
Hadoop學習------Hadoop安裝方式之(三):分布式部署
這裏為了方便直接將單機部署過的虛擬機直接克隆,當然也可以不這樣做,一個個手工部署。
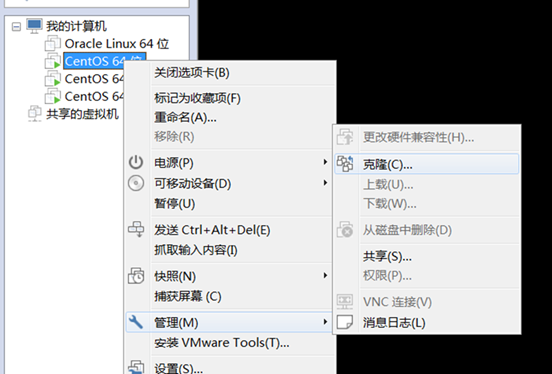
創建完整克隆——>下一步——>安裝位置。等待一段時間即可。
我這邊用了三臺虛擬機,分別起名master,slave1.slave2
1、修改主機名、ip
1.1關閉防火墻
CentOS系統默認開啟了防火墻,在開啟 Hadoop 集群之前,需要關閉集群中每個節點的防火墻。有防火墻會導致 ping 得通但 telnet 端口不通,從而導致 DataNode 啟動了,但 Live datanodes 為 0 的情況。
在 CentOS 6.x 中,可以通過如下命令關閉防火墻:
service iptables stop # 關閉防火墻服務
chkconfig iptables off # 禁止防火墻開機自啟,就不用手動關閉了
若用是 CentOS 7,需通過如下命令關閉(防火墻服務改成了 firewall):
systemctl stop firewalld.service # 關閉firewall
systemctl disable firewalld.service # 禁止firewall開機啟動
1.2 修改主機名
在 CentOS 6.x 中 vi /etc/sysconfig/network
在CentOS 7或者Ubuntu 中 vi /etc/hostname

在其他兩節點同樣如此。分別改為slave1.slave2
1.3 修改ip地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0 修改ip 地址 然後重啟網卡
service network restart 發現重啟失敗

這是因為基本系統的網絡相關配置都是基於eth0的,如果基於此克隆虛擬機繼續克隆或復制新的虛擬機,網卡的標識每一次都會自動加1變成eth1(第二次克隆會變成eth2),dmesg卻顯示內核只識別到網卡eth0。
解決辦法: 打開/etc/udev/rules.d/70-persistent-net.rules 記錄下,eth1網卡的mac地址00:0c:29:50:bd:17
接下來 vi//etc/sysconfig/network-scripts/ifcfg-eth0
將 DEVICE="eth0" 改成 DEVICE="eth1" ,
將 HWADDR="00:0c:29:8f:89:97" 改成上面的mac地址 HWADDR="00:0c:29:50:bd:17"
最後,重啟網絡 service network restart 然後就能重啟成功
1.4 修改hosts 使所用節點IP映射
在每臺虛擬機上進行如下操作。
vi /etc/hosts
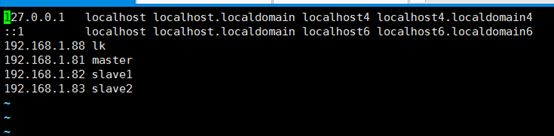
修改完成後需要重啟一下 reboot
2、打通master到slave節點的SSH無密碼登錄
2.1設置本機無密碼登錄(各節點都要)
之前在單機部署時已經設置過了,這裏再說一遍,沒有設置的可以看下
第一步:產生密鑰
ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa
第二部:導入authorized_keys
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
第二部導入的目的是為了無密碼等,這樣輸入如下命令:
ssh localhost

2.2 設置遠程無密碼登錄
我這邊偷懶用的是root用戶,正規應該用hadoop用戶
進入slave1的.ssh目錄 cd /root/.ssh
復制公鑰文件到master
scp authorized_keys [email protected]:~/.ssh/authorized_keys_from_master
進入到master的.ssh目錄 將文件導入到authorized_keys
cat authorized_keys_from_master >> authorized_keys
此時 slave1 可以無密碼遠程登錄master
同理
進入slave2的.ssh目錄 cd /root/.ssh
復制公鑰文件到master
scp authorized_keys [email protected]:~/.ssh/authorized_keys_from_master
進入到master的.ssh目錄 將文件導入到authorized_keys
cat authorized_keys_from_master >> authorized_keys
然後 將master 的authorized_keys文件復制到slave1和slave2中,他們之間就可以互相無密碼遠程訪問。
scp authorized_keys [email protected]:~/.ssh/authorized_keys
scp authorized_keys [email protected]:~/.ssh/authorized_keys
ssh [email protected] 不需要密碼就直接進去了

