
Gson 使用總結 高級用法
阿新 • • 發佈:2017-09-12
構造 over nds 部分 score read print next() return
Gson提供了fromJson() 和toJson() 兩個直接用於解析和生成的方法,前者實現反序列化,後者實現了序列化。
我們知道Gson在序列化和反序列化時需要使用反射,說到反射就不得不想到註解。一般各類庫都將註解放到annotations包下,打開源碼在com.google.gson包下果然有一個annotations,裏面有一個SerializedName的註解類,這應該就是我們要找的。
為POJO字段提供備選屬性名
如果接口設計不嚴謹或者其它地方可以重用該類,其它字段都一樣,就emailAddress 字段不一樣,比如有下面三種情況那怎麽辦?重新寫一個POJO類?
SerializedName註解提供了兩個屬性,上面用到了其中一個,另外還有一個屬性alternate,接收一個String數組。
當我們要通過Gson解析這個jsonArray時,一般有兩種方式:使用數組,使用List。而List對於增刪都是比較方便的,所以實際使用是還是List比較多。數組比較簡單:
為了解決的上面的問題,Gson為我們提供了 TypeToken 來實現對泛型的支持,所以當我們希望使用將以上的數據解析為 List<String> 時需要這樣寫:
泛型解析對POJO設計的影響
泛型的引入可以減少無關的代碼,如我現在所在公司接口返回的數據分為兩類:
PS:嫌每次 new TypeToken<Result<XXX> 和 new TypeToken<Result<List<XXX>> 太麻煩,想進一步封裝? 查看另一篇博客: 搞定Gson泛型封裝
Gson的流式反序列化
Gson提供了十幾個fromJson()和toJson()方法,前者實現反序列化,後者實現了序列化,常用的有如下5個:
Gson的流式序列化
Gson.toJson方法列表
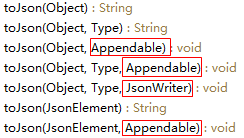 可以看出用紅框選中的部分就是我們要找的東西。
可以看出用紅框選中的部分就是我們要找的東西。
提示:PrintStream(System.out) 、StringBuilder、StringBuffer和**Writer都實現了Appendable接口。
使用GsonBuilder配置Gson
一般情況下Gson類提供的 API已經能滿足大部分的使用場景,但當我們需要更多更特殊、更強大的功能時,可以使用GsonBuilder配置Gson。
例如,Gson在默認情況下是不導出值為null的鍵的,當我們需要導出完整的json串時,或API接口要求沒有值必須用Null時,可以這麽配置:
字段過濾的四種方法
字段過濾是Gson中比較常用的技巧,特別是在Android中,在處理業務邏輯時可能需要在設置的POJO中加入一些字段,但顯然在序列化的過程中是不需要的,並且如果序列化還可能帶來一個問題就是:循環引用 。那麽在用Gson序列化之前為不防止這樣的事件情發生,你不得不作另外的處理。
以一個商品分類Category 為例:
並且為了處理業務,我們還需要在子分類中保存父分類,最終會變成下面的情況:
基於註解@Expose
使用規則:簡單說來就是需要導出的字段上加上@Expose 註解,不導出的字段不加。註意是不導出的不加。由於兩個屬性都有默認的值true,所有值為true的屬性都是可以不寫的。如果兩者都為true,只寫 @Expose 就可以。
拿上面的例子來說就是:
基於版本和註解@Since @Until
Gson在對基於版本的字段導出提供了兩個註解 @Since 和 @Until,需要和GsonBuilder.setVersion(Double)配合使用
Since和Until註解的定義:
基於訪問修飾符
什麽是修飾符?不知道的話建議看一下java.lang.reflect.Modifier類,這是一個工具類,裏面為所有修飾符定義了相應的靜態字段,並提供了很多靜態工具方法。
基於策略(自定義規則)
上面介紹的了3種排除字段的方法,說實話我除了@Expose以外,其它的都是只在Demo用上過,用得最多的就是馬上要介紹的自定義規則啦,好處是功能強大、靈活,缺點是相比其它3種方法稍麻煩一點,但也僅僅只是相對其它3種稍麻煩一點點而已。
基於策略是利用Gson提供的ExclusionStrategy接口,同樣需要使用GsonBuilder,相關API 2個,分別是addSerializationExclusionStrategy 和addDeserializationExclusionStrategy,分別針對序列化和反序化時。這裏以序列化為例:
自定義POJO與JSON的字段映射規則
GsonBuilder提供了setFieldNamingPolicy和setFieldNamingStrategy兩個方法,用來設置字段序列和反序列時字段映射的規則。
1、GsonBuilder.setFieldNamingPolicy方法與 Gson 提供的另一個枚舉類FieldNamingPolicy配合使用:
2、GsonBuilder.setFieldNamingStrategy方法需要與Gson提供的FieldNamingStrategy接口配合使用,用於實現將POJO的字段與JSON的字段相對應。上面的FieldNamingPolicy實際上也實現了FieldNamingStrategy接口,也就是說FieldNamingPolicy也可以使用setFieldNamingStrategy方法。
TypeAdapter 自定義(反)序列化
TypeAdapter 是Gson自2.0(源碼註釋上說的是2.1)開始版本提供的一個抽象類,用於接管某種類型的序列化和反序列化過程,包含兩個主要方法 write(JsonWriter,T) 和 read(JsonReader),其它的方法都是final方法並最終調用這兩個抽象方法。
