
Automatic Generation of Animated GIFs from Video論文研讀及實現
論文地址:Video2GIF: Automatic Generation of Animated GIFs from Video
視頻的結構化分析是視頻理解相關工作的關鍵。雖然本文是生成gif圖,但是其中對場景RankNet思想值得研究。
文中的視頻特征表示也是一個視頻處理值得學習的點。以前做的視頻都是基於單frame,沒有考慮到時空域,文中的參考文獻也值得研讀一下。
以下是對本文的研讀,英語水平有限,有些點不知道用漢語怎麽解釋,直接用的英語應該更容易理解一些。
Abstract
從源視頻當中提取GIF小片段,在大規模數據集檢測中,該方法取得了state-of-the-art
1. Introduction
gif介紹
Animated GIF is an image format that continuously displays multiple frames in a loop, with no sound.
提出了RankNet來處理給一個視頻,得出一個片段排列。
1首先用3D convolutional neural networks去represent每個視頻。
2然後用排名算法訓練去比較一對輸入中那個更適合作為gif圖。然後用排名算法訓練去比較一對輸入中那個更適合作為gif圖。
3為了增強魯棒性,在排序中設計一個robust adaptive Huber loss function
4最後,為了解決用戶生成內容的不同程度的質量問題,我們的損失考慮到流行度量進行編碼社會媒體上的GIF的影響。
數據集
收集了超過100K用戶生成動畫GIF與其對應的來自在線來源的視頻源。有數百個成千上萬的GIF在線可用,許多提供了鏈接到視頻源。
使用這個數據集訓練我們的深層神經網絡比較超過500KGIF和非GIF對。實驗結果表明我們的模型成功地學習了什麽內容是適合的GIF,我們的模型很好地推廣到其他任務,即視頻highlight detection。
三點貢獻
1提出了解決自動生成gif任務的方法。
2提出了Robust Deep RankNet with a novel adaptive Huber loss in the ranking formulation
3收集超過100k的用戶生成的gif及原視頻數據集。
整個流程如圖:
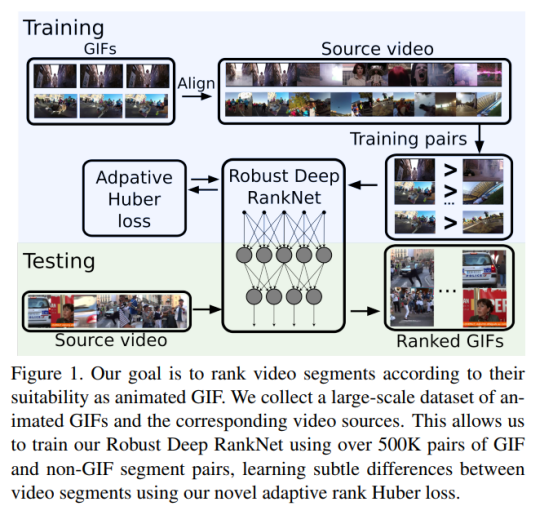
2. Related Work
1美學和趣味性aesthetics and interestingness
趣味性方面 Fu et al. [7] propose anapproach accounting for this, by learning a ranking modeland removing outliers in a joint formulation.
