
自己編寫的spark代碼執行流程
阿新 • • 發佈:2017-09-05
一次 ram class work 時代 部分 16px 分享 jvm
我們自己編寫了spark代碼後;放到集群中一執行,就會出現問題,沒有序列化、指定的配置文件不存在、classnotfound等等。這其實很多時候就是因為我們對自己編寫的spark代碼執行流程的不熟悉導致的,源碼閱讀可以解決,但源碼不是每個人都能看懂或能看進去的,下面我們就來講一下,我們自己寫的spark代碼究竟是這麽執行的。從執行的過程可分為三個部分來分析main方法,RDD處理方法,DStream處理方法,從執行的JVM虛擬機可以分為兩個部分driver端,worker端
一、main方法
main方法就是在driver端執行的,當然這裏是把RDD計算的Action剔除的情況,先看一段代碼
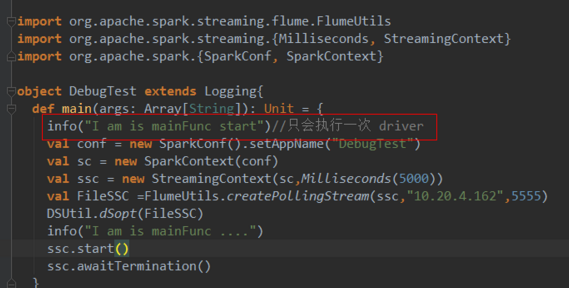
 1、driver端
除了Dstram計算action中的代碼其他都是在driver端並且只執行一次,
這裏需要註意的是DStream的action方法(閉包)中的代碼也不是全在worker端執行,只有在處理rdd時才會在Worker端執行,其他是在driver端執行的
與DStream的action方法外的代碼區別是,這裏是計算一次執行一次。
2、worker端
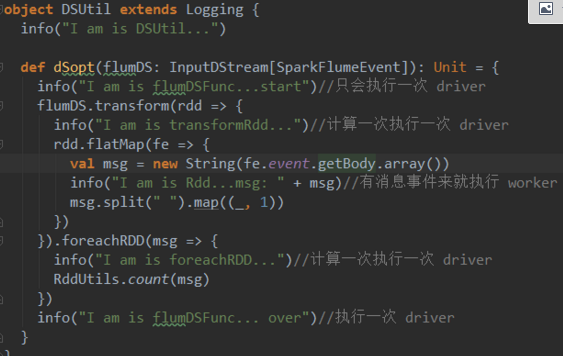
1、driver端
除了Dstram計算action中的代碼其他都是在driver端並且只執行一次,
這裏需要註意的是DStream的action方法(閉包)中的代碼也不是全在worker端執行,只有在處理rdd時才會在Worker端執行,其他是在driver端執行的
與DStream的action方法外的代碼區別是,這裏是計算一次執行一次。
2、worker端 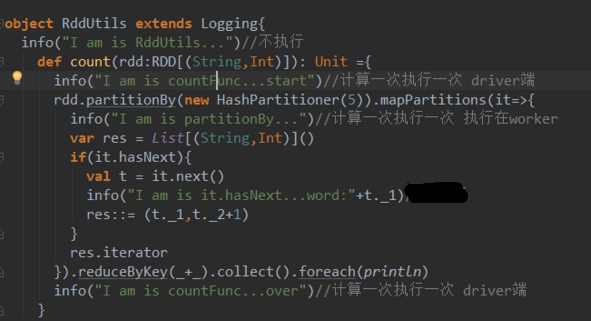 1、driver端
擋在調用count方法處理rdd時,與rdd算子無關的代碼都是計算一次執行一次
2、worker端
rdd的算子閉包是在driver端中執行的
1、driver端
擋在調用count方法處理rdd時,與rdd算子無關的代碼都是計算一次執行一次
2、worker端
rdd的算子閉包是在driver端中執行的
1、driver端
除了Dstram計算action中的代碼其他都是在driver端並且只執行一次,
這裏需要註意的是DStream的action方法(閉包)中的代碼也不是全在worker端執行,只有在處理rdd時才會在Worker端執行,其他是在driver端執行的
與DStream的action方法外的代碼區別是,這裏是計算一次執行一次。
2、worker端
1、driver端
擋在調用count方法處理rdd時,與rdd算子無關的代碼都是計算一次執行一次
2、worker端
rdd的算子閉包是在driver端中執行的
自己編寫的spark代碼執行流程