
最優化方法與機器學習工具集
摘要:
1.最小二乘法
2.梯度下降法
3.最大(對數)似然估計(MLE)
4.最大後驗估計(MAP)
5.期望最大化算法(EM)
6.牛頓法
7.擬牛頓叠代(BFGS)
8.限制內存-擬牛頓叠代(L-BFGS)
9.深度學習中的梯度優化算法
10.各種最優化方法比較
擬牛頓法和牛頓法區別,哪個收斂快?
1.最小二乘法
註:這裏假定你了解向量的求導公式,並且知道正態分布和中心極限定律(不知道的可以去數學知識索引翻翻)
(線性)最小二乘回歸解法:

損失函數:平方損失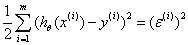 ,這裏的誤差可能是多種獨立因素加和造成的,所以我們假定其符合均值為0的高斯分布,繼而可以推出平方損失。參考Andrew Ng機器學習公開課筆記 -- 線性回歸和梯度下降的Probabilistic interpretation,概率解釋
,這裏的誤差可能是多種獨立因素加和造成的,所以我們假定其符合均值為0的高斯分布,繼而可以推出平方損失。參考Andrew Ng機器學習公開課筆記 -- 線性回歸和梯度下降的Probabilistic interpretation,概率解釋
適用場合:
優缺點:維數過高時,求逆效率過低
2.梯度下降法
這是一種叠代方法,先隨意選取初始θ,然後不斷的以梯度的方向修正θ,最終使J(θ)收斂到最小,當然梯度下降找到的最優是局部最優,也就是說選取不同的初值,可能會找到不同的局部最優點
常見的3終梯度下降算法:
1.批梯度下降(BGD)算法:

2.隨機梯度下降(SGD)算法:

3.mini-batch隨機梯度下降
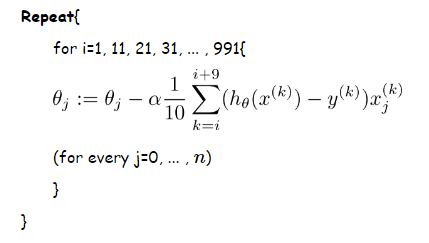
同樣可以參照Andrew Ng機器學習公開課筆記 -- 線性回歸和梯度下降的梯度下降(gradient descent)部分
3.最大(對數)似然估計(MLE)
參照:數理統計與參數估計雜記
4.最大後驗估計(MAP)
引入了先驗分布對參數做規範化,其參數估計是對貝葉斯後驗概率求極值,而預測過程和最大似然估計一樣
5.期望最大化算法(EM)
K-Means聚類和EM算法復習總結
6.牛頓法:
在非線性優化問題上。牛頓法的基本思想是:在現有極小點估計值的附近對f(x)做二階泰勒展開(如下圖公式),進而找到極小點的下一個估計值,
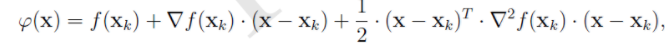


求駐點,並假設海森矩陣可逆,則得到如下叠代公式:
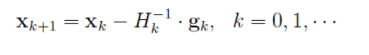
綜合以上,得到牛頓發的算法流程如下:

7.擬牛頓叠代(BFGS)
同時利用梯度和二階導數做優化,相當於在當前點處進行二階的泰勒展開,並找到二次曲面的極小值點。
叠代公式為:
實際的優化問題中很難保證每一點的Hessian矩陣(二階導數對應的矩陣)都正定(可逆),而擬牛頓法構造了一個不太精確,但是可以保證正定的矩陣
Hessian矩陣的逆的更新公式是:
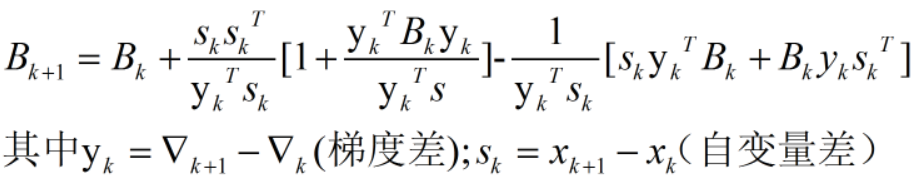
當學習速率滿足Wolfe條件時,可以保證找到比現有函數更優的一個點;
Wolfe條件:
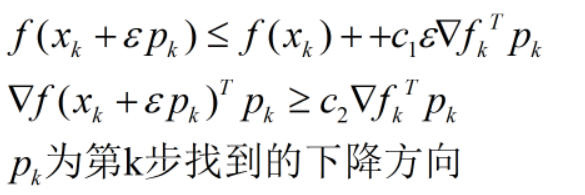
8.限制內存-擬牛頓叠代(L-BFGS)
它對BFGS算法進行了近似,其基本思想是:不在存儲完整的矩陣D,而是存儲計算過程中的向量s,y,需要矩陣D時,利用向量系列s,y的計算來代替。而且向量序列也不是所有的都存,
而是固定存最新的m個(參數m可由用戶根據自己機器的內存自行指定)。每次計算D時,只利用最新的m個s,y.顯然這樣一來,我們將存儲有原來的O(N*N)降到了O(mN)

9.深度學習中的梯度優化算法
算法介紹:梯度下降優化算法綜述
為什麽adagrad適合處理稀疏梯度?它能夠對每個參數自適應不同的學習速率,對稀疏特征,得到大的學習更新,對非稀疏特征,得到較小的學習更新,因此該優化算法適合處理稀疏特征數據。
10.各種最優化方法比較
1.牛頓法和擬牛頓法區別,哪個收斂快?
牛頓法:若函數的二次性態較強,牛頓法的收斂速度是很快的。但是牛頓法由於叠代公式中沒有步長因子,而是定長叠代,對於非二次型目標函數,有時牛頓法不能保證函數值穩定地下降,在嚴重的情況下甚至不能收斂;
擬牛頓法:使用"偽逆"矩陣代替海森矩陣,所以無需計算二階偏導,而且可以保證矩陣正定。通過一維搜索確定步長。參考鏈接
2.SGD,AdaGrad,Adam的區別
SGD:使用負梯度更新權重
AdaDelta和AdaGrad:1.自適應,省去了人工設定學習率的過程;2.只用到一階信息,計算開銷小;3.超參數不敏感性,其公式中額外增加的參數的選擇對求解結果沒有很大影響;4.魯棒性;5.按維度分開計算學習率;
Adam:對於AdaGrad的泛化,其加入了:自適應時刻估計變量mt, μt
最優化方法與機器學習工具集