提出通過學習排名模型來解決這個問題並以聯合方式取消異常值。
Khosla等人[20]分析圖像流行度的相關屬性。運用大量的Flickr圖像數據集,他們分析和預測什麽類型的圖像比其他圖像更受歡迎,表面趨勢類似於有趣的趨勢[11]。
在類似的方向是Redi等人的工作[31],分析創造力。然而,不是分析圖像,他們專註於視頻,其長度受限於6秒。
2視頻摘要Video summarization
[37]有詳細的介紹,這裏只討論圖像先驗和監督學習方法。
使用網絡圖像的先驗是基於的觀察特定主題或查詢的網絡圖像通常是規範的主題的視覺示例。這樣就可以進行計算
幀分數作為幀與一組其他幀之間的相似性網頁圖像[21,20,33]。
基於學習的方法,使用監督模型來獲得對於幀[25,8,27]或段[13]評分功能。
3視頻亮點 Video highlights
亮點的定義既是主觀的和上下文相關[37]。舉例人物特寫,體育罰球等。
Sun et al. [35]and Potapov et al. [30]提出了更一般的方法。基於針對特定主題(例如沖浪)的註釋視頻,他們使用機器學習方法中通用特征來預測兩點。為了訓練手工大量標記視頻註釋,進行動作識別。
獲取大型視頻突出顯示數據集很困難。 因此,Yang et al。 [40]提出了一種無監督的方法來尋找亮點。 依靠一個假設事件類別的亮點在短視頻中比非亮點更頻繁地捕獲,他們訓練自動編碼器。
4學習使用深層神經網絡進行排名 Learning to rank with deep neural networks
一些工作使用CNN從排名標簽中學習。損失函數通常用pairs 配對[27,9]或三聯體triplets [38,39,14,23]。 成對方法通常使用一個CNN,而損失是相對定義的輸出。 Gong et al。 學習網絡預測圖像標簽,並要求得分正確的標簽要高於不正確標簽的分數。 Triplet方法,使用Siamese 網絡。特定一個圖像triple (查詢,正,負),一個損失函數需要查詢圖像的學習表示更接近正面的,而不是負面的形象,根據一些度量[38,39,14,23]。
5噪聲標簽的有監督深度學習
幾個以前工作已經成功地從弱勢學習了模型標簽[18,38,27]。 Liu et al。 [27]考慮視頻搜索
場景。 給定Bing的點擊數據,他們學習聯合嵌入查詢文本和視頻縮略圖以查找語義相關的視頻幀。相比之下,[18,38]使用通過自動獲得的標簽訓練神經網絡的方法。Karpathy等訓練用於動作分類的卷積神經網絡視頻。他們的培訓數據來自YouTube通過分析相關的元數據自動標記與視頻。王等人 [38]學習特征表示對於細粒度的圖像排名。基於現有的圖像功能他們生成用於訓練的標簽神經網絡。 這兩種方法都獲得了最先進的技術表現,顯示出強大的弱標簽數據集與深度學習相結合。
3. Video2GIF Dataset
受到近期成功應用與深層學習結合使用的大量弱標簽數據集的啟發,我們收集了具有嘈雜,人為生成註釋的社交媒體數據。
將GIF與源視頻對齊是至關重要的,因為它可以讓我們找到非選擇的片段,這些細分作為訓練的負面樣本。 此外,視頻提供更高的幀速率和更少的壓縮偽影,是獲得高質量特征表征的理想選擇。
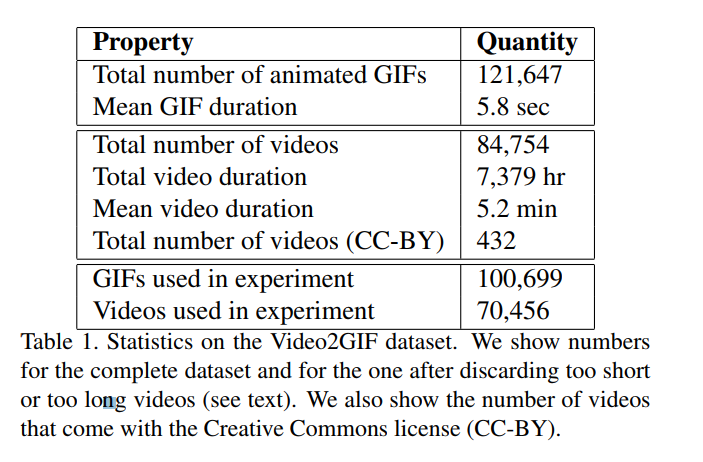
數據庫包含120K animated GIFs and more than80K videos, with a total duration of 7,379 hours.
