
redis筆記
阿新 • • 發佈:2017-09-14
刪除 multi 同步 三種 client log 機制 自身 多個 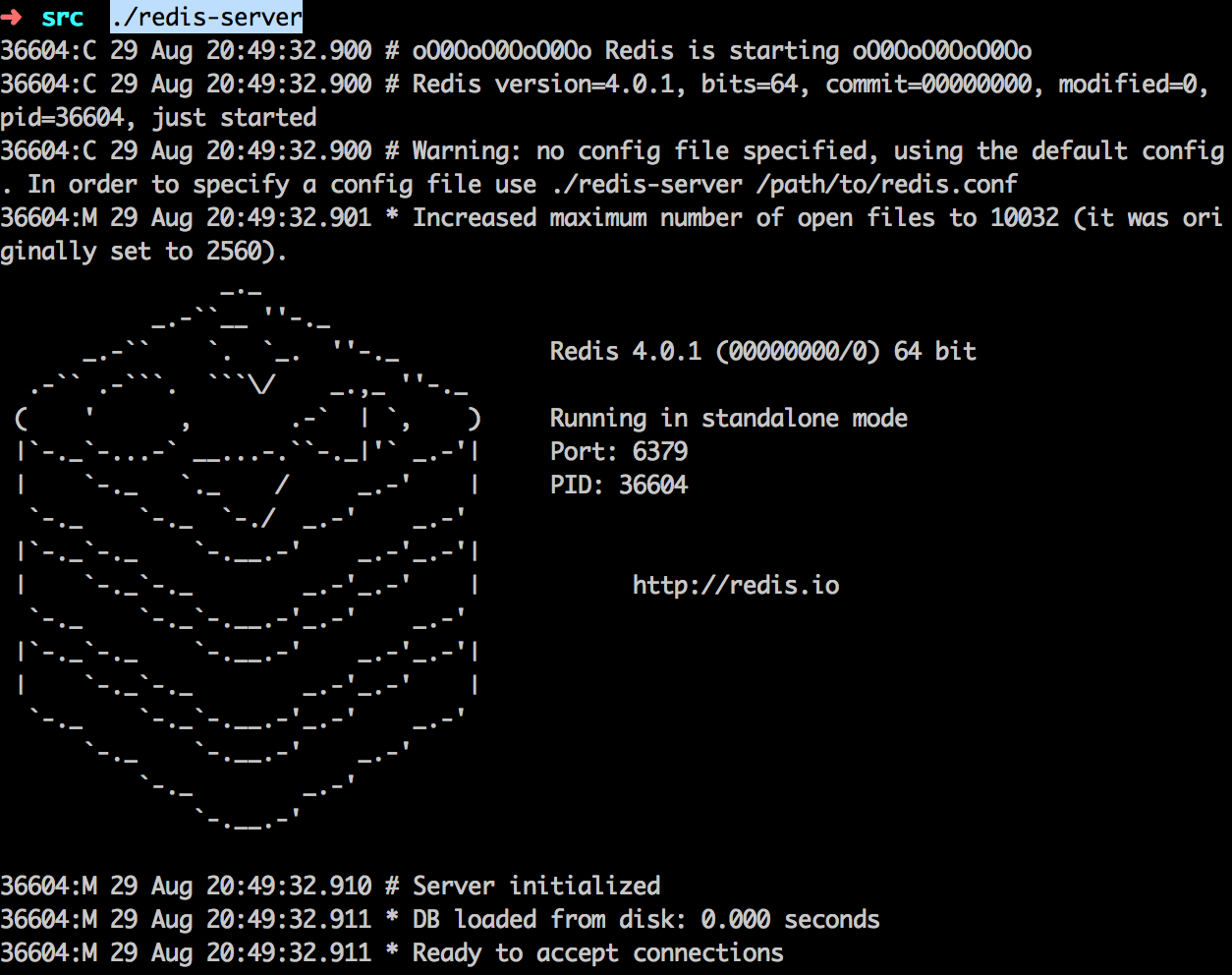 再在文件夾下執行 ./redis-cli 就可以執行redis的命令了。
再在文件夾下執行 ./redis-cli 就可以執行redis的命令了。
 pipelining
一次請求發送多個命令,以提高性能。我們在使用redis時都是向它發送命令,每次都是需要和redis建立tcp連接,然後發送命令信息,redis執行命令後,客戶端等待著redis的響應。這個我們當然知道,就像訪問db,IO開銷都是消耗資源的大頭,所以redis提供了pipelining功能讓它具有一次傳輸多個命令共同執行的能力。
官網解釋文檔:https://redis.io/topics/pipelining
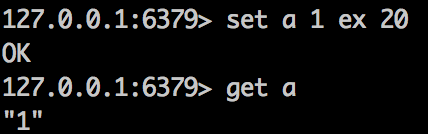
expire
pipelining
一次請求發送多個命令,以提高性能。我們在使用redis時都是向它發送命令,每次都是需要和redis建立tcp連接,然後發送命令信息,redis執行命令後,客戶端等待著redis的響應。這個我們當然知道,就像訪問db,IO開銷都是消耗資源的大頭,所以redis提供了pipelining功能讓它具有一次傳輸多個命令共同執行的能力。
官網解釋文檔:https://redis.io/topics/pipelining
expire 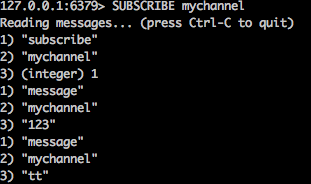 發布者命令:
發布者命令:
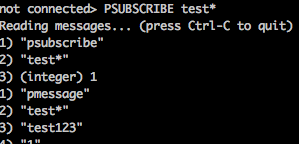
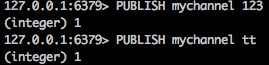 而且還支持對channel的匹配方式,用PSUBSCRIBE和PUNSUBSCRIBE命令。
PSUBSCRIBE test* 或PUNSUBSCRIBEtest* 如此我們發現,發布者是匹配模式,而訂閱者是正常模式,或發布者是正常模式,訂閱者是匹配模式,或兩個都是匹配模式。增大了靈活性。
訂閱者命令:
而且還支持對channel的匹配方式,用PSUBSCRIBE和PUNSUBSCRIBE命令。
PSUBSCRIBE test* 或PUNSUBSCRIBEtest* 如此我們發現,發布者是匹配模式,而訂閱者是正常模式,或發布者是正常模式,訂閱者是匹配模式,或兩個都是匹配模式。增大了靈活性。
訂閱者命令:
 發布者命令:
發布者命令:
 官網文檔:https://redis.io/topics/pubsub
Transactions
官網文檔:https://redis.io/topics/pubsub
Transactions 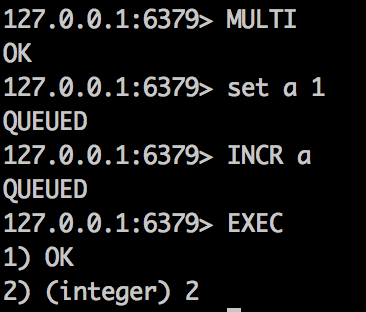 事務中異常場景:
1,在執行MULTI之後EXEC之前,操作redis出現異常的時候,如果收到QUEUED,說明已經在執行列裏了,如果返回error,則需要取消事務。
2,在執行EXEC中出現異常,比如命令本身有錯,那麽事務在執行過程中出錯命令之前的命令將不會會退,而是被提交的。這裏要有特別註意。
如下操作:
事務中異常場景:
1,在執行MULTI之後EXEC之前,操作redis出現異常的時候,如果收到QUEUED,說明已經在執行列裏了,如果返回error,則需要取消事務。
2,在執行EXEC中出現異常,比如命令本身有錯,那麽事務在執行過程中出錯命令之前的命令將不會會退,而是被提交的。這裏要有特別註意。