TypeAdapter 使用示例1
Json(De)Serializer
JsonSerializer 和JsonDeserializer 不用像TypeAdapter一樣,必須要實現序列化和反序列化的過程,你可以據需要選擇,如只接管序列化的過程就用 JsonSerializer ,只接管反序列化的過程就用 JsonDeserializer ,如上面的需求可以用下面的代碼。
下面是所有數字(Number的子類)都轉成序列化為字符串的例子:
泛型與繼承
使用 registerTypeAdapter 時不能使用父類來替上面的子類型,這也是為什麽要分別註冊而不直接使用Number.class的原因。
不過換成 registerTypeHierarchyAdapter 就可以使用 Number.class 而不用一個一個的單獨註冊子類啦!
兩者的區別:
註意:如果一個被序列化的對象本身就帶有泛型,且註冊了相應的TypeAdapter,那麽必須調用Gson.toJson(Object,Type),明確告訴Gson對象的類型;否則,將跳過此註冊的TypeAdapter。
TypeAdapterFactory
TypeAdapterFactory,見名知意,用於創建 TypeAdapter 的工廠類。使用方式:與GsonBuilder.registerTypeAdapterFactory配合使用,通過對比Type,確定有沒有對應的TypeAdapter,沒有就返回null,有則返回(並使用)自定義的TypeAdapter。
註解 @JsonAdapter
2017-9-12
Gson基本用法
參考:http://www.jianshu.com/p/e740196225a4Gson提供了fromJson() 和toJson() 兩個直接用於解析和生成的方法,前者實現反序列化,後者實現了序列化。
POJO類的生成與解析//基本數據類型的解析 int i = gson.fromJson("100", int.class); //100 boolean b = gson.fromJson("true", boolean.class); // true String str = gson.fromJson("包青天", String.class); // 包青天 //基本數據類型的生成 String jsonNumber = gson.toJson(100); // 100 String jsonBoolean = gson.toJson(true); // true String jsonString = gson.toJson("包青天"); // 包青天 System.out.println(i + " " + b + " " + str + " " + jsonNumber + " " + jsonBoolean + " " + jsonString);//100 true 包青天 100 true "包青天"
class User { //省略構造函數、toString方法等 public String name; public int age; } //生成JSON User user = new User("包青天",24); String jsonObject = gson.toJson(user); // {"name":"包青天","age":24} //解析JSON: String jsonString = "{\"name\":\"包青天\",\"age\":24}"; User user = gson.fromJson(jsonString, User.class);
屬性重命名 @SerializedName
從上面POJO的生成與解析可以看出,JSON串中的 key 和JavaBean中的 field 是完全一致的,但有時候也會出現一些不和諧的情況,如:期望的json格式:
{"name":"包青天","age":24,"emailAddress":"[email protected]"}
實際的json格式:
{"name":"包青天","age":24,"email_address":"[email protected]"}我們知道Gson在序列化和反序列化時需要使用反射,說到反射就不得不想到註解。一般各類庫都將註解放到annotations包下,打開源碼在com.google.gson包下果然有一個annotations,裏面有一個SerializedName的註解類,這應該就是我們要找的。
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD })
public @interface SerializedName {
String value();//方法名為value()的屬性不需要指定key
String[] alternate() default {};//默認為空
}@SerializedName("email_address")
public String emailAddress;為POJO字段提供備選屬性名
如果接口設計不嚴謹或者其它地方可以重用該類,其它字段都一樣,就emailAddress 字段不一樣,比如有下面三種情況那怎麽辦?重新寫一個POJO類?{"name":"包青天","age":24,"emailAddress":"[email protected]"}
{"name":"包青天","age":24,"email_address":"[email protected]"}
{"name":"包青天","age":24,"email":"[email protected]"}SerializedName註解提供了兩個屬性,上面用到了其中一個,另外還有一個屬性alternate,接收一個String數組。