Alignment對準
我們將GIF與對應的對齊視頻使用幀匹配。為了有效地做到這一點,我們基於 perceptual hash感知散列對每個幀進行編碼discrete cosine transform 離散余弦變換[41]。
感知散列perceptual hash是快速計算的,並且由於其二進制表示,可以是使用漢明距離Hamming distance非常有效地匹配。 我們將GIF幀的集合與其對應視頻的幀進行匹配。 這種方法需要O(nk)距離計算,其中n,k分別是視頻和GIF中的幀數。 由於GIF的長度受限制並且具有較低的幀速率,因此它們通常僅包含幾幀(k <50)。 因此,該方法在計算上保持有效,同時允許對準準確。
因為這個方法想要建立的是數據庫,那麽結果準確度是十分重要的。在之前的工作中,其他方法都是用一個大團塊blocks of 50
frames,比如50幀一起檢測,結果會比較粗糙,並不適用於當前這種情況。
Dataset Analysis.數據集分析
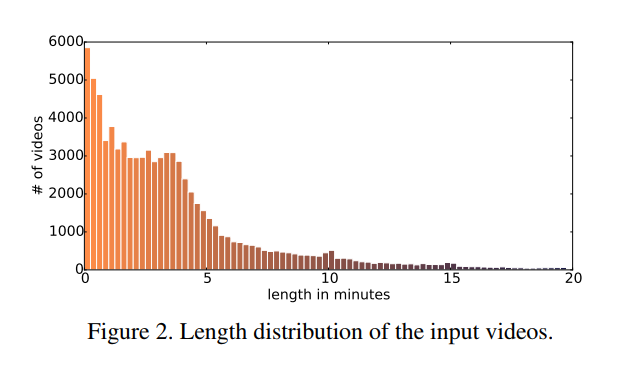
我們分析什麽類型的視頻經常用於創建動畫GIF。 圖3顯示最多我們的數據集中的視頻頻繁標簽,圖4顯示視頻的類別分布。 幾個標簽給了感覺視頻中存在什麽,這可能是潛在的幫助GIF創建,例如 可愛和足球。 其他的不是視覺信息,例如2014或YouTube。 圖2顯示視頻長度的直方圖(中位數:2m51s,平均值:5m12s)。 可以看出,大多數源視頻都很短,中位持續時間少於3分鐘。


Splits.拆分
training and validation sets about 65K and5K videos
test set 357 videos Creative Commons licence 表1顯示了我們使用的數據集的統計信息。
4. Method
本節介紹了我們對Video2GIF任務的方法,在排名配方中引入了一種新穎的適應性Huber損失,使得學習過程對異常值更robust魯棒; 我們稱之為魯棒深度網絡。
4.1. Video Processing
將一段長視頻,切割成小片段 采用boundary detection algorithm Song et al. [33]
結果的重合度達到66%以上,就認定為是正例。沒有任何重合overlap的最為負例。
4.2. Robust Deep RankNet
Architecture overview 結構總覽 圖五所示。
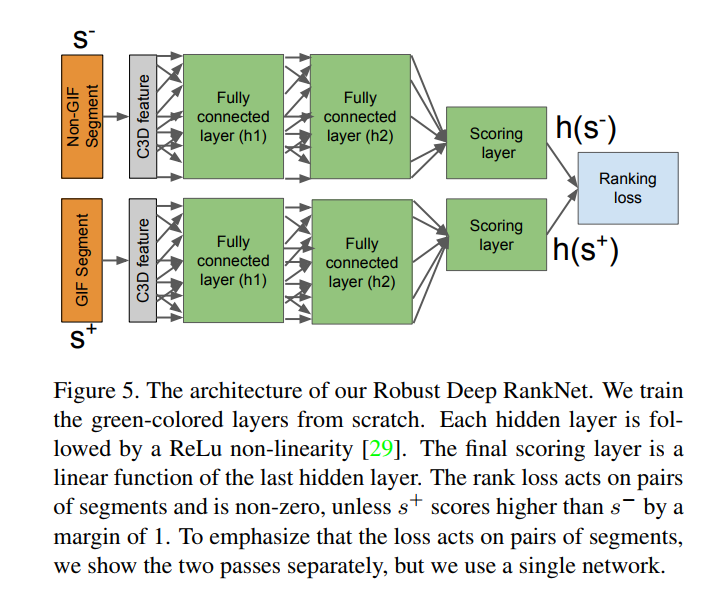
