
統計參數語音合成的初學者指南
原文地址鏈接:https://shartoo.github.io/texttospeech/
譯自:A beginners’ guide to statistical parametric speech synthesis
一 語音合成(Text-To-Speech)TTS 概述
TTS系統的輸入是文本,輸出為語音waveform。TTS一般分為兩部分。第一部分將文本轉換為語言規範,第二部分使用此規範來生成waveform。這種劃分帶來的好處是,系統前端基本是語言規範相關的,而waveform生成可以獨立於語言。
文本轉換為語言規範一般使用序列的分離處理和多種內部中間表征來完成。
本文主要討論的是使用統計參數方法來合成語音。
二 從聲碼到合成
關於語音合成的描述一般是以一種程序式的眼光:通常將文本轉換為語音轉化為簡單的pipeline結構。但是,其他方法認為語音合成是從聲碼器開始的,語音信號被轉換為某些可以被傳遞的表征。聲碼器如下圖
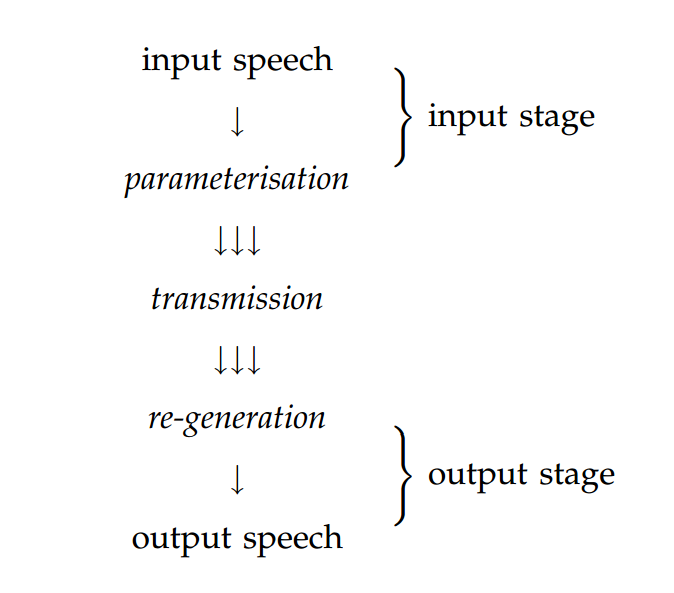
我們可以將語音合成看做類似的架構,但是其中的參數化的語音的傳遞應該替換為存儲。如下圖:

後面再解釋參數化和生成對應語音waveform。
此系統包含訓練和合成兩個階段。訓練階段,存儲的form由語音庫(訓練數據)獲得。通過以語言規範索引這些存儲的form,可以實現僅以語言規範作為輸入,語音waveform為輸出的合成系統。
存儲的form可以是語音數據本身或者從數據中得到的統計模型。
2.1 語言規範
由上文可知,輸入為語言規範。這可以很簡單,比如音素序列,但是為了更好的結果,它需要包含超分段信息,比如產生語音的韻律模式。換句話說,語言規範包含了全部的影響聲學模型實現的音素。
如何理解語言規範,我們可以以單詞speech為例。語言規範需要涵蓋可能影響這個原因聲音的所有信息。即,它要包含出現此元音的全部上下文信息。此例子中,重要的情景因素包括前面的雙邊清音爆破(著會影響元音的共振峰軌跡)和此元音位於單音節詞內(影響元音的存續時間)等等。
情景自然會包含相同單詞相同發音內的因素,比如周圍音素,單詞和韻律模式,但是可能會拓展到周圍發聲,並進一步到協同因素如講話者的心情或者聽者的身份。對話語料中,上下文可能需要包含與其他講話者的因素。實際上,大部分系統只考慮發聲內部的因素。下表列出了在典型系統中會考慮的上下文因素:
| 上下文因素 |
|---|
| Preceding and following phonemes |
| Position of segment in syllable |
| Position of syllable in word & phrase |
| Position of word in phrase |
| Stress/accent/length features of current/preceding/following syllables |
| Distance from stressed/accented syllable |
| POS of current/preceding/following word |
| Length of current/preceding/following phrase |
| End tone of phrase |
| Length of utterance measured in syllables/words/phrases |