如下操作:
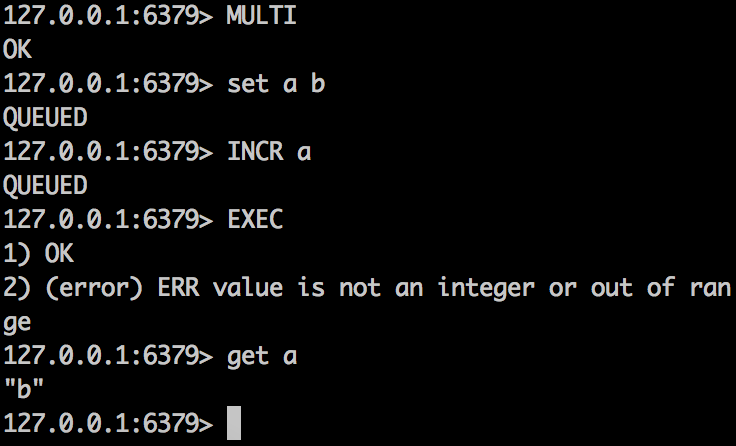 我們看見在執行INCR a 時出錯,因為a的value是字符串。但是前面set命令卻是提交的。
redis為什麽沒有回退操作呢,在官方文檔中有這樣的解釋:
1,它認為redis 命令出錯只是因為語法有問題,那麽在實際場景中應該在到生產環境前已經被測試到。
2,它還認為redis足夠快,所以有自信不需要什麽會退操作。
競爭場景,使用WATCH來保證互斥操作。WATCH的key會被監控,如果在提交前key內容被改動那麽事務會提交失敗。
官網文檔:https://redis.io/topics/transactions
Distributed locks with Redis 官方有文檔描述了如何實現一個他們認為可靠的分布式鎖,他們稱呼這種實現算法為redlock。也提供了各個語言版本的實現列表,java的話它列舉的是Redisson:https://github.com/redisson/redisson
單個redis 主備場景,推薦的是放key來鎖,value是client的唯一標誌,在獲取到已經有值時判斷是否是自己client的value,類似可重入鎖概念。另外在放的key上加上過期時間,防止client掛掉而導致鎖不能被其他client獲得。問題是master放好key,在同步給slave前掛掉了,slave成為master,卻沒有這個鎖的內容。所以它描述了一個redlock,對應的是多個resid主節點的方式來組建起存儲鎖的結構,核心是在所有節點裏一半以上都被獲得鎖才算活得鎖,隨之而來的要處理超時間和依次放鎖時間延遲的問題等等。
Partitioning (橫向擴展)
多個redis實例,連接起來提供給系統緩存服務,可以隨著數據量增加,進行增加redis實例來進行擴展。文檔中介紹了兩種分割redis實例的辦法,一種是在開始的時候規定死一個redis存的是那些key,還有一種是動態的計算key的hash,然後取模分配到redis中去。
而我們也不得不認識到這種橫向擴展帶來的問題是一些操作上的限制,比如多個操作事務時就無法保證,不同redis實例存儲的集合不能操作並集等操作了,雖然我們可以想其他辦法解決,這也算帶來更大的復雜度。
作者還建議在一開始的時候就考慮切分不同redis實例,可以先在一臺機子上創建很多實例,組建好集群,當需要擴大存儲空間的時候,將一些節點移入到另一個機子上即可,可以實現無停機遷移。不過現實開發中似乎也不需要這樣去做,在數據量不斷上升的過程中是有機會配置出更多的實例的,影響其實不大。
實現方式目前有三種:
1,Redis Cluster 官方實現的推薦方案
2,Twemproxy (Twitter的開源項目)類似代理。
3,客戶端一致性hash jedis上就實現了這個方案,就是在客戶端發起存儲數據時對key進行hash算法固定放入對應redis實例中。早前的Sharded代碼分析:http://www.cnblogs.com/killbug/p/3227851.html
LRU(Least Recently Used)
maxmemory 配置項可以控制redis最大可用的內存。當存儲的內容達到這個最大值時,可以配置不同的策略。
在這個策略配置中可以配置在新增存儲時返回錯誤,或者執行刪除一些key來空出空間給新增的內容。而後者刪除又有一些策略,比如先刪除不常用的,或者隨機刪除等等。