@SerializedName(value = "emailAddress", alternate = {"email", "email_address"})
public String emailAddress;Gson中使用泛型 TypeToken
上面了解了JSON中的Number、boolean、Object和String,現在說一下Array。當我們要通過Gson解析這個jsonArray時,一般有兩種方式:使用數組,使用List。而List對於增刪都是比較方便的,所以實際使用是還是List比較多。數組比較簡單:
String jsonArray = "[\"Android\",\"Java\",\"PHP\"]";
String[] strings = gson.fromJson(jsonArray, String[].class);為了解決的上面的問題,Gson為我們提供了 TypeToken 來實現對泛型的支持,所以當我們希望使用將以上的數據解析為 List<String> 時需要這樣寫:
List<String> list = gson.fromJson(jsonArray, new TypeToken<List<String>>() {}.getType());泛型解析對POJO設計的影響
泛型的引入可以減少無關的代碼,如我現在所在公司接口返回的數據分為兩類:{"code":"0","message":"success","data":{}}
{"code":"0","message":"success","data":[]}public class UserResponse {
public int code;
public String message;
public User data;
}public class Result<T> {
public int code;
public String message;
public T data;
}PS:嫌每次 new TypeToken<Result<XXX> 和 new TypeToken<Result<List<XXX>> 太麻煩,想進一步封裝? 查看另一篇博客: 搞定Gson泛型封裝
Gson的流式反序列化
Gson提供了十幾個fromJson()和toJson()方法,前者實現反序列化,後者實現了序列化,常用的有如下5個:public String toJson(Object src);//序列化,通用
//反序列化,自動方式
public <T> T fromJson(String json, Class<T> classOfT);//普通的對象
public <T> T fromJson(String json, Type typeOfT);//使用泛型時使用
//反序列化,手動方式
public <T> T fromJson(Reader json, Class<T> classOfT);
public <T> T fromJson(Reader json, Type typeOfT);String json = "{\"name\":\"包青天\",\"age\":\"24\"}";
User user = new User();
JsonReader reader = new JsonReader(new StringReader(json));
reader.beginObject(); // throws IOException
while (reader.hasNext()) {
String s = reader.nextName();
switch (s) {
case "name":
user.name = reader.nextString();
break;
case "age":
user.age = reader.nextInt(); //自動轉換
break;
}
}
reader.endObject(); // throws IOException
System.out.println(user.name+" "+user.age); // 包青天 24public <T> T fromJson(String json, Type typeOfT) throws JsonSyntaxException {
if (json == null) return null;
StringReader reader = new StringReader(json);
T target = fromJson(reader, typeOfT);
return target;
}Gson的流式序列化
Gson.toJson方法列表可以看出用紅框選中的部分就是我們要找的東西。提示:PrintStream(System.out) 、StringBuilder、StringBuffer和**Writer都實現了Appendable接口。
User user = new User("包青天",24);
gson.toJson(user,System.out); // 自動寫到控制臺JsonWriter writer = new JsonWriter(new OutputStreamWriter(System.out));
writer.beginObject() // throws IOException
.name("name").value("包青天")//
.name("age").value(24)//
.name("email").nullValue() //演示null
.endObject(); // throws IOException
writer.close(); // throws IOException。{"name":"包青天","age":24,"email":null}JsonWriter writer = new JsonWriter(new OutputStreamWriter(System.out));
writer.beginObject() // throws IOException