訓練過程中輸入是GIFand non-GIF segments
模型學習一個maps a segment s to its GIF-suitability score h(s)
學習一個函數,通過比較訓練的片段對,然後GIF segment gets a higher score than a nonGIFsegment
測試階段,采用帶個segment輸入,計算GIF-suitability score,然後計算出所有視頻所有片段的得分,產生segments排名列表,選適合的作為動畫gif。
Feature representation 特征表征
動畫GIF包含高度動態視覺內容,特征表示至關重要。捕捉視頻段的空間和時間動態,我們使用在Sport-1M數據集[18]上預先訓練的C3D [36]作為我們的特征提取器。
C3D通過用時空卷積層代替傳統的2D卷積層,將AlexNet [22]的圖像中心網絡架構擴展到視頻域,並已被證明在多個視頻分類任務上表現良好[36]。 以前的方法使用類別具體模型[35,30],我們可以選擇為段表示添加上下文功能。 這些可以被認為是元信息,補充視覺特征。 他們有可能消除細分排名的歧義,並允許模型根據視頻的語義類別進行分數。 特征包括類別標簽,視頻標簽的語義嵌入(在word2vec表示[28]上的意義))和位置特征。 對於位置特征,我們使用片段在視頻中的時間戳,秩和相對位置。
Problem formulation 問題公式
簡單的方式是可以把這個問題歸結為分類問題,但是不能完美的解決這個問題,因為因為那裏對於什麽是好的或壞的細分沒有明確的定義。
所以把這問題確定為排序問題。在數據集D上構建一個排序,是正樣本得分排名大於負樣本。
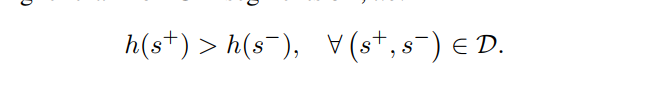
這個公式比較是兩個片段,即使它們來自不同的視頻。 這是有問題的,因為兩個片段的比較僅在視頻的上下文中是有意義的,例如,一個視頻中的GIF片段可能不被選擇為另一個視頻中的GIF。 為了看到這一點,一些視頻包含許多感興趣的部分(例如,編譯),而在其他視頻中,甚至所選擇的部分質量低。 這個概念因此,GIF的適用性在單個視頻的上下文中是非常有意義的。
為了解決這個問題,我們將排名計算公式指定為特定視頻。在同一視頻中gif的正樣本排名大於負樣本。
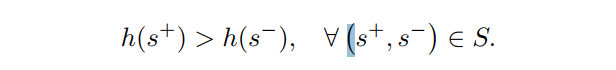
Loss function. 損失函數
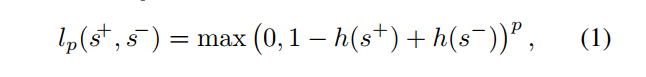