redis據說是沒有實現真正的LRU算法,在實現中為了接近算法,使用了抽樣多個key在這些key中選出最應該刪除的進行刪除。抽樣的數量可以配置。事實上,LRU算法是要求最近使用的被嚴格保留的。而redis實現者認為嚴格實現的話有點消耗內存。
4.0實現了一個LFU( Least Frequently Used),LRU會帶來這樣一個問題:當在決策刪除key的時候,偏向保留剛剛訪問過的key,而如果這些key在很長一段時間都不被使用而只是在刪除決策之前剛剛被訪問了一下而被保留,是不夠科學的。而LFU則是把訪問頻繁的key保留,在緩存的世界裏可能更加有用一些。
說起LRU,Caffeine開源項目,傳說使用現代化算法達到了超高的命中率,號稱世界上最好的緩存庫實現。
文檔:https://redis.io/topics/lru-cache
我們看見在執行INCR a 時出錯,因為a的value是字符串。但是前面set命令卻是提交的。
redis為什麽沒有回退操作呢,在官方文檔中有這樣的解釋:
1,它認為redis 命令出錯只是因為語法有問題,那麽在實際場景中應該在到生產環境前已經被測試到。
2,它還認為redis足夠快,所以有自信不需要什麽會退操作。
競爭場景,使用WATCH來保證互斥操作。WATCH的key會被監控,如果在提交前key內容被改動那麽事務會提交失敗。
官網文檔:https://redis.io/topics/transactions
Distributed locks with Redis 官方有文檔描述了如何實現一個他們認為可靠的分布式鎖,他們稱呼這種實現算法為redlock。也提供了各個語言版本的實現列表,java的話它列舉的是Redisson:https://github.com/redisson/redisson
單個redis 主備場景,推薦的是放key來鎖,value是client的唯一標誌,在獲取到已經有值時判斷是否是自己client的value,類似可重入鎖概念。另外在放的key上加上過期時間,防止client掛掉而導致鎖不能被其他client獲得。問題是master放好key,在同步給slave前掛掉了,slave成為master,卻沒有這個鎖的內容。所以它描述了一個redlock,對應的是多個resid主節點的方式來組建起存儲鎖的結構,核心是在所有節點裏一半以上都被獲得鎖才算活得鎖,隨之而來的要處理超時間和依次放鎖時間延遲的問題等等。
Partitioning (橫向擴展)
多個redis實例,連接起來提供給系統緩存服務,可以隨著數據量增加,進行增加redis實例來進行擴展。文檔中介紹了兩種分割redis實例的辦法,一種是在開始的時候規定死一個redis存的是那些key,還有一種是動態的計算key的hash,然後取模分配到redis中去。
而我們也不得不認識到這種橫向擴展帶來的問題是一些操作上的限制,比如多個操作事務時就無法保證,不同redis實例存儲的集合不能操作並集等操作了,雖然我們可以想其他辦法解決,這也算帶來更大的復雜度。
作者還建議在一開始的時候就考慮切分不同redis實例,可以先在一臺機子上創建很多實例,組建好集群,當需要擴大存儲空間的時候,將一些節點移入到另一個機子上即可,可以實現無停機遷移。不過現實開發中似乎也不需要這樣去做,在數據量不斷上升的過程中是有機會配置出更多的實例的,影響其實不大。
實現方式目前有三種:
1,Redis Cluster 官方實現的推薦方案
2,Twemproxy (Twitter的開源項目)類似代理。
3,客戶端一致性hash jedis上就實現了這個方案,就是在客戶端發起存儲數據時對key進行hash算法固定放入對應redis實例中。早前的Sharded代碼分析:http://www.cnblogs.com/killbug/p/3227851.html