.name("name").value("包青天")//
.name("興趣").beginArray().value("籃球").value("排球").endArray()//
.endObject(); // throws IOException
writer.close(); // throws IOException。{"name":"包青天","興趣":["籃球","排球"]}使用GsonBuilder配置Gson
一般情況下Gson類提供的 API已經能滿足大部分的使用場景,但當我們需要更多更特殊、更強大的功能時,可以使用GsonBuilder配置Gson。例如,Gson在默認情況下是不導出值為null的鍵的,當我們需要導出完整的json串時,或API接口要求沒有值必須用Null時,可以這麽配置:
Gson gson = new GsonBuilder()
.serializeNulls()//序列化null
.setDateFormat("yyyy-MM-dd") // 設置日期時間格式,另有2個重載方法。在序列化和反序化時均生效
.setPrettyPrinting()//格式化輸出。設置後,gson序列號後的字符串為一個格式化的字符串
.create();
User user = new User("包青天", new Date());
System.out.println(gson.toJson(user));{
"name": "包青天",
"email": null,
"date": "2017-09-12",
}字段過濾的四種方法
字段過濾是Gson中比較常用的技巧,特別是在Android中,在處理業務邏輯時可能需要在設置的POJO中加入一些字段,但顯然在序列化的過程中是不需要的,並且如果序列化還可能帶來一個問題就是:循環引用 。那麽在用Gson序列化之前為不防止這樣的事件情發生,你不得不作另外的處理。以一個商品分類Category 為例:
{
"id": 1,
"name": "電腦",
"children": [
{
"id": 100,
"name": "筆記本"
},
{
"id": 101,
"name": "臺式機"
}
]
}並且為了處理業務,我們還需要在子分類中保存父分類,最終會變成下面的情況:
public class Category {
public int id;
public String name;
public List<Category> children;
public Category parent; //因業務需要增加,但並不需要序列化
}基於註解@Expose
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({java.lang.annotation.ElementType.FIELD})
public @interface Expose{
boolean serialize() default true;//默認序列化生效
boolean deserialize() default true;//默認反序列化生效
}Gson gson = new GsonBuilder().excludeFieldsWithoutExposeAnnotation().create();//不配置時註解無效使用規則:簡單說來就是需要導出的字段上加上@Expose 註解,不導出的字段不加。註意是不導出的不加。由於兩個屬性都有默認的值true,所有值為true的屬性都是可以不寫的。如果兩者都為true,只寫 @Expose 就可以。
拿上面的例子來說就是:
public class Category {
@Expose public int id;// 等價於 @Expose(deserialize = true, serialize = true)
@Expose public String name;
@Expose public List<Category> children;
public Category parent; //不需要序列化,等價於 @Expose(deserialize = false, serialize = false)
}基於版本和註解@Since @Until
Gson在對基於版本的字段導出提供了兩個註解 @Since 和 @Until,需要和GsonBuilder.setVersion(Double)配合使用Since和Until註解的定義:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.TYPE})
public @interface Since{
double value();
}
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.TYPE})
public @interface Until{
double value();
}class SinceUntilSample {
@Since(4) public String since;//大於等於Since
@Until(5) public String until;//小於Until
@Since(4) @Until(5) public String all;//大於等於Since且小於Until
}
Gson gson = new GsonBuilder().setVersion(version).create();
System.out.println(gson.toJson(sinceUntilSample));
//當version <4時,結果:{"until":"until"}
//當version >=4 && version <5時,結果:{"since":"since","until":"until","all":"all"}
