
Java解析html頁面,獲取想要的元素
阿新 • • 發佈:2017-09-05
parse tails src www 標準 pro 1.8 com 9.png
背景:通過接口訪問數據,獲取的內容是個標準的html格式,使用jsoup的方式獲取頁面元素值
先推薦比較好的博客:http://www.open-open.com/jsoup/、 單個案例比較不錯
http://blog.csdn.net/u010814849/article/details/52526582 整合內容很多
1.插件下載並安裝
官網安裝地址:http://jsoup.org/packages/jsoup-1.8.1.jar
2.使用(目前都是用的css方式定位元素)
1.獲取這個網頁的商品標題內容
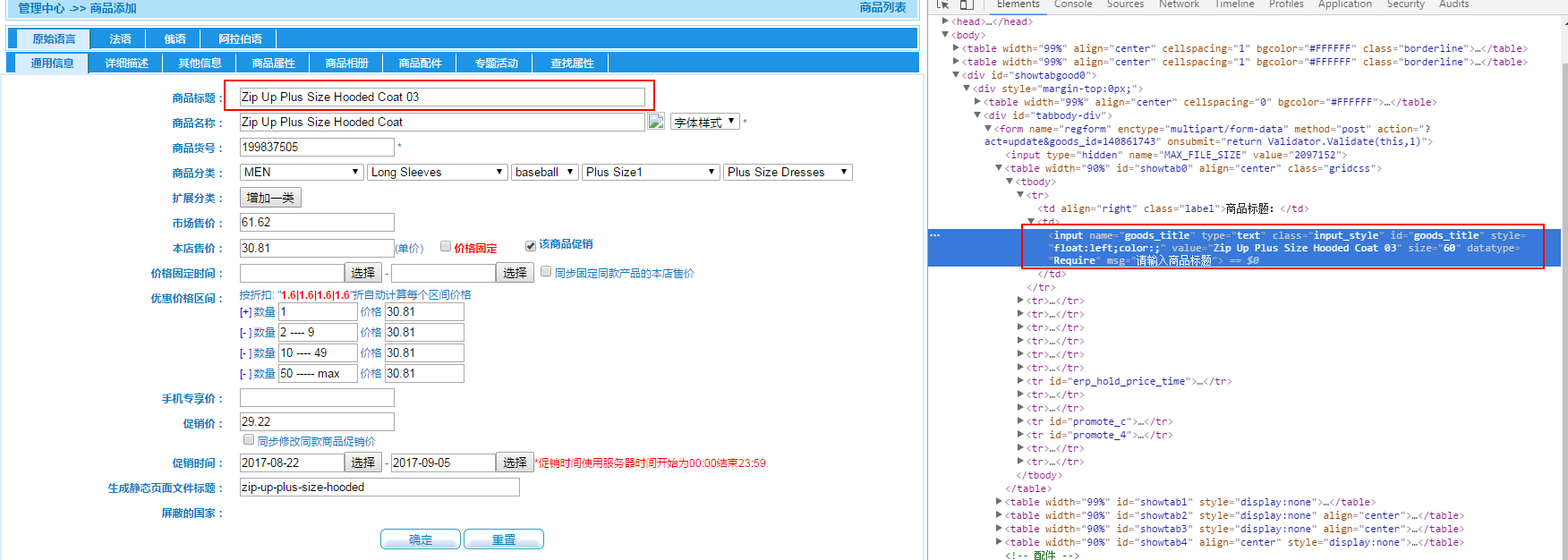
代碼說明:response為頁面的網頁元素,一個標準的html
Document doc = Jsoup.parse(resopnes); //使用jsoup 進行語言轉換 String getTitle = doc.select("#goods_title").attr("value");// 商品標題 #使用css方式

2. 獲取靜態頁面的標題,元素input

可直接使用瀏覽器的css方式:#showtab0 > tbody > tr:nth-child(2) > td:nth-child(2) > input.input_style
Document doc = Jsoup.parse(resopnes); // 使用jsoup 進行語言轉換
String getProductName = doc.select("#showtab0 > tbody > tr:nth-child(2) > td:nth-child(2) > input.input_style").attr("value");
System.out.println("商品名稱:"+getProductName); 
3.獲取其他說明,元素為textarea
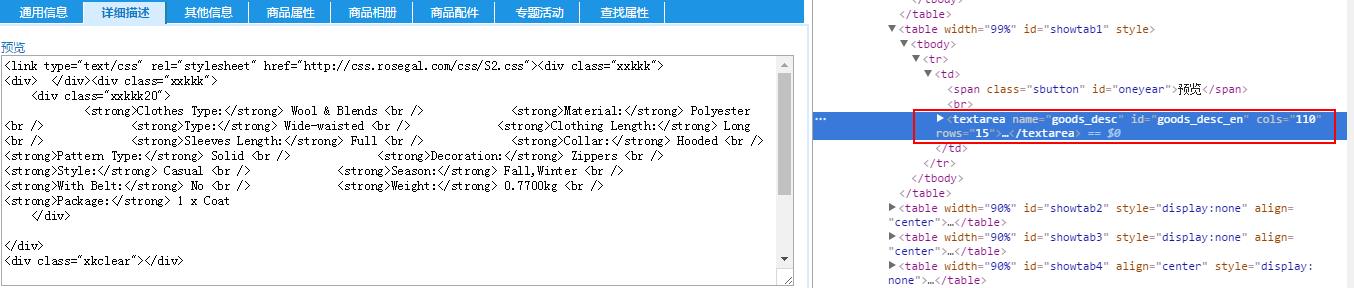
String detail = doc.select("#goods_desc_en").text();// 詳細描述
System.out.println("詳細描述"+detail);

Java解析html頁面,獲取想要的元素