列出的因素對每個語音聲音有潛在的影響。考慮到每個因素可能的取值數量(比如preceding phoneme可能有多達50個不同取值)以及排序的數量,很明顯,即便只考慮語言學成立的組合,不同情景的數量巨大。但不是所有因素在所有時刻都有影響。實際上,我們希望少量因素在任意時刻都有顯著影響。這可以顯著減少情景。關鍵問題,我們會在第四節再看,它來決定哪個因素在何時比較重要。
對每個將要合成的句子,前端需要做的是從文本預測語言規範。需要任務都需要由前端完成(比如,從拼寫來預測發音),這些都是與特定語言相關的。
2.2 基於示例的模型
基於示例的語音合成系統簡單的存儲語音庫,整個語料庫或選擇的一部分。使用語言規範來索引此類存儲的form即給存儲的語音數據打標簽,使得其合適的部分得以被知曉,在合成階段抽取、連接即可。 在典型的單元選取系統,打標簽包含了對齊語音和韻律信息。恢復過程不是不重要,由於合成時所需的抽取規範在語料中不存在,所以需要在眾多輕微的不匹配單元中做出選擇。語音應該被存儲為waveform或者其他適合拼接的表征形式,比如殘差激活的LPC。
2.3 基於模型的系統
基於模型的系統並不存儲任何語音。相反,它在訓練期間將模型適配語音庫,並存儲模型。模型將按照獨立的語音單元構建,比如情景依賴的音素:這樣模型就能被語言規範索引。在合成階段,合適的情景依賴模型序列被檢索到並用來生成語音。由於只有有限數量的訓練數據,某些模型的缺失,這可能沒法檢索到。因而有可能對任意所需語言規範創建on-the-fly(直接使用的)模型。這可以通過在足夠多的相似模型間共享參數完成。
2.4 索引存儲的form
為了讓存儲的form,無論是語音或模型,能夠被語言規範索引到,有必要為語音語料庫中的每個發聲產生語言規範。人工標簽可以,但是不現實,也太費錢。常見的方法是,使用與合成句子語音時相同的前端,基於文本對應的語音語料庫來預測語言規範。這可能與講話者不是最佳匹配。
然而,一些從自動語音識別方法借鑒過來的基於強制對齊的技術,可以用來提高打標簽的準確率,包括自動識別真的停頓位置和一些發音變化。
三 語音合成的統計參數模型
我們談及基於模型的語音合成時,尤其指從數據中學習模型時,我們通常指的是統計參數模型。模型的參數化是因為它使用參數來描述語音,而不是存儲的模板。稱為統計是因為使用統計項來描述這些參數(比如,概率密度函數的均值和方差),這些統計項是從訓練數據中的參數值分布習得的。
站在歷史的角度上看,統計參數語音合成源於HMM在語音識別中的成功。沒人可以說HMM就是語音的真實模型。但是其有效的學習算法(EM),模型復雜度控制(parameter tying)的自動方法和高效計算的搜索算法(Viterbi search)使得HMM稱為一個非常強力的算法。至於評估模型的性能,語音識別使用的是單詞錯誤率,而在語音合成通過聽力測試,這非常依賴於合適的配置。這個配置中兩個重要的方面是語音信號的參數化(HMM術語中的模型的觀察值)和建模單元的選取。由於建模單元基本是上下文依賴的音素,此選取即將哪些上下文因素考慮在內。下表概述了自動語音識別和語音合成的參數配置的差異:
Comparison of Hidden (Semi) Markov Model configurations for recognition vs. synthesis
| recognition | synthesis | |
|---|---|---|