3、修改配置文件
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5個配置文件,更多設置項可點擊查看官方說明,這裏僅設置了正常啟動所必須的設置項: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
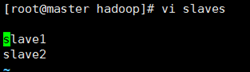
3.1 文件slaves
文件 slaves,將作為 DataNode 的主機名寫入該文件,每行一個,默認為 localhost,所以在偽分布式配置時,節點即作為 NameNode 也作為 DataNode。分布式配置可以保留 localhost,也可以刪掉讓 Master 節點僅作為 NameNode 使用。
這裏讓 Master 節點僅作為 NameNode 使用,因此將文件中原來的 localhost 刪除,只添加兩行內容:slave1。slave2
cd /usr/local/hadoop/etc/hadoop/
vi slaves
3.2 core-site.xml
cd /usr/local/hadoop/etc/hadoop/
vi core-site.xml
在其中的<configuration>中添加以下內容
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
3.3 hdfs-site.xml
dfs.replication 的值是副節點個數,有幾個就寫幾個,這邊設為2
cd /usr/local/hadoop/etc/hadoop/
vi hdfs-site.xml
其中的<configuration>中添加以下內容
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
3.4 mapred-site.xml
cd /usr/local/hadoop/etc/hadoop/
需要將mapred-site.xml.template 文件改名或者復制一份
mv mapred-site.xml.template mapred-site.xml
或 cp mapred-site.xml.template mapred-site.xml
然後在進行編輯 vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
3.5 yarn-site.xml
cd /usr/local/hadoop/etc/hadoop/
vi yarn-site.xml
在其中的<configuration>中 添加以下內容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3.6 啟動並檢驗
配置好後,按照以上步驟在各個節點均執行一邊,或者將 master 上的 /usr/local/Hadoop 文件夾復制到各個節點上。
在master
cd /usr/local
sudo rm -r ./hadoop/tmp # 刪除 Hadoop 臨時文件
sudo rm -r ./hadoop/logs/* # 刪除日誌文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先壓縮再復制
scp ./hadoop.master.tar.gz slave1:/usr/local
在slave1
tar -zxf ~/hadoop.master.tar.gz -C /usr/local
chown -R hadoop /usr/local/hadoop
在slave2上執行同樣操作。就能將Hadoop部署好。
每個節點部署好後
在節點上執行NameNode 的格式化
hdfs namenode –format 或者 hadoop namenode format
啟動hdfs 在master節點上執行 start-dfs.sh
啟動yarn 在master節點上執行 start-yarn.sh
啟動job history server 在master節點上執行 mr-jobhostory-daemon.sh start historyserver
通過命令 jps 可以查看各個節點所啟動的進程。正確的話,在 Master 節點上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 進程
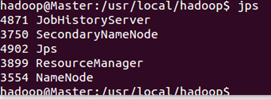
在 Slave 節點可以看到 DataNode 和 NodeManager 進程
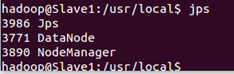
缺少任一進程都表示出錯。另外還需要在 Master 節點上通過命令 hdfs dfsadmin -report 查看 DataNode 是否正常啟動,如果 Live datanodes 不為 0 ,則說明集群啟動成功。
同樣我們可以通過 Web 頁面看到查看 DataNode 和 NameNode 的狀態:http://master:50070/。如果不成功,可以通過啟動日誌排查原因。
3.7執行分布式實例
創建 HDFS 上的用戶目錄
hdfs dfs -mkdir -p /user/hadoop
將 /usr/local/hadoop/etc/hadoop 中的配置文件作為輸入文件復制到分布式文件系統中
hdfs dfs -mkdir input
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
通過查看 DataNode 的狀態(占用大小有改變),輸入文件確實復制到了 DataNode 中
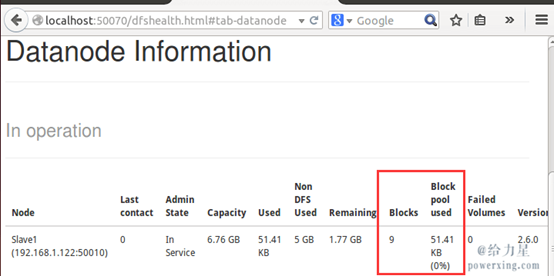
接著就可以運行 MapReduce 作業了
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output ‘dfs[a-z.]+‘
運行時的輸出信息與偽分布式類似,會顯示 Job 的進度。
可能會有點慢,但如果遲遲沒有進度,比如 5 分鐘都沒看到進度,那不妨重啟 Hadoop 再試試。若重啟還不行,則很有可能是內存不足引起,建議增大虛擬機的內存,或者通過更改 YARN 的內存配置解決。
同樣可以通過 Web 界面查看任務進度 http://master:8088/cluster,在 Web 界面點擊 “Tracking UI” 這一列的 History 連接,可以看到任務的運行信息
4 、關閉Hadoop集群
同樣關閉Hadoop集群也是在Master節點上執行的
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
Hadoop學習------Hadoop安裝方式之(三):分布式部署