//當version >=5時,結果:{"since":"since"}基於訪問修飾符
什麽是修飾符?不知道的話建議看一下java.lang.reflect.Modifier類,這是一個工具類,裏面為所有修飾符定義了相應的靜態字段,並提供了很多靜態工具方法。System.out.println(Modifier.toString(Modifier.fieldModifiers()));//public protected private static final transient volatileGson gson = new GsonBuilder()
.excludeFieldsWithModifiers(Modifier.FINAL, Modifier.STATIC, Modifier.PRIVATE)//排除了具有private、final或stati修飾符的字段
.create();基於策略(自定義規則)
上面介紹的了3種排除字段的方法,說實話我除了@Expose以外,其它的都是只在Demo用上過,用得最多的就是馬上要介紹的自定義規則啦,好處是功能強大、靈活,缺點是相比其它3種方法稍麻煩一點,但也僅僅只是相對其它3種稍麻煩一點點而已。基於策略是利用Gson提供的ExclusionStrategy接口,同樣需要使用GsonBuilder,相關API 2個,分別是addSerializationExclusionStrategy 和addDeserializationExclusionStrategy,分別針對序列化和反序化時。這裏以序列化為例:
Gson gson = new GsonBuilder()
.addSerializationExclusionStrategy(new ExclusionStrategy() {
@Override
public boolean shouldSkipField(FieldAttributes f) {//返回值決定要不要排除該字段,return true為排除
if ("finalField".equals(f.getName())) return true; //根據字段名排除
Expose expose = f.getAnnotation(Expose.class); //獲取Expose註解
if (expose != null && expose.deserialize() == false) return true; //根據Expose註解排除
return false;
}
@Override
public boolean shouldSkipClass(Class<?> clazz) {//直接排除某個類 ,return true為排除
return (clazz == int.class || clazz == Integer.class);
}
})
.create();自定義POJO與JSON的字段映射規則
GsonBuilder提供了setFieldNamingPolicy和setFieldNamingStrategy兩個方法,用來設置字段序列和反序列時字段映射的規則。1、GsonBuilder.setFieldNamingPolicy方法與 Gson 提供的另一個枚舉類FieldNamingPolicy配合使用:
class User {
String emailAddress;
}
Gson gson = new GsonBuilder().setFieldNamingPolicy(FieldNamingPolicy.IDENTITY).create();//默認
User user = new User("[email protected]");
System.out.println(gson.toJson(user));| FieldNamingPolicy | 結果 |
| IDENTITY 個性/特性/恒等式 | {"emailAddress":"[email protected]"} |
| LOWER_CASE_WITH_DASHES 小寫+破折號 | {"email-address":"[email protected]"} |
| LOWER_CASE_WITH_UNDERSCORES 小寫+下劃線 | {"email_address":"[email protected]"} |
| UPPER_CAMEL_CASE 駝峰式+首字母大寫 | {"EmailAddress":"[email protected]"} |
| UPPER_CAMEL_CASE_WITH_SPACES 駝峰式+空格 | {"Email Address":"[email protected]"} |
2、GsonBuilder.setFieldNamingStrategy方法需要與Gson提供的FieldNamingStrategy接口配合使用,用於實現將POJO的字段與JSON的字段相對應。上面的FieldNamingPolicy實際上也實現了FieldNamingStrategy接口,也就是說FieldNamingPolicy也可以使用setFieldNamingStrategy方法。
public enum FieldNamingPolicy implements FieldNamingStrategyGson gson = new GsonBuilder().setFieldNamingStrategy(new FieldNamingStrategy() {
@Override
public String translateName(Field f) {//實現自己的規則
return null;
}
})
.create();TypeAdapter 自定義(反)序列化