LRU(Least Recently Used)
maxmemory 配置項可以控制redis最大可用的內存。當存儲的內容達到這個最大值時,可以配置不同的策略。
在這個策略配置中可以配置在新增存儲時返回錯誤,或者執行刪除一些key來空出空間給新增的內容。而後者刪除又有一些策略,比如先刪除不常用的,或者隨機刪除等等。
redis據說是沒有實現真正的LRU算法,在實現中為了接近算法,使用了抽樣多個key在這些key中選出最應該刪除的進行刪除。抽樣的數量可以配置。事實上,LRU算法是要求最近使用的被嚴格保留的。而redis實現者認為嚴格實現的話有點消耗內存。
4.0實現了一個LFU( Least Frequently Used),LRU會帶來這樣一個問題:當在決策刪除key的時候,偏向保留剛剛訪問過的key,而如果這些key在很長一段時間都不被使用而只是在刪除決策之前剛剛被訪問了一下而被保留,是不夠科學的。而LFU則是把訪問頻繁的key保留,在緩存的世界裏可能更加有用一些。
說起LRU,Caffeine開源項目,傳說使用現代化算法達到了超高的命中率,號稱世界上最好的緩存庫實現。
文檔:https://redis.io/topics/lru-cache
redis筆記
下載完redis,執行make命令。 然後啟動redis就進src文件夾,執行./redis-server就可以了。
再在文件夾下執行 ./redis-cli 就可以執行redis的命令了。
pipelining
一次請求發送多個命令,以提高性能。我們在使用redis時都是向它發送命令,每次都是需要和redis建立tcp連接,然後發送命令信息,redis執行命令後,客戶端等待著redis的響應。這個我們當然知道,就像訪問db,IO開銷都是消耗資源的大頭,所以redis提供了pipelining功能讓它具有一次傳輸多個命令共同執行的能力。
官網解釋文檔:https://redis.io/topics/pipelining
expire
發布者命令:
而且還支持對channel的匹配方式,用PSUBSCRIBE和PUNSUBSCRIBE命令。
PSUBSCRIBE test* 或PUNSUBSCRIBEtest* 如此我們發現,發布者是匹配模式,而訂閱者是正常模式,或發布者是正常模式,訂閱者是匹配模式,或兩個都是匹配模式。增大了靈活性。
訂閱者命令:
發布者命令:
官網文檔:https://redis.io/topics/pubsub
Transactions
事務中異常場景:
1,在執行MULTI之後EXEC之前,操作redis出現異常的時候,如果收到QUEUED,說明已經在執行列裏了,如果返回error,則需要取消事務。
2,在執行EXEC中出現異常,比如命令本身有錯,那麽事務在執行過程中出錯命令之前的命令將不會會退,而是被提交的。這裏要有特別註意。
如下操作:
我們看見在執行INCR a 時出錯,因為a的value是字符串。但是前面set命令卻是提交的。
redis為什麽沒有回退操作呢,在官方文檔中有這樣的解釋:
1,它認為redis 命令出錯只是因為語法有問題,那麽在實際場景中應該在到生產環境前已經被測試到。
2,它還認為redis足夠快,所以有自信不需要什麽會退操作。
競爭場景,使用WATCH來保證互斥操作。WATCH的key會被監控,如果在提交前key內容被改動那麽事務會提交失敗。
官網文檔:https://redis.io/topics/transactions