| observations | spectral envelope represented using around 12 parameters | spectral envelope represented using 40-60 parameters, plus source features |
| modelling unit | triphone, considering preceding and following phoneme | full context, considering preceding two and succeeding two phonemes plus all other context features listed in Table 1 |
| duration model | state self-transitions | explicit parametric model of state duration |
| parameter estimation | Baum-Welch | Baum-Welch, or Trajectory Training |
| decoding | Viterbi search | not usually required |
| generation | not required | Maximum-likelihood parameter generation |
3.1 信號表征
語音信號由在固定幀率(frame rate)的聲碼器參數集表征。典型的表征可能對每個幀使用40-60個參數來代表頻譜包裝(envelope),F0(基準頻率)的值和5個描述非周期激發的頻譜包裝的參數。訓練模型之前,聲碼器的編碼階段用來抽取向量,該向量包含了語音信號中的聲碼參數,5秒的幀率。在合成階段,整個向量由模型生成,然後用於驅動聲碼器的輸出。
從原理上講,任何聲碼器都可以用於基於HMM的語音合成,只需要它能提供的參數足以高質量的重建語音信號並且這些參數可以在訓練階段自動抽取。這可能類似於一個共振峰。然而,由於參數可以被統計建模,一些聲碼器可以比其他的聲碼器表現的更好。出現在統計建模中的基本操作是平均訓練階段的聲碼器參數以及生成的新值(我們可以將其類比於在訓練數據中獲取的插值和外推法的值)。因此,在這種操作下聲碼器的參數值必須是表現較好並且不會導致不穩定的值。例如,線譜對可能比現行預測參數更好的表征,因為前者在插值下表現較好,而後者可能會導致不穩定的過濾。
一種流行的廣泛應用於HMM合成的聲碼器是STRAIGHT (Speech Transformation and Representation using Adaptive Interpolation of weiGHTed spectrum)。我們可以說,STRAIGHT可以處理上述所需屬性並且在實際應用中表現較好。
3.2 術語
3.2.1 HSMMs而非HMMs
在統計參數合成語音中所使用的模型大部分其實完全不是HMMs。HMM中的持續時間模型(duration model,比如說自轉換)相當簡單,而且高質量的語音合成需要更好的持續時間模型。一旦加入一個明確的持續時間模型加入到HMM,它不再是一個馬爾科夫模型了。模型現在是半馬爾科夫–狀態之間的轉換依然存在,但是每個狀態的明確的持續時間模型不是馬爾科夫。此時模型為半隱馬爾可夫模型(Hidden Semi-Markov Model),或者說是HSMM。不過我們言及HMM語音合成時,一般實際指的是HSMM語音合成。
3.2.2 標簽和上下文