TypeAdapter 是Gson自2.0(源碼註釋上說的是2.1)開始版本提供的一個抽象類,用於接管某種類型的序列化和反序列化過程,包含兩個主要方法 write(JsonWriter,T) 和 read(JsonReader),其它的方法都是final方法並最終調用這兩個抽象方法。public abstract class TypeAdapter<T> {
public abstract void write(JsonWriter out, T value) throws IOException;
public abstract T read(JsonReader in) throws IOException;
//其它final方法就不貼出來了,包括toJson、toJsonTree、fromJson、fromJsonTree和nullSafe等方法。
}TypeAdapter 使用示例1
User user = new User("包青天", 24, "[email protected]";
Gson gson = new GsonBuilder()
.registerTypeAdapter(User.class, new UserTypeAdapter())//為User註冊TypeAdapter
.create();
System.out.println(gson.toJson(user));public class UserTypeAdapter extends TypeAdapter<User> {
@Override
public void write(JsonWriter out, User value) throws IOException {
out.beginObject();
out.name("name").value(value.name);
out.name("age").value(value.age);
out.name("email").value(value.email);
out.endObject();
}
@Override
public User read(JsonReader in) throws IOException {
User user = new User();
in.beginObject();
while (in.hasNext()) {
switch (in.nextName()) {
case "name":
user.name = in.nextString();
break;
case "age":
user.age = in.nextInt();
break;
case "email":
case "email_address":
case "emailAddress":
user.email = in.nextString();
break;
}
}
in.endObject();
return user;
}
}TypeAdapter 使用示例2
再說一個場景,之前已經說過Gson有一定的容錯機制,比如將字符串 "24" 轉成整數24,但如果有些情況下給你返了個空字符串怎麽辦?雖然這是服務器端的問題,但這裏我們只是做一個示範,不改服務端的邏輯我們怎麽容錯。根據我們上面介紹的,我只需註冊一個 TypeAdapter 把 Integer/int 的序列化和反序列化過程接管就行了:Gson gson = new GsonBuilder()
.registerTypeAdapter(Integer.class, new TypeAdapter<Integer>() {//接管【Integer】類型的序列化和反序列化過程
//註意,這裏只是接管了Integer類型,並沒有接管int類型,要接管int類型需要添加【int.class】
@Override
public void write(JsonWriter out, Integer value) throws IOException {
out.value(String.valueOf(value));
}
@Override
public Integer read(JsonReader in) throws IOException {
try {
return Integer.parseInt(in.nextString());
} catch (NumberFormatException e) {
return -1;//當時Integer時,解析失敗時返回-1
}
}
})
.registerTypeAdapter(int.class, new TypeAdapter<Integer>() {//接管【int】類型的序列化和反序列化過程
//泛型只能是引用類型,而不能是基本類型
@Override
public void write(JsonWriter out, Integer value) throws IOException {
out.value(String.valueOf(value));
}
@Override
public Integer read(JsonReader in) throws IOException {
try {
return Integer.parseInt(in.nextString());
} catch (NumberFormatException e) {
return -2;//當時int時,解析失敗時返回-2
}
}
})
.create();
int i = gson.fromJson("包青天", Integer.class); //-1
int i2 = gson.fromJson("包青天", int.class); //-2
System.out.println(i + " " + i2);//-1 -2Json(De)Serializer
JsonSerializer 和JsonDeserializer 不用像TypeAdapter一樣,必須要實現序列化和反序列化的過程,你可以據需要選擇,如只接管序列化的過程就用 JsonSerializer ,只接管反序列化的過程就用 JsonDeserializer ,如上面的需求可以用下面的代碼。Gson gson = new GsonBuilder()