Distributed locks with Redis 官方有文檔描述了如何實現一個他們認為可靠的分布式鎖,他們稱呼這種實現算法為redlock。也提供了各個語言版本的實現列表,java的話它列舉的是Redisson:https://github.com/redisson/redisson
單個redis 主備場景,推薦的是放key來鎖,value是client的唯一標誌,在獲取到已經有值時判斷是否是自己client的value,類似可重入鎖概念。另外在放的key上加上過期時間,防止client掛掉而導致鎖不能被其他client獲得。問題是master放好key,在同步給slave前掛掉了,slave成為master,卻沒有這個鎖的內容。所以它描述了一個redlock,對應的是多個resid主節點的方式來組建起存儲鎖的結構,核心是在所有節點裏一半以上都被獲得鎖才算活得鎖,隨之而來的要處理超時間和依次放鎖時間延遲的問題等等。
Partitioning (橫向擴展)
多個redis實例,連接起來提供給系統緩存服務,可以隨著數據量增加,進行增加redis實例來進行擴展。文檔中介紹了兩種分割redis實例的辦法,一種是在開始的時候規定死一個redis存的是那些key,還有一種是動態的計算key的hash,然後取模分配到redis中去。
而我們也不得不認識到這種橫向擴展帶來的問題是一些操作上的限制,比如多個操作事務時就無法保證,不同redis實例存儲的集合不能操作並集等操作了,雖然我們可以想其他辦法解決,這也算帶來更大的復雜度。
作者還建議在一開始的時候就考慮切分不同redis實例,可以先在一臺機子上創建很多實例,組建好集群,當需要擴大存儲空間的時候,將一些節點移入到另一個機子上即可,可以實現無停機遷移。不過現實開發中似乎也不需要這樣去做,在數據量不斷上升的過程中是有機會配置出更多的實例的,影響其實不大。
實現方式目前有三種:
1,Redis Cluster 官方實現的推薦方案
2,Twemproxy (Twitter的開源項目)類似代理。
3,客戶端一致性hash jedis上就實現了這個方案,就是在客戶端發起存儲數據時對key進行hash算法固定放入對應redis實例中。早前的Sharded代碼分析:http://www.cnblogs.com/killbug/p/3227851.html
LRU(Least Recently Used)
maxmemory 配置項可以控制redis最大可用的內存。當存儲的內容達到這個最大值時,可以配置不同的策略。
在這個策略配置中可以配置在新增存儲時返回錯誤,或者執行刪除一些key來空出空間給新增的內容。而後者刪除又有一些策略,比如先刪除不常用的,或者隨機刪除等等。
redis據說是沒有實現真正的LRU算法,在實現中為了接近算法,使用了抽樣多個key在這些key中選出最應該刪除的進行刪除。抽樣的數量可以配置。事實上,LRU算法是要求最近使用的被嚴格保留的。而redis實現者認為嚴格實現的話有點消耗內存。
4.0實現了一個LFU( Least Frequently Used),LRU會帶來這樣一個問題:當在決策刪除key的時候,偏向保留剛剛訪問過的key,而如果這些key在很長一段時間都不被使用而只是在刪除決策之前剛剛被訪問了一下而被保留,是不夠科學的。而LFU則是把訪問頻繁的key保留,在緩存的世界裏可能更加有用一些。
說起LRU,Caffeine開源項目,傳說使用現代化算法達到了超高的命中率,號稱世界上最好的緩存庫實現。
文檔:https://redis.io/topics/lru-cache
redis筆記