其中p = 1 [17]和p = 2 [35,24]是最受歡迎的選擇。 lp損失強制排名約束,要求一個積極的分數比其負面對手的得分高於1.如果邊界被違反,損失的損失在l1損失的誤差中是線性的,而對於l2的損失 是二次的。 l2損失的一個缺點是相對於l2損失來說,是過度懲罰小額違約。 l2損失沒有這樣的問題,但是它會對邊際違規進行二次懲罰,因此受到異常值的影響更大(見圖6)。
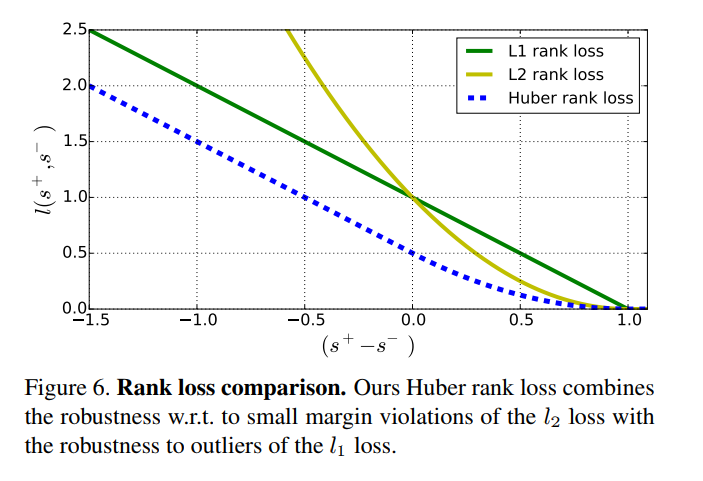
因為數據包含線上制作的,有的質量低,所以提出了robust rank loss,來適應Huber loss formulation。對邊界違反小的樣本給更低的懲罰。公式如2.圖6中定義了三種不同形式的函數。
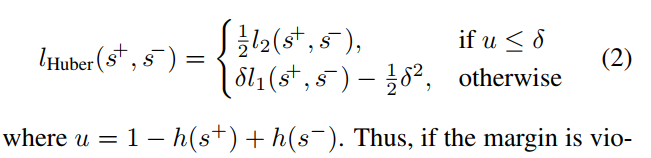
Objective function.目標函數
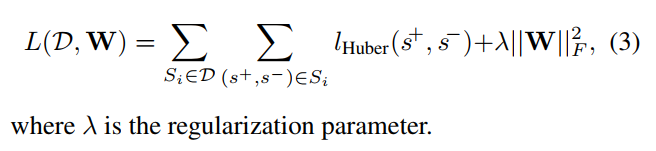
4.3. Implementation Details 實現細節
選擇了2個全連接隱層,每個層後面RELU。第一層512個節點,第二層128個節點。輸出h(s)的最終預測層是一個簡單的單線性單位,預測非標準化標量得分。
網絡共2,327,681個參數。
反向傳播采用[32]采用mini-batch stochastic gradient descent。mini-batches=50 pairs
采用Nesterov’s Accelerated Momentum [2]加速權重更新。
momentum is set to 0.9
weight decay λ =0.001
learning rate = 0.001 10個epoch減少一次
應用dropout [34] regularization input =0.8 after the first hidden layer=0.25
用500k個訓練集對,每個視頻中所有的正樣本和視頻中隨機抽取4個負樣本並把負樣本結合。對於具有固定δ的Huber損失,我們根據驗證集的性能設置δ= 1.5。 對於自適應Huber損失,我們設置δ= 1.5 + p,其中p是在[20]中提出的歸一化視圖計數。為了進一步減少我們的模型的方差,我們使用模型平均,其中我們從不同的初始化訓練多個模型, 平均預測分數。 模型使用Theano [3]與Lasagne [6]進行實施。
5. Experiments 實驗
Evaluation metrics.