前面描述的語言規範是一個復雜的、結構化的表征;它可能包含列表、樹、和其他有用於語言學的結構。基於HMM的語音合成即從模型的線性序列中生成語音,其中每個模型對應了一個指定的語言單元類型。 因此,有必要將結構化的語言規範flatten到線性序列的標簽。可以通過附加其他所有的語言信息(關於音節結構,韻律等)到語言規範中的音素上,其結果是線性的上下文依賴的音素序列。根據這些全上下文標簽,可以挖掘對應的HMMs序列,從這裏可以生成語音。
3.2.3 Statics, deltas and delta-deltas
聲碼器的輸出階段和產生語音僅需要聲碼器參數。然而,使用HMMs合成聽起來自然的語音的關鍵取決於,不僅是給這些參數的統計分布建模,而且還有建模其變化頻率,比如速度,聲碼器參數即static coefficients(靜態系數)以及它們的一階導數即delta系數。實際上,通過建模加速度(modelling acceleration),可以獲得delta-delta系數。
這三種類型的參數被堆疊在一個觀察向量中。訓練期間,模型學習這些參數的分布。合成階段,模型生成有合適統計屬性的參數的軌跡。
3.3 訓練
如語音識別一樣,HMMs合成必須在標簽數據上訓練。標簽必須是如上文描述的全上下文標簽,它們由2.4節所描述的方法產生。
3.4 合成
合成階段只給文本作為輸入,如下處理。
首先,輸入文本被分析並產生全上下文標簽的序列。模型的序列對應了此標簽序列,然後連接成一個長的狀態鏈。從這個模型,聲碼器參數使用下文算法生成。最終,生成的聲碼器參數被用來驅動聲碼器的輸出階段來產生語音waveform。
從模型中生成參數:最大似然概率被用作從模型中生成觀測值序列。首先,我們考慮使用直白的方法來做這個,然後看到這會產生不自然的參數軌跡。然後,再使用實際所使用的方法。註意到參數項被指為模型的輸出,而不是模型的參數(高斯分布的均值和方差)。
持續時間:在直白的方法和下文描述的 MLPG算法,其持續時間(比如,由模型的每個狀態生成的參數的幀的數目)都是提前決定的,它們是簡化的確定狀態持續時間分布的均值。
直白方法的參數生成:此方法生成每個狀態的最可能的觀測值,它只考慮統計參數。最可能的觀測值當然是那個狀態的高斯均值。因此這個方法生成分段的常量參數軌跡,它會突兀的改變每個狀態轉換處的值。顯然,當用做驅動聲碼器時,這聽起來會不自然。這個問題將由MLPG算法解決。
MLP最大似然參數生成算法:上述方法忽略了自然語音中參數軌跡的非常重要的一個方面。它只考慮了靜態(static)參數的統計屬性。但是在自然語音中,它不僅是聲碼器參數以固定方式呈現的絕對值,它還包含了改變值的速度。我們需要將delta系數的統計屬性也考慮在內。實際上,我們還可以考慮delta-delta系數的統計屬性。下圖演示了MLPG算法:
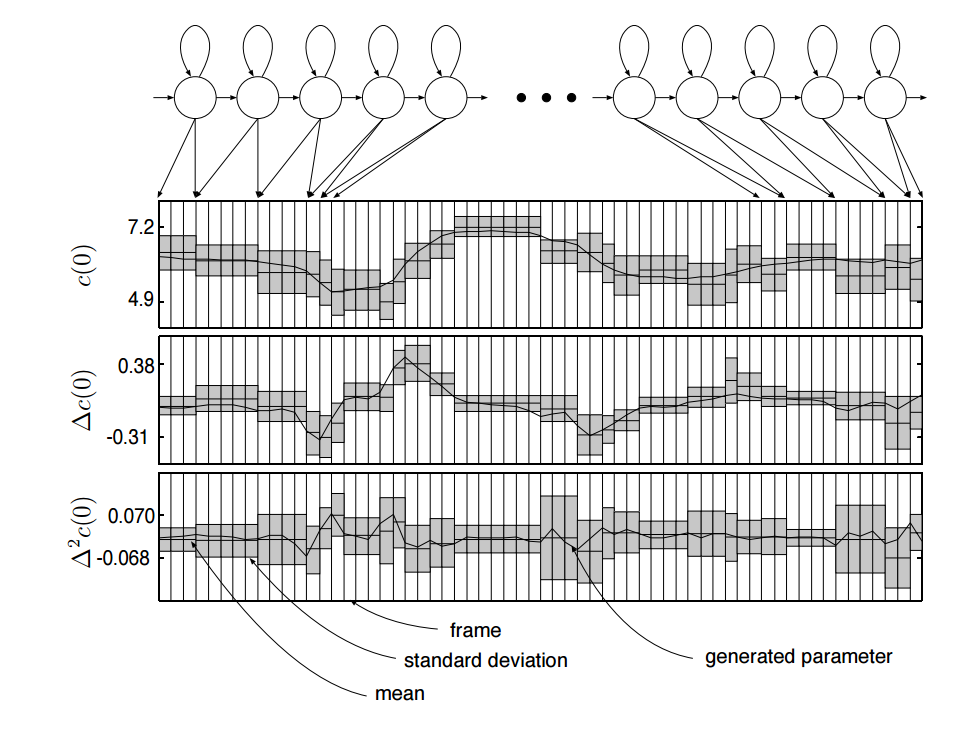
最大似然參數生成:從離散的分布序列,將delta系數和delta-delta系數統計屬性考慮在內,來生成平滑的軌跡
HMM已經被構建:是對全上下文標簽序列的所對應的模型的拼接,其本身已經被前端工具從文本中預測。在生成參數之前,使用持續時間模型選取了狀態序列。這會決定模型中每個狀態將會生成多少幀。上圖展示了每個狀態的一幀一幀的輸出分布的序列。MLPG根據靜態參數、delta、delta-delta分布找到最大可能的生成的參數的序列。此圖只給第0個倒譜系數(c(0)c(0) ),但是對所有由模型生成的參數使用相同的規律,比如F0。
