
http請求原理
客戶端發送一個HTTP請求到服務器的請求消息包括以下格式:請求行(request line)、請求頭部(header)、空行和請求數據四個部分組成,下圖給出了請求報文的一般格式。
請求行

HTTP響應也由四個部分組成,分別是:狀態行、消息報頭、空行和響應正文。
下面是一些最常見的請求頭:
Accept:瀏覽器可接受的MIME類型。
Accept - Charset:瀏覽器可接受的字符集。
Accept - Encoding:瀏覽器能夠進行解碼的數據編碼方式,比如gzip。Servlet能夠向支持gzip的瀏覽器返回經gzip編碼的HTML頁面。許多情形下這可以減少5到10倍的下載時間。
Accept - Language:瀏覽器所希望的語言種類,當服務器能夠提供一種以上的語言版本時要用到。
Authorization:授權信息,通常出現在對服務器發送的WWW - Authenticate頭的應答中。
Connection:表示是否需要持久連接。如果Servlet看到這裏的值為“Keep - Alive”,或者看到請求使用的是HTTP 1.1(HTTP 1.1默認進行持久連接),它就可以利用持久連接的優點,當頁面包含多個元素時(例如Applet,圖片),顯著地減少下載所需要的時間。要實現這一點,Servlet需要在應答中發送一個Content - Length頭,最簡單的實現方法是:先把內容寫入ByteArrayOutputStream,然後在正式寫出內容之前計算它的大小。
Content - Length:表示請求消息正文的長度。
Cookie:這是最重要的請求頭信息之一,參見後面《Cookie處理》一章中的討論。
From:請求發送者的email地址,由一些特殊的Web客戶程序使用,瀏覽器不會用到它。
Host:初始URL中的主機和端口。
If - Modified - Since:只有當所請求的內容在指定的日期之後又經過修改才返回它,否則返回304“Not Modified”應答。
Pragma:指定“no - cache”值表示服務器必須返回一個刷新後的文檔,即使它是代理服務器而且已經有了頁面的本地拷貝。
Referer:包含一個URL,用戶從該URL代表的頁面出發訪問當前請求的頁面。
User - Agent:瀏覽器類型,如果Servlet返回的內容與瀏覽器類型有關則該值非常有用。
UA - Pixels,UA - Color,UA - OS,UA - CPU:由某些版本的IE瀏覽器所發送的非標準的請求頭,表示屏幕大小、顏色深度、操作系統和CPU類型。

HTTP狀態碼
當瀏覽者訪問一個網頁時,瀏覽者的瀏覽器會向網頁所在服務器發出請求。當瀏覽器接收並顯示網頁前,此網頁所在的服務器會返回一個包含HTTP狀態碼的信息頭(server header)用以響應瀏覽器的請求。
HTTP狀態碼的英文為HTTP Status Code。
下面是常見的HTTP狀態碼:
200 - 請求成功
301 - 資源(網頁等)被永久轉移到其它URL
404 - 請求的資源(網頁等)不存在
500 - 內部服務器錯誤
·HTTP請求流程
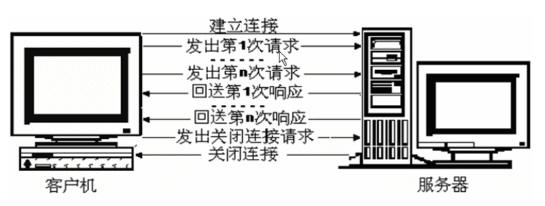
首先,http屬於Tcp/Ip模型中的應用層協議,而兩個應用程序(我們這裏指的就是瀏覽器與服務器)之間要進行互相通信,首先得建立Tcp連接,然後瀏覽器才能向服務器發送請求信息,服務器在接受到請求信息後,返回相應的應答信息,瀏覽器接收到來自服務器的應答信息後,對這些數據進行解釋執行。
在http 1.0的版本中,瀏覽器的每次請求(也就是對每一個頁面的訪問)都要求建立一次單獨的連接,在處理完每一次的請求後,就自動釋放連接。(這點我們應該都有感覺,比如我們訪問一個頁面,當該頁面在瀏覽器中顯示出來的時候,我們可以拔掉網線,此時該頁面上的信息並不會丟失。)而當我們請求的網頁文件中有很多圖片、音樂、電影等信息時,服務器返回的信息中並不直接包含圖片數據,而只是保存該圖片的鏈接,當瀏覽器進行解釋的時候,遇到圖片的url時,才向服務器發出對圖片的請求信息。可見如果一個網頁中包含多個圖片數據時,將會頻繁的與服務器建立連接,與釋放連接,這無疑會造成資源的浪費。