在video highlight detection中流行的評價指標是mean Average Precision(mAP)和p
因為上述方法對視頻長度敏感,本文使用的normalized version of MSD。
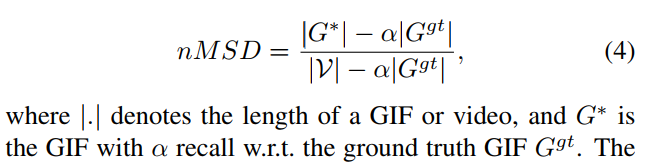
5.1. Compared Methods
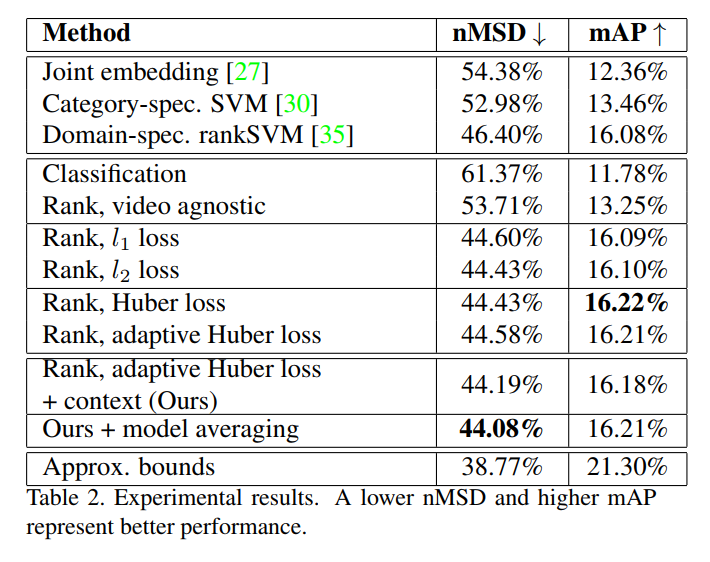
5.2. Results and Discussions

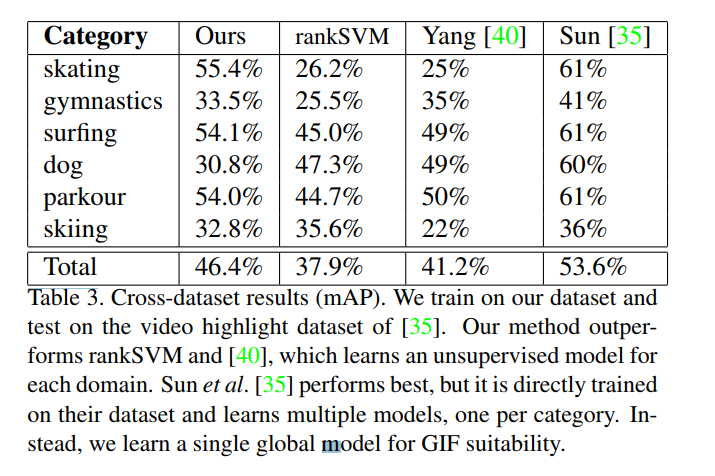
5.3. Cross Dataset Performance
6. Conclusion 結論
我們介紹了從視頻自動生成動畫GIF的問題,並提出了一個強大的Deep RankNet,它預測了適合的GIF視頻片段。
我們的方法利用新的自適應Huber等級丟失來處理嘈雜的網絡數據,該優點具有對異常值的魯棒,並能夠將內容質量的概念直接編碼到損失中。
在我們新的動畫GIF數據集我們展示了我們的方法成功地學習了細微差異的分級,優於現有的方法。
此外,它概括了很好的亮點檢測。我們的新穎的Video2GIF任務,以及我們的新的大型數據集,為未來的研究開辟了自動GIF創建方向。
例如,可以應用更復雜的語言模型來利用視頻元數據,因為並不是所有的標簽都是信息豐富的。因此,我們認為學習專門用於視頻標簽的嵌入可以改善語境模型(我認為就是利用視頻元數據可以向NLP中word2vec那樣來處理)。
雖然這項工作集中在獲得有意義的GIF排名,但我們只考慮了單一片段。由於一些GIF範圍超過多個鏡頭,因此看看何時組合片段甚至連合分割和選擇也將是有趣的。
References
Automatic Generation of Animated GIFs from Video論文研讀及實現