理解MLPG算法生成的東西的最簡單的方法是,考慮一個例子:在圖中找到一個δc(0)δc(0)為正的區域:靜態參數 c(0)c(0)在該點處於上升,它有正的斜率。因此,靜態系數的統計屬性是分段常量,最可能的參數軌跡是以一種合適的方式平滑變動的。
四 生成新語音:未預見的上下文
生成語音的關鍵問題在於生成我們沒有在自然狀態下錄制的語音。這就需要從更小單元(從模型拼接或生成)來構建語音。由於我們未曾預見一模一樣的上下文環境的此類單元,此問題可以被描述為,從由訓練集數據觀察到的有限上下文集合泛化為幾乎無限的未出現的上下文。
是否語料庫夠大就可以覆蓋所有經常出現的上下文,不幸的是並不是這樣。
顯而易見的原因是,從表1可以知道有極其豐富的上下文,這會導致兩個問題。首先,由於上下文橫跨整個語音,語音語料庫中每個上下文依賴的單元的出現幾乎是唯一的:它只會出現一次(假設不存在重復的句子)。其二,海量的大多數可能的上下文依賴的單元將永不會在語音語料庫中出現:語料庫對語言只有很稀疏的覆蓋。
即便暫時不考慮這種海量的上下文依賴,語料庫中任意語言單元(比如,音素,音節,單詞)分布遠不能正態化。它有低頻或0頻率的長尾。換句話說,有很多類型的單元將會僅僅出現一次或者完全不在語料庫中。此現象即大量稀有事件。盡管每種類型稀少,但是有太多的類型,這會導致還是很可能碰上。對於任意將要合成的語音,有很高的概率需要一些很稀有的單元類型(比如,上下文依賴的音素)。沒有有限的語料庫可以覆蓋我們所需的全部的稀有類型,因此簡單的增加語料庫於事無補。
我們可以將此問題看做 從有限訓練數據中泛化的問題,這就形成了一種模型復雜度控制形式的方法。
4.1 泛化
常用方法,尤其是自然語言,是一個上文提到的長尾分布(類似Zipf分布)。即,數據中少量類型有較多實例,而大量類型僅有很少或者沒有實例。這使得直接給稀有或者未觀測到的類型建模不可能,因為實例太少無法學到任何東西。這在語音合成中必然會遇到,其中的類型是上下文中的音素。
給數據打標簽可以減少類型的數目進而轉移這個問題,在語音合成中即減少考慮的情景因素的數目。但是,我們並沒有先驗知識知道哪些情景因素可以被移除,哪些應該被保留,因為它們對問題中的音素的實現有很大影響。更進一步說,哪些情景因素比較重要是隨著復雜的交互結合變化的。
一種較好的解決辦法是繼續使用大量的類型來給數據打標簽並控制模型的復雜度,而不是控制標簽的復雜度。 在常見的基於HMM的合成方法的控制模型復雜度的方法是借鑒自自動語音識別,並有關在相似模型中共享(或者tying)參數,以達到:
-
合適的模型復雜度(例如,數據裏合適數量的自由參數)
-
對那些僅有較少實例的更好的參數評估
3.對於完全沒有的實例的參數評估方法。
為了決定哪些模型足夠相似(可用共享參數),再次考慮這些情景因素。由於(我們也這麽期望)在任意時刻都只需要考慮少量因素,我們可以專註於一個情景依賴模型的集合,其中每個模型,只需要考慮相關情景。情景依賴的數量可能不同的模型也不一樣。結果便是,只有被訓練數據所支撐的上下文差異可以被建模。沒有影響的上下文因素被丟棄,根據模型的偏差。一個簡單示例,想象前音素的identity對於實現[S ]沒有顯著影響,但是接下來的音素的identity對其有影響。這種情況,模型組可以按照下述方式共享相同參數:對於所有上下文[…aft..],[…Ift…],[…eft..]來說是一個模型,對其他所有上下文如[..afe…],[…ife…],[…efe…]…來說是另外一個模型。