.registerTypeAdapter(Integer.class, new JsonDeserializer<Integer>() {
@Override
public Integer deserialize(JsonElement j, Type t, JsonDeserializationContext c) throws JsonParseException {
try {
return j.getAsInt();
} catch (NumberFormatException e) {
return -1;
}
}
})
.create();下面是所有數字(Number的子類)都轉成序列化為字符串的例子:
JsonSerializer<Number> numberJsonSerializer = new JsonSerializer<Number>() {
@Override
public JsonElement serialize(Number src, Type typeOfSrc, JsonSerializationContext context) {
return new JsonPrimitive(String.valueOf(src));
}
};
Gson gson = new GsonBuilder()
.registerTypeAdapter(Integer.class, numberJsonSerializer)
.registerTypeAdapter(Long.class, numberJsonSerializer)
.registerTypeAdapter(Float.class, numberJsonSerializer)
.registerTypeAdapter(Double.class, numberJsonSerializer)
.create();泛型與繼承
使用 registerTypeAdapter 時不能使用父類來替上面的子類型,這也是為什麽要分別註冊而不直接使用Number.class的原因。不過換成 registerTypeHierarchyAdapter 就可以使用 Number.class 而不用一個一個的單獨註冊子類啦!
Gson gson = new GsonBuilder()
.registerTypeHierarchyAdapter (Number.class, numberJsonSerializer)
.create();兩者的區別:
| registerTypeAdapter | registerTypeHierarchyAdapter | |
|---|---|---|
| 支持泛型 | 是 | 否 |
| 支持繼承 | 否 | 是 |
註意:如果一個被序列化的對象本身就帶有泛型,且註冊了相應的TypeAdapter,那麽必須調用Gson.toJson(Object,Type),明確告訴Gson對象的類型;否則,將跳過此註冊的TypeAdapter。
Type type = new TypeToken<List<User>>() {}.getType();//被序列化的對象帶有【泛型】
TypeAdapter<List<User>> typeAdapter = new TypeAdapter<List<User>>() { .../*省略實現的方法*/ };
Gson gson = new GsonBuilder()
.registerTypeAdapter(type, typeAdapter)//註冊了與此type相應的TypeAdapter
.create();
String result = gson.toJson(list, type);//明確指定type時才會使用註冊的TypeAdapter托管序列化和反序列化
String result2 = gson.toJson(list);//不指定type時使用系統默認的機制進行序列化和反序列化TypeAdapterFactory
TypeAdapterFactory,見名知意,用於創建 TypeAdapter 的工廠類。使用方式:與GsonBuilder.registerTypeAdapterFactory配合使用,通過對比Type,確定有沒有對應的TypeAdapter,沒有就返回null,有則返回(並使用)自定義的TypeAdapter。Gson gson = new GsonBuilder()
.registerTypeAdapterFactory(new TypeAdapterFactory() {
@Override
public <T> TypeAdapter<T> create(Gson gson, TypeToken<T> type) {
if (type.getType() == Integer.class || type.getType() == int.class) return intTypeAdapter;
return null;
}
})
.create();註解 @JsonAdapter
@Retention(RetentionPolicy.RUNTIME)
@Target({java.lang.annotation.ElementType.TYPE, java.lang.annotation.ElementType.FIELD})//作用在類或字段上
public @interface JsonAdapter{
Class<?> value();
boolean nullSafe() default true;
}@JsonAdapter(UserTypeAdapter.class) //加在類上
public class User {
public String name;
public int age;
}2017-9-12
Gson 使用總結 高級用法