http 1.0 請求模式
而http 1.1則可以在一次連接中處理多個請求,並且多個請求可以重疊進行,不需要等待一個請求結束後再發送下一個請求。
 ·HTTP請求消息
·HTTP請求消息1次完整的http請求消息包括:一個請求行、若幹消息頭以及實體內容,而消息頭和實體內容可以沒有,消息頭和實體內容間有一個空行。
我們來看一個例子(為了便於說明,我在每行前加了序號):
1 Get /mattmarg/ HTTP/1.0
2 User-Agent: Mozilla/2.0 (Macintosh; I; PPC)
3 Accept: text/html; */*
4 Cookie: name = value
5 Referer: http://www.XXX.com/a.html
其中,第1行就是請求行:請求方式為Get(除了Get之外,還有Post、Put、Delete方式),請求的文件位於"根目錄/mattmarg/"下,當然也可以直接給出需要的頁面(如:/mattmarg/index.asp,也可以加上一些其它字段 如:/mattmarg/index.asp?id=1&uid=xxx。當我們通過Get請求時,提交給服務器的請求行長度不能超過1K,而如果利用Post方式,則是把所提交的信息以實體內容形式發送給服務器,所以如果服務器沒有限制的話,原則上講可以傳輸無限大的內容),HTTP/1.0 表示了http的版本為1.0。其余幾行就是消息頭了,消息頭主要是用來向服務器傳達某種信息或指示。如告訴服務器自己的終端(User-Agent)是什麽(如果是瀏覽器則返回相應的瀏覽器型號),終端所可以解釋的類型(Accept)是什麽,是從哪個頁面提交的請求(Referer),以及瀏覽器所能解釋的語言(Accept-Language)等等。我們這裏拿Accept-Language來舉個例子,大家都知道google在中國大陸顯示的是簡體中文,而在其它的國家則顯示對應的語言,這個是怎麽做到的呢?其實就是瀏覽器向服務器遞交的請求信息中包含了Accept-Language,而我們的瀏覽器默認是zh-cn,然後服務器在接受到該信息時返回對應的頁面。
我們可以通過以下方法來驗證一下:
1、打開瀏覽器->工具->internet選項->常規選項卡 2、選擇"語言",可見默認的語言是中文
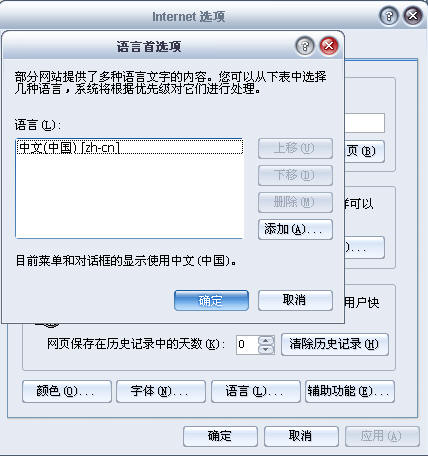
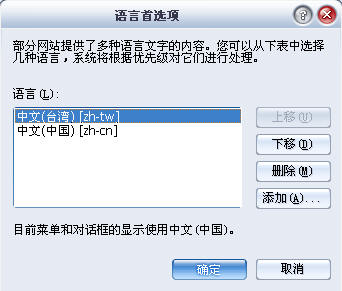
4、確定之後,我們再訪問一下http://www.google.com/,是不是發現原來的簡體中文全都成了繁體字了。
·HTTP響應消息
Http響應消息的格式為:一個狀態行、若幹消息頭和實體內容,其中消息頭和實體內容可以沒有,消息頭和實體內容間有一個空行。
我們依舊先來看一個例子:
01 HTTP/1.1 200 OK
02 Server: Microsoft-IIS/5.1
03 X-Powered-By: ASP.NET
04 Date: Sun, 06 Jul 2008 11:01:21 GMT
05 Content-Type: text/html
06 Accept-Ranges: bytes
07 Last-Modified: Wed, 02 Jul 2008 01:01:26 GMT
08 ETag: "0f71527dfdbc81:ade"
09 Content-Length: 46
10
11 <html><head></head><body>adfasfa</body></html>
其中,01行是狀態行,用於顯示服務器響應的狀態,HTTP/1.1顯示了對應的http協議版本,200為狀態數字,OK為狀態信息用於解釋狀態數字(這裏OK對應200,表示請求正常);02~09是消息頭部分,10為空行,11為實體內容(也就是服務器返回的網頁內容)。
好了,相信大家應該已經對這個http請求的流程有了一個大概的了解了吧,那麽我們反過來回答下最初留下的問題:當我們在瀏覽器的地址欄中輸入 "http://www.baidu.com/ " ,然後按"回車",這之後發生了什麽事?。
首先,瀏覽器找到該網址所指向的IP,然後與其建立TCP連接,接著向百度服務器提出Get請求,當服務器接收到我們的請求後,向我們傳送應答信息--百度的頁面,然後斷開連接。
參考:http://www.cnblogs.com/stg609/archive/2008/07/06/1236966.html
http請求原理