(r‘\d+‘) #匹配數字一次以上 13 m = pattern.match(‘one123two456‘. 3, 10) 14 print m 15 print m.group() 16 17 #<_sre.SRE_Match object at 0x00000000026FAE68>18 #123
二. search()方法:
search方法與match比較類似,區別在於match()方法只檢測是不是在字符串的開始位置匹配,search()會掃描整個字符串查找匹配,同樣,search方法只匹配一次。
1 import re 2 3 pattern = re.compile(r‘\d+‘) 4 m = pattern.search(‘one123two456‘) 5 print m.group() 6 7 #123
三. findall()方法:
搜索字符串,以列表的形式返回全部能匹配的字串。
1 import re 2 3 pattern = re.compile(r‘\d+‘) 4 m = pattern.findall(‘one123two456‘) 5 print m 6 7 #[‘123‘, ‘456‘]
四. sub()方法:
用來替換每一個匹配的字符串,並返回替換後的字符串。
1 import re 2 3 pattern = re.compile(r‘\d+‘) 4 m = pattern.sub(‘abc‘, ‘one123two456‘) 5 print m 6 7 #oneabctwo456
五. 實踐:爬取內涵吧段子
1 #-*-coding:utf-8-*- 2 3 import requests 4 import re 5 6 class Spider: 7 8 def __init__(self): 9 self.page = 1 10 11 def getPage(self, page): 12 url = "http://www.neihan8.com/article/list_5_{}.html".format(page) 13 response = requests.get(url) 14 contents = response.content.decode(‘gbk‘) #查看網頁源代碼,內涵吧默認編碼是charset=gb2312 15 return contents 16 17 def getContent(self): 18 contents = self.getPage(self.page) 19 pattern = re.compile(‘<h4>.*?<a href.*?html">(.*?)</a>.*?class="f18 mb20">(.*?)</div>‘, re.S) 20 results = pattern.findall(contents) 21 contents = [] 22 for item in results: 23 title = re.sub(‘<b>|</b>‘, "", item[0]) 24 content = re.sub(r‘<p>|</p>|<br />|&\w+;|<img alt.*|<div style=.*>|<div>|<p style="text-align: center; ">‘, "", item[1]) 25 content = re.sub(r‘<div class="upload-txt.*baseline;">|<h1 class="title".*vertical-align: baseline;">|</h1>‘, "", content) 26 content = re.sub(r‘<div class=.*onclick="showAnswer(this)">|</a><div class="answer">‘, "", content) 27 content = re.sub(r‘<span style="color: rgb.*;">‘, "", content) 28 contents.append([title, content]) 29 return contents 30 31 def save_Data(self): 32 file = open("duanzi.txt", "w+") 33 x = 1 34 y = 1 35 for self.page in range(0, 507): 36 contents = self.getContent() 37 print u"正在寫入第%d頁的數據..." %(self.page+1) 38 for item in contents: 39 file.write(str(x) + "." + item[0]) 40 file.write("\n") 41 file.write(item[1]) 42 file.write("=====================================================================================\n\n") 43 if item==contents[-1]: 44 file.write(u"********第" + str(y) + "頁完********\n\n") 45 y += 1 46 x += 1 47 print u"所有頁面已加載完" 48 49 def start(self): 50 self.save_Data() 51 52 53 spider = Spider() 54 spider.start()
基本上可以獲取段子的標題和內容,但由於內涵吧的段子越到後面標簽越復雜,所以給替換標簽帶來了很大的難度。
Python爬蟲之利用正則表達式爬取內涵吧