決定不同上下文之間哪些模型可以共享參數的機制是由數據驅動的。模型的復雜度(或者說,有多麽多或多麽少的參數綁定)是自動選擇以適應可用的訓練數據的數量的:越多的數據模型越復雜。
4.2 使用參數綁定來控制模型復雜度
模型復雜度控制即給模型選取合適數量的自由參數。在基於HMM的語音合成中,這意味著選取哪種情景分布值得去選取而哪些不重要。換句話說,對於兩個不同的 情景,我們何時應該使用獨立的模型,合適使用相同的模型。
一種在自動語音識別中廣泛應用的模型復雜度控制的技術牽連到相似模型的聚類。情景因素中指定了哪種模型可以聚為一類,並且實際被選取的聚類是那種可以最好的將訓練數據和模型擬合的。此方法被基於HMM的語音合成方法采用,這其實在語音識別中更重要,僅僅因為有更多的大量的不同情景需要應對。有一種聚類用的決策樹方法(Martin 2009)。
模型被聚類之後,不同模型的數量遠遠小於不同情景的數量。對於指定數據,聚類過程會自動發現最優的情景差異。訓練數據集越大,我們可以使用更多的模型並做出更多精細的差異。
註意:實際上狀態綁定和參數綁定是獨立的,但是規律是一樣的。
4.3 單元選取的關系
在單元選取合成中,情景因素在單元選取上的影響是由目標代價來衡量的。目標損失函數的最常見形式是簡單的對每個不匹配的情景因素懲罰項加權求和。目標損失函數旨在在數據庫中識別最不差的單元候選。一種可選形式的目標損失稱為clunits,使用類似於上文描述的模型聚類方法的情景聚類樹,但是樹中的葉子節點代表的不是模型參數而是從數據庫中獲得的語音單元聚類。
目標是一致的:從數據中已知的來泛化出未知的。這是通過自動發現哪些情景在效力上是可互換的達到的。在單元選取中即找到一組足夠相似的候選單元來用在不在語音語料庫中的目標情景中;在語音合成中意味著將一組情景均值化來訓練單一模型。
五常見問題
ASK1: 如何預測韻律
ANS2:這裏分兩部分。首先,韻律的符號表征是由前端預測的,與拼接合成中類似 。其二,此符號表征用作在生成語音的全情景模型的情景因素的一部分。假設(a)每個韻律有足夠的訓練樣本(b)訓練數據的真實韻律和韻律標簽有一些一致性,然後每個不同的韻律情景有不同的模型並且在語音合成時模型會 生成合適的韻律。如果(a)或(b)有一個不滿足,那麽參數聚類將無法形成指定韻律情景模型。
ASK2什麽導致了語音合成中的“嗡嗡”的問題
ANS2:因為語音時聲碼。“嗡嗡”主要源於聲源的過度簡化的模型。使用混合激發(韻律和非周期性源的混合)的聲碼而不是在二者之間切換,可以減少“嗡嗡”。
ASK3 什麽導致了語音合成中的悶聲
ANS3:均值化,這是統計模型的訓練過程中不可避免的步驟,可能導致語音聽起來悶悶的。多幀語音的均值,每個幀都有輕微不同的頻譜屬性,這會有拓寬共振峰帶寬並減少頻譜包裝的動態範圍的影響。類似的,均值化可能導致過度平滑的頻譜包裝(envelopes)和過度平滑的軌跡。一種常用的以抵消這種影響的方法是,調整生成的參數使得它們有在自然語音中相同的偏差。此方法稱為Global Variance(GV,全局偏差)。
ASK4為什麽持續時間要分開建模
ANS4:標準HMM中的持續時間模型源自每個狀態的自轉移。此模型下,大部分可能的持續時間總是一個狀態一幀,在自然狀態下顯然不對。因而,明確的持續時間模型就很有必要。持續時間模型並不是真的從頻譜包絡(envelop)和源分離的。它們在模型結構上交互。然而,影響持續時間的情景因素在不同的頻譜和源特征下不同,所以這些各種各樣的模型參數組是分開聚類的。
統計參數語音合